[논문리뷰] Trust Your Critic: Robust Reward Modeling and Reinforcement Learning for Faithful Image Editing and Generation
링크: 논문 PDF로 바로 열기
저자: Xiangyu Zhao, Peiyuan Zhang, et al.
1. Key Terms & Definitions
- RL (Reinforcement Learning) : Image editing 및 text-to-image (T2I) generation task의 성능을 향상시키기 위해 reward model (critic)의 피드백을 기반으로 모델을 최적화하는 학습 패러다임.
- Reward Model (Critic) : RL 과정에서 생성되거나 편집된 이미지의 품질을 평가하고, 이를 통해 에이전트에게 최적화 신호를 제공하는 모델.
- FIRM (Faithful Image Reward Modeling) : 이미지 생성 및 편집을 위한 robust reward model을 개발하는 포괄적인 프레임워크.
- FIRM-Edit Pipeline : 이미지 편집 평가를 위한 high-quality VQA dataset을 생성하는 "difference-first" 방법론. MLLM이 원본과 편집된 이미지 간의 차이를 분석한 후, 이 차이 설명을 바탕으로 편집 실행(Execution) 및 일관성(Consistency) 점수를 할당한다.
- FIRM-Gen Pipeline : T2I generation 평가를 위한 "plan-then-score" 방법론. LLM이 user prompt로부터 scoring checklist를 생성하고, MLLM이 이를 바탕으로 step-by-step으로 instruction following 점수를 평가한다.
- CME (Consistency-Modulated Execution) : 이미지 편집을 위한 reward formulation으로, Execution 점수가 Consistency 점수를 조절하는 multiplicative coupling 방식을 사용하여 reward hacking을 방지하고 Execution을 필수 조건으로 만든다.
- QMA (Quality-Modulated Alignment) : T2I generation을 위한 reward formulation으로, Instruction Following 점수가 Image Quality 점수를 조절하는 방식을 사용하여 단순한 reward hacking을 방지하고 시각적 Fidelity를 강조한다.
2. Motivation & Problem Statement
Diffusion models과 autoregressive models의 발전으로 T2I generation 및 image editing task에서 상당한 진전이 있었으나, 이러한 모델들의 성능 향상을 위한 RL 기반 접근 방식은 reward model 의 신뢰성 문제에 직면해 있습니다. 기존 reward model 은 종종 hallucinations 을 일으키고 noisy한 점수를 할당하여, 최적화 프로세스를 잘못 유도하는 문제가 있습니다. 특히, 기존 Multimodal Large Language Models (MLLMs) 는 fine-grained image editing 및 generation task에서 zero-shot reward model 로 활용될 때, hallucinations , object neglect , 그리고 spatial reasoning 부족으로 인해 불합리하고 일관성 없는 reward scores 를 부여하는 경향이 있었습니다. 이는 RL-driven alignment 과정에서 생성되거나 편집된 이미지의 품질이 critics 의 정확성과 신뢰성에 의해 근본적으로 제약받는다는 것을 의미합니다. 이러한 문제들은 RL 의 효율적인 적용을 저해하며, robust 하고 task-specific 한 reward model 개발의 필요성을 제기합니다. 본 연구는 이러한 critical bottleneck 을 해결하고 trustworthy critics 를 통해 faithful image generation 및 editing 을 가능하게 하는 FIRM framework 를 제안합니다.
3. Method & Key Results
본 연구는 FIRM (Faithful Image Reward Modeling) 이라는 포괄적인 프레임워크를 제안하며, robust task-specific reward models 를 훈련하기 위한 두 가지 전문화된 데이터 curation pipeline 을 소개합니다: FIRM-Edit 및 FIRM-Gen . FIRM-Edit pipeline 은 "difference-first" 방법론을 채택하여 MLLM 이 원본 및 편집된 이미지 간의 visual differences 를 정확히 캡션(caption)하도록 합니다. 이 textual difference description 과 편집 지시를 다른 MLLM 에 입력하여 Execution 및 Consistency 점수를 할당하며, 이는 인간 판단과 더 잘 일치합니다
 Figure 3: Overview of the FIRM data curation pipelines. (Top) The FIRM-Edit pipeline follows a novel "difference-first" design. (Bottom) The FIRM-Gen pipeline adopts a "plan-then-score" paradigm to significantly enhance scoring accuracy.
Figure 3: Overview of the FIRM data curation pipelines. (Top) The FIRM-Edit pipeline follows a novel "difference-first" design. (Bottom) The FIRM-Gen pipeline adopts a "plan-then-score" paradigm to significantly enhance scoring accuracy.
. FIRM-Gen pipeline 은 "plan-then-score" 방법론을 사용합니다. 먼저 LLM (Qwen3-32B) 이 T2I prompt로부터 detailed scoring checklist 를 생성하고, 이후 MLLM (Qwen3-VL-235B-A22B) 이 이 계획에 따라 step-by-step inspection 을 수행하여 fine-grained 하고 interpretable 한 instruction following 점수를 부여합니다 [Figure 3].
이 pipeline 들을 통해 FIRM-Edit-370K 및 FIRM-Gen-293K 라는 고품질 reward dataset 이 구축되었고, 이를 기반으로 FIRM-Edit-8B 및 FIRM-Gen-8B reward model 이 훈련되었습니다. FIRM-Bench 라는 새로운 human-annotated benchmark 에서 FIRM-Edit-8B 는 Execution MAE 0.53 , Consistency MAE 0.73 , Overall MAE 0.62 를 달성하여 GPT-5 및 다른 모든 open-source baseline 을 outperform 했습니다
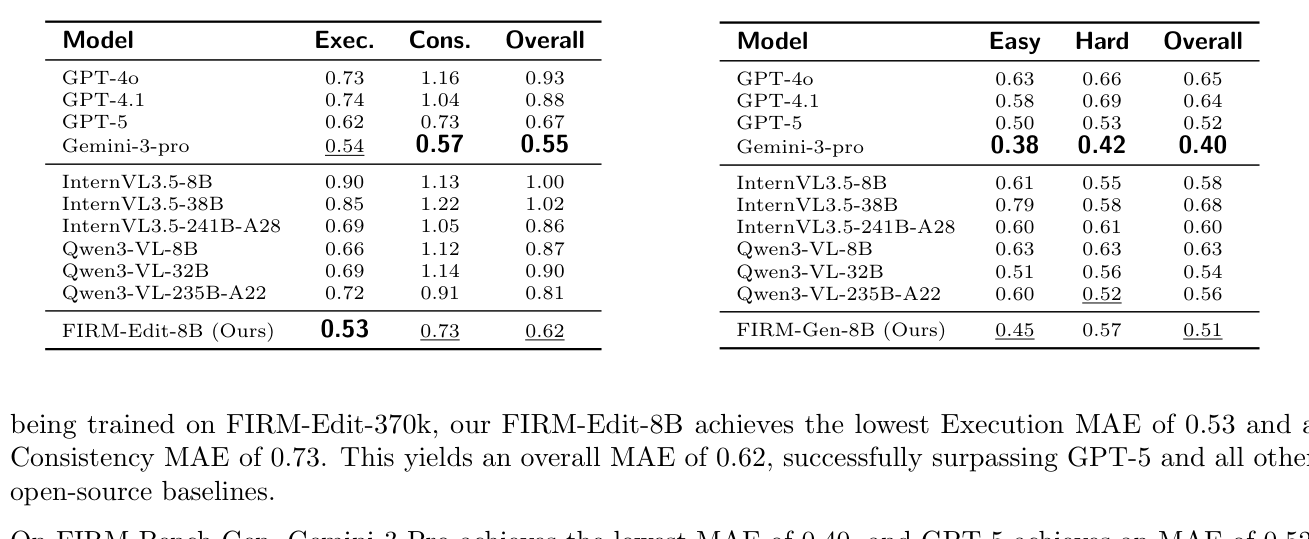 Table 1: Results on FIRM-Bench-Edit.
Table 1: Results on FIRM-Bench-Edit.
. FIRM-Gen-8B 는 FIRM-Bench-Gen 에서 MAE 0.51 을 달성하며 GPT-5 와 평가된 모든 open-source model 을 능가하는 highly competitive 성능을 보여주었습니다 [Table 2].
또한, RL 프로세스에 이 reward model 을 통합하기 위해 새로운 "Base-and-Bonus" reward strategy 를 제안합니다. 이미지 편집을 위해 CME (Consistency-Modulated Execution) 를 사용하며, Execution * (w1 + w2 * Consistency)형식으로 reward hacking 을 방지하고Execution을 필수로 만듭니다. T2I generation을 위해서는 QMA (Quality-Modulated Alignment)를 도입하여 InsFollowing * (w1 + w2 * Quality)형식으로 instruction following 과image quality 간의 균형을 맞춥니다. RL 실험에서, FIRM-Qwen-Edit model은 GEditBench에서 SOTA score 7.84를, ImgEdit에서 4.42를 달성하며 기존 base model 및 Qwen3-VL model 기반 counterpart들을 outperform했습니다
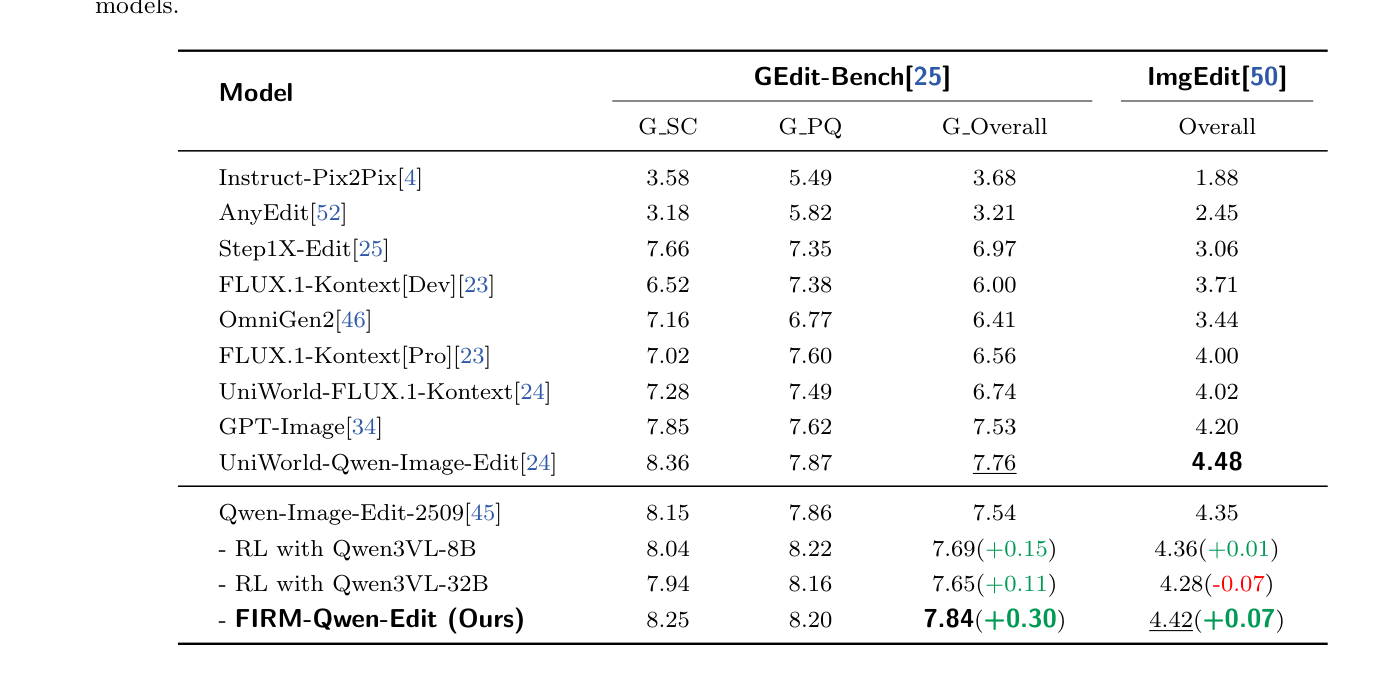 Table 3: Performance comparison on GEdit-Bench and ImgEdit. Guided by FIRM-Edit-8B during RL process, the resulting FIRM-Qwen-Edit substantially outperforms the base model as well as counterparts trained with Qwen3-VL models.
Table 3: Performance comparison on GEdit-Bench and ImgEdit. Guided by FIRM-Edit-8B during RL process, the resulting FIRM-Qwen-Edit substantially outperforms the base model as well as counterparts trained with Qwen3-VL models.
. FIRM-SD3.5 model은 GenEval에서 0.77, DPGBench에서 87.16, TIIF에서 77.12, UniGenBench-Short/Long에서 각각 69.56/76.22의 점수를 기록하며 BAGEL 및 OmniGen2와 같은 heavily resourced model을 능가했습니다 [Table 4]. Ablation study 결과, CME는 reward hacking 없이 일관되고 robust하게 reward signal을 증가시키는 독특한 efficacy를 보여주었습니다 [Table 5].
4. Conclusion & Impact
본 연구는 faithful image editing 및 generation을 위한 robust reward modeling 및 reinforcement learning의 comprehensive framework인 FIRM을 성공적으로 제시합니다. 제안된 framework는 tailored data curation pipelines, high-quality reward datasets, rigorous evaluation benchmark, 그리고 novel reward formulations를 포함하는 RL ecosystem 전체를 포괄합니다. 이러한 end-to-end pipeline을 통해, 본 연구의 reward models는 RL process를 효과적으로 안내하여 downstream generative tasks에서 substantial performance improvements를 달성했습니다. FIRM은 기존 일반 모델들이 겪는 hallucinations 문제를 완화하며, fidelity 및 instruction adherence에 대한 새로운 standard를 확립했습니다. 이는 generative models의 reward-guided alignment에 대한 미래 연구에 중요한 영감을 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Uniworld-V2: Reinforce Image Editing with Diffusion Negative-aware Finetuning and MLLM Implicit Feedback
- [논문리뷰] Skill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
- [논문리뷰] Edit-Compass & EditReward-Compass: A Unified Benchmark for Image Editing and Reward Modeling
- [논문리뷰] Enhancing Spatial Understanding in Image Generation via Reward Modeling
- [논문리뷰] FireRed-Image-Edit-1.0 Techinical Report
Review 의 다른글
- 이전글 [논문리뷰] TeamHOI: Learning a Unified Policy for Cooperative Human-Object Interactions with Any Team Size
- 현재글 : [논문리뷰] Trust Your Critic: Robust Reward Modeling and Reinforcement Learning for Faithful Image Editing and Generation
- 다음글 [논문리뷰] Understanding by Reconstruction: Reversing the Software Development Process for LLM Pretraining
댓글