[논문리뷰] TeamHOI: Learning a Unified Policy for Cooperative Human-Object Interactions with Any Team Size
링크: 논문 PDF로 바로 열기
저자: Stefan Lionar, Gim Hee Lee, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Human-Object Interaction (HOI) : 인간형 에이전트가 물리적 환경 내의 객체와 상호작용하는 모든 활동을 통칭하며, 본 논문에서는 특히 협동 작업을 지칭합니다.
- Adversarial Motion Prior (AMP) : 물리 기반 시뮬레이션에서 생성된 모션이 현실적이도록 참조 모션 데이터에 정규화하는 Reinforcement Learning (RL) 프레임워크입니다.
- Transformer-based Policy Network : Self-attention 및 Cross-attention 레이어로 구성된 정책 네트워크 아키텍처로, Teammate Tokens 를 활용하여 가변적인 팀 사이즈에 걸쳐 스케일러블한(Scalable) 에이전트 간의 조정을 가능하게 합니다.
- Masked AMP : 기존 AMP 전략을 확장한 것으로, 객체와 상호작용하는 신체 부위(예: 손과 팔뚝)를 마스킹하여 학습 과정에서 단일 인간 참조 모션으로부터 더 다양하고 물리적으로 타당한 HOI 동작을 생성하도록 합니다.
- Decentralized Policy : 각 에이전트가 로컬 관측을 기반으로 독립적으로 작동하지만, 단일 공유 정책(Single Shared Policy)을 통해 다른 팀원들과 조정을 수행하는 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
물리 기반 인간형 제어는 사실적이고 고성능의 단일 에이전트(Single-agent) 행동을 가능하게 하는 데 상당한 발전을 이루었지만, 이를 협동적인 Human-Object Interaction (HOI) 으로 확장하는 것은 여전히 어려운 과제입니다. 기존의 물리 기반 인간형 모션 프레임워크는 주로 고정된(Fixed-size) MLP 정책에 의존하여 제어 동작을 생성하기 때문에 Scalability 가 제한적이며, 팀 사이즈가 고정된(Fixed Team Size) 경우에만 적용 가능했습니다. 또한, Adversarial Motion Prior (AMP) 와 같은 모션 리얼리즘(Motion Realism) 기법은 주로 단일 인간 데모(Single-human Demonstration) 데이터에 의존하여 협동 HOI 데이터의 Diversity 가 부족하다는 한계가 있었습니다. 이러한 제약은 에이전트 간의 명시적인 통신 없이 공유된 객체 동역학에만 의존하는 방식의 한계와 함께, 실제 인간 협동에서 나타나는 적응적이고 유연한 조정을 반영하기 어렵다는 문제를 야기합니다. 이에 본 연구는 다양한 팀 사이즈와 그에 상응하는 조정 요구 사항에 걸쳐 일반화할 수 있는 통합된 Decentralized Policy 를 학습하는 프레임워크인 TeamHOI 를 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 어떤 팀 사이즈에도 대응하는 협동 HOI 를 위한 통합된 Decentralized Policy 를 학습하는 TeamHOI 프레임워크를 제안합니다. 제안된 방법론의 핵심은 Transformer-based Policy Network 로, 관측 에이전트의 로컬 관측과 팀원들의 상태를 인코딩하는 Teammate Tokens 를 통해 가변적인 팀 사이즈에 걸쳐 Scalable Coordination 을 가능하게 합니다
 Figure 2: Overview of TeamHOI framework. A transformer-based policy network enables coordination between the observing agent (green humanoid) and its teammates (grey humanoids) through alternating self- and cross-attention layers. By training across diverse team-size environments, the framework learns a unified policy that works across different team configurations. To maintain motion realism and enhance skill diversity, a masked AMP strategy blends full-body and masked discriminators based on object interaction.
Figure 2: Overview of TeamHOI framework. A transformer-based policy network enables coordination between the observing agent (green humanoid) and its teammates (grey humanoids) through alternating self- and cross-attention layers. By training across diverse team-size environments, the framework learns a unified policy that works across different team configurations. To maintain motion realism and enhance skill diversity, a masked AMP strategy blends full-body and masked discriminators based on object interaction.
. 이 정책은 다양한 팀 사이즈 구성으로 인스턴스화된 환경에서 훈련되어 다양한 상호작용 동역학에 노출됩니다. 또한, Masked AMP 전략을 도입하여 단일 인간 참조 모션의 객체 상호작용 신체 부위를 마스킹함으로써 기존 AMP 의 데이터 다양성 한계를 극복하고, 마스킹된 영역은 태스크 보상(Task Reward)을 통해 다양하고 물리적으로 타당한 협동 행동을 유도합니다 [Figure 2, Figure 5]. 안정적인 운반을 위해 Team-size- and Shape-agnostic Formation Reward 를 설계하여 에이전트들이 객체의 주축을 따라 안정적인 자세를 형성하도록 안내합니다 [Figure 3, Figure 6].
TeamHOI 는 2명에서 8명의 인간형 에이전트가 다양한 객체 형상(Square, Rectangular, Round)의 테이블을 운반하는 협동 태스크에서 평가되었습니다. 핵심 정량적 결과는 다음과 같습니다.
- Success Rate (SR) 및 Cooperative Time Ratio (tcoop) : TeamHOI 는 2, 4, 8명의 에이전트 설정에서 각각 99.1% , 99.2% , 97.5% 의 높은 SR 을 달성했으며, tcoop 또한 95.2% , 96.1% , 90.1% 로 일관되게 높은 협동 수준을 보였습니다. 이는 CooHOI* 베이스라인이 8명 에이전트에서 SR 42.2% , tcoop 81.6% 로 성능이 크게 저하되는 것과 대조적입니다
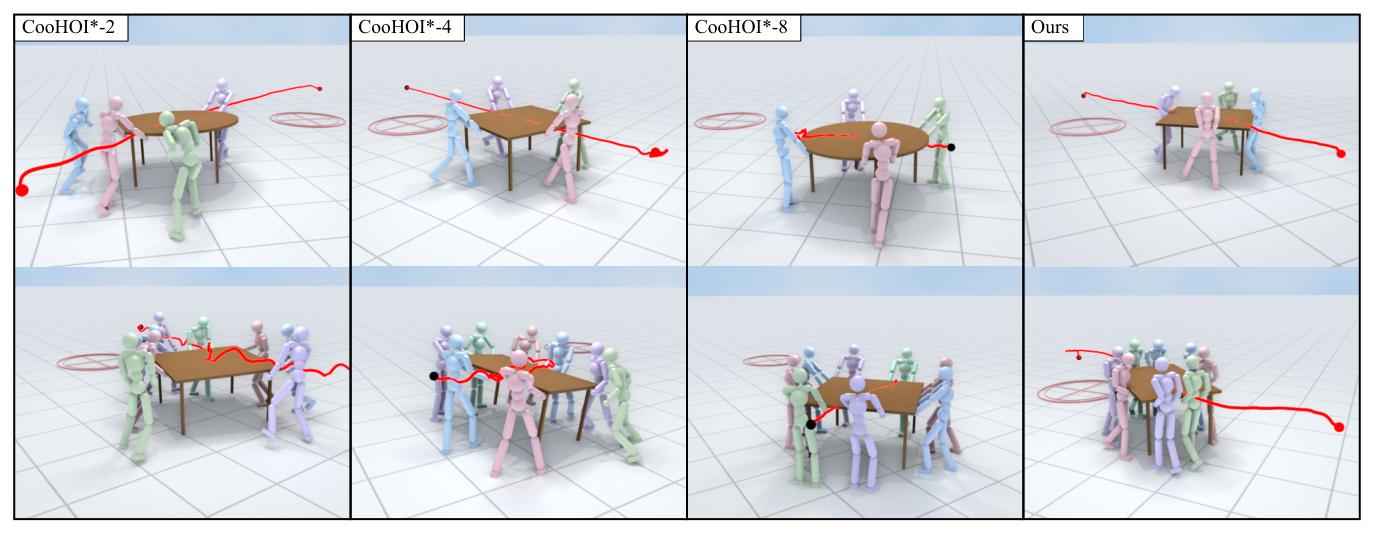 Table 1: Quantitative comparison across team sizes (2A, 4A, 8A). Our method achieves consistently high success rates, collective cooperation, and motion smoothness across all settings using a single unified policy. Unlike CooHOI baselines, where agent formations are pre-defined, our agents must infer cooperation to establish stable formations autonomously, making the coordination requirement more demanding. Under the heavy-load setting (5x table weights), only our method demonstrates effective cooperation among eight agents. All results are averaged over 10,000 simulation episodes.*
Table 1: Quantitative comparison across team sizes (2A, 4A, 8A). Our method achieves consistently high success rates, collective cooperation, and motion smoothness across all settings using a single unified policy. Unlike CooHOI baselines, where agent formations are pre-defined, our agents must infer cooperation to establish stable formations autonomously, making the coordination requirement more demanding. Under the heavy-load setting (5x table weights), only our method demonstrates effective cooperation among eight agents. All results are averaged over 10,000 simulation episodes.*
.
- Mean Absolute Jerk (|J|) : TeamHOI 는 2명부터 8명 에이전트까지 51.0 에서 34.2 로 낮아지는 Mean Absolute Jerk 를 기록하여, 팀 사이즈가 커질수록 더 부드러운 운반 동작을 보여주었습니다. 이는 베이스라인 대비 탁월한 모션 스무스니스(Motion Smoothness)를 나타냅니다 [Table 1].
- Heavy-load Setting (5x Table Weight) : 5배 무거운 테이블 운반 환경에서 TeamHOI 는 8명 에이전트에서 81.1% 의 높은 SR 을 달성하며 강력한 협동 능력을 입증했습니다. 이는 같은 조건에서 CooHOI*-8이 4.1%의 저조한 SR을 보인 것과 크게 대비됩니다 [Table 1].
- Zero-shot Generalization: 학습 시 접하지 않은 테이블 형상 및 더 큰 팀 사이즈(12, 16 에이전트)에 대해서도 강력한 일반화 성능을 보여주었습니다 [Table 4].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Scalable한 협동 Human-Object Interaction (HOI)을 위한 통합 Decentralized Policy를 학습하는 TeamHOI 프레임워크를 성공적으로 제시했습니다. Transformer-based Policy Network와 Teammate Tokens의 도입은 가변적인 팀 사이즈에 걸쳐 효과적인 에이전트 간 조정을 가능하게 하며, Masked AMP 전략은 제한된 단일 인간 참조 데이터로부터도 다양하고 물리적으로 타당한 협동 행동을 이끌어냅니다. 또한, Team-size- and Shape-agnostic Formation Reward는 협동 운반 중 안정적이고 자연스러운 대형을 촉진합니다. TeamHOI는 도전적인 테이블 운반 태스크에서 광범위한 다중 에이전트 설정에 걸쳐 일관되고 안정적이며 다양한 협동 행동을 성공적으로 수행함으로써 높은 Success Rate를 달성했습니다. 이 연구는 Scalable한 물리 기반 다중 인간형 제어의 기반을 마련하며, 구현 지능(Embodied Intelligence) 및 가상 환경에서의 다중 캐릭터 애니메이션 분야에 새로운 기회를 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- [논문리뷰] AutoScientists: Self-Organizing Agent Teams for Long-Running Scientific Experimentation
- [논문리뷰] The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
- [논문리뷰] A Survey on LLM-based Conversational User Simulation
- [논문리뷰] Qualixar OS: A Universal Operating System for AI Agent Orchestration
Review 의 다른글
- 이전글 [논문리뷰] Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
- 현재글 : [논문리뷰] TeamHOI: Learning a Unified Policy for Cooperative Human-Object Interactions with Any Team Size
- 다음글 [논문리뷰] Trust Your Critic: Robust Reward Modeling and Reinforcement Learning for Faithful Image Editing and Generation
댓글