[논문리뷰] Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
링크: 논문 PDF로 바로 열기
저자: Łukasz Borchmann, Ryan Othniel Kearns, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MADQA (Multimodal Agentic Document QA) : 다양한 PDF 문서 컬렉션에 대한 멀티모달 Agentic 시스템의 Multi-step 정보 검색 및 추론 능력을 평가하기 위해 설계된 새로운 벤치마크.
- Agentic System : 복잡한 문서 작업 흐름을 자동화하기 위해 계획 (sub-queries 분해), 탐색 (중간 결과 반복), 집계 (부분 답변 합성)와 같은 반복적인 Retrieval 및 Reasoning 과정을 수행하는 시스템.
- Classical Test Theory (CTT) : MADQA 벤치마크 설계에 사용된 심리 측정 프레임워크로, Agentic 능력 수준에 따른 차별화 능력을 극대화하여 Test set이 전체 벤치마크와 강한 Rank correlation을 유지하고, 해결하기 어려운 항목(Hard items)을 포함하도록 합니다.
- Kuiper Statistic (K) : Effort (예: Tool call, Search iteration 횟수)와 Accuracy 간의 의존성을 정량화하는 Metric으로, Effort spectrum 전반에 걸쳐 Accuracy의 누적 편차(Cumulative deviation) 범위를 측정하여 Calibration 품질을 평가합니다. K 값이 낮을수록 Calibration이 우수함을 의미합니다.
- Oracle Gap : 현재 모델이 Retrieval bottleneck으로 인해 해결하지 못하는 벤치마크 문제의 비율로, 이상적인 Retrieval 환경에서 달성할 수 있는 성능과의 차이를 나타냅니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Multimodal Agent는 복잡한 문서 기반 워크플로우를 자동화하는 유망한 방향을 제시하지만, 이러한 Agent가 진정한 Strategic Reasoning 을 보여주는지, 아니면 단지 Stochastic Trial-and-error Search 에 의존하는지에 대한 근본적인 의문이 존재했습니다. 기존 벤치마크들은 이러한 Agentic 역량을 충분히 평가하는 데 한계가 있었습니다. 예를 들어, Researchy Questions [Rosset et al., 2025]나 BRIGHT [Su et al., 2025]와 같은 Agent-centric 벤치마크는 복잡한 "Agentic Research"를 다루지만 HTML이나 Plain text에 의존하여 실제 문서에 필요한 Visual comprehension을 무시합니다. 반면 FinRAGBench-V [Zhao et al., 2025]나 ViDoSeek [Wang et al., 2025]는 Visual-rich PDF를 다루지만, 금융과 같은 좁은 Vertical에 국한되거나 Iterative planning 및 Refinement를 포착하지 못하는 Single-step Metric을 사용합니다.
또한, ViDoRE [Faysse et al., 2025]나 DOUBLE-BENCH [Shen et al., 2025]와 같은 General-purpose 벤치마크는 MLLM이 생성한 Q&A에 의존하거나 기존 데이터셋의 문서를 재활용하여 데이터 오염 및 모델 편향의 위험이 높았습니다. 이러한 한계점들을 극복하고, 복잡한 Multi-stage 정보 검색 및 Reasoning Task를 Multi-modal Large Language Model (MLLM) 기반 Agentic 시스템으로 처리하는 능력을 평가하기 위한 Rigorous하고 Fully human-authored 벤치마크의 필요성이 커졌습니다.
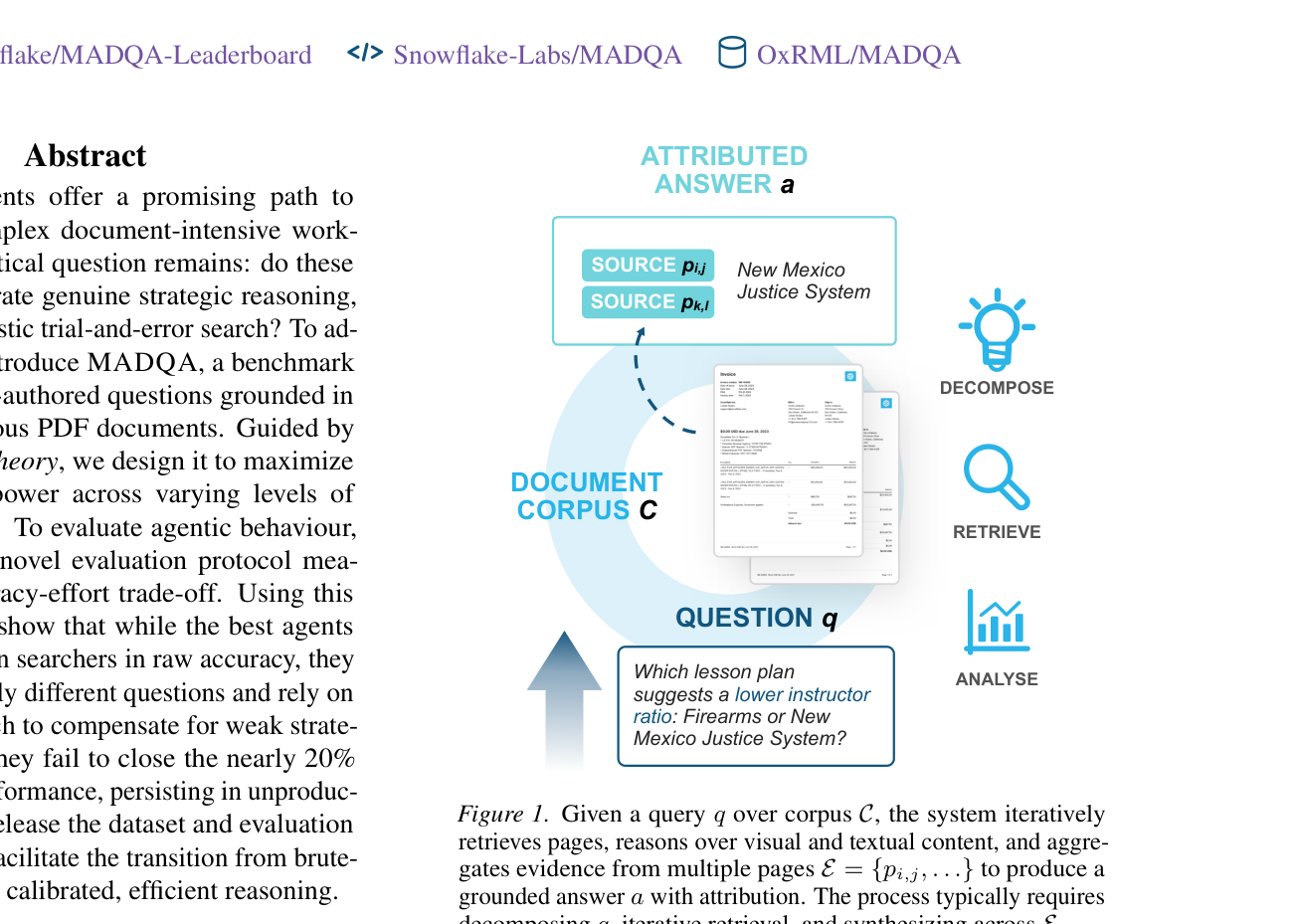 Figure 1: Given a query q over corpus C, the system iteratively retrieves pages, reasons over visual and textual content, and aggregates evidence from multiple pages E = {pi,j,...} to produce a grounded answer a with attribution. The process typically requires decomposing q, iterative retrieval, and synthesizing across E.
Figure 1: Given a query q over corpus C, the system iteratively retrieves pages, reasons over visual and textual content, and aggregates evidence from multiple pages E = {pi,j,...} to produce a grounded answer a with attribution. The process typically requires decomposing q, iterative retrieval, and synthesizing across E.
은 질의(q)에 대한 답변(a)을 생성하기 위해 Document corpus (C)에서 여러 페이지(E)에 걸쳐 반복적인 Retrieval, Reasoning, Synthesis를 수행하는 복잡한 과정을 보여줍니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 MADQA 벤치마크를 제안하며, 이는 800개 의 이질적인(Heterogeneous) PDF 문서에서 Human-authored된 2,250개 의 질문으로 구성됩니다. 이 벤치마크는 Classical Test Theory 에 기반하여 Agentic 능력의 다양한 수준을 판별하는 Discriminative power를 극대화하도록 설계되었습니다. Agentic behavior를 평가하기 위해, Accuracy-effort trade-off를 측정하는 새로운 평가 Protocol이 도입되었으며, Kuiper statistic 을 사용하여 Calibration을 정량화합니다.
주요 실험 결과는 다음과 같습니다:
- Agentic System 은 Static RAG 보다 일관되게 우수한 성능을 보였습니다. 예를 들어, Gemini 3 Pro BM25 Agent 는 82.2% 의 Accuracy를 달성하여 Gemini 3 Pro File Search 의 78.6% 보다 높았습니다. 이는 Iterative planning capability의 중요성을 입증합니다
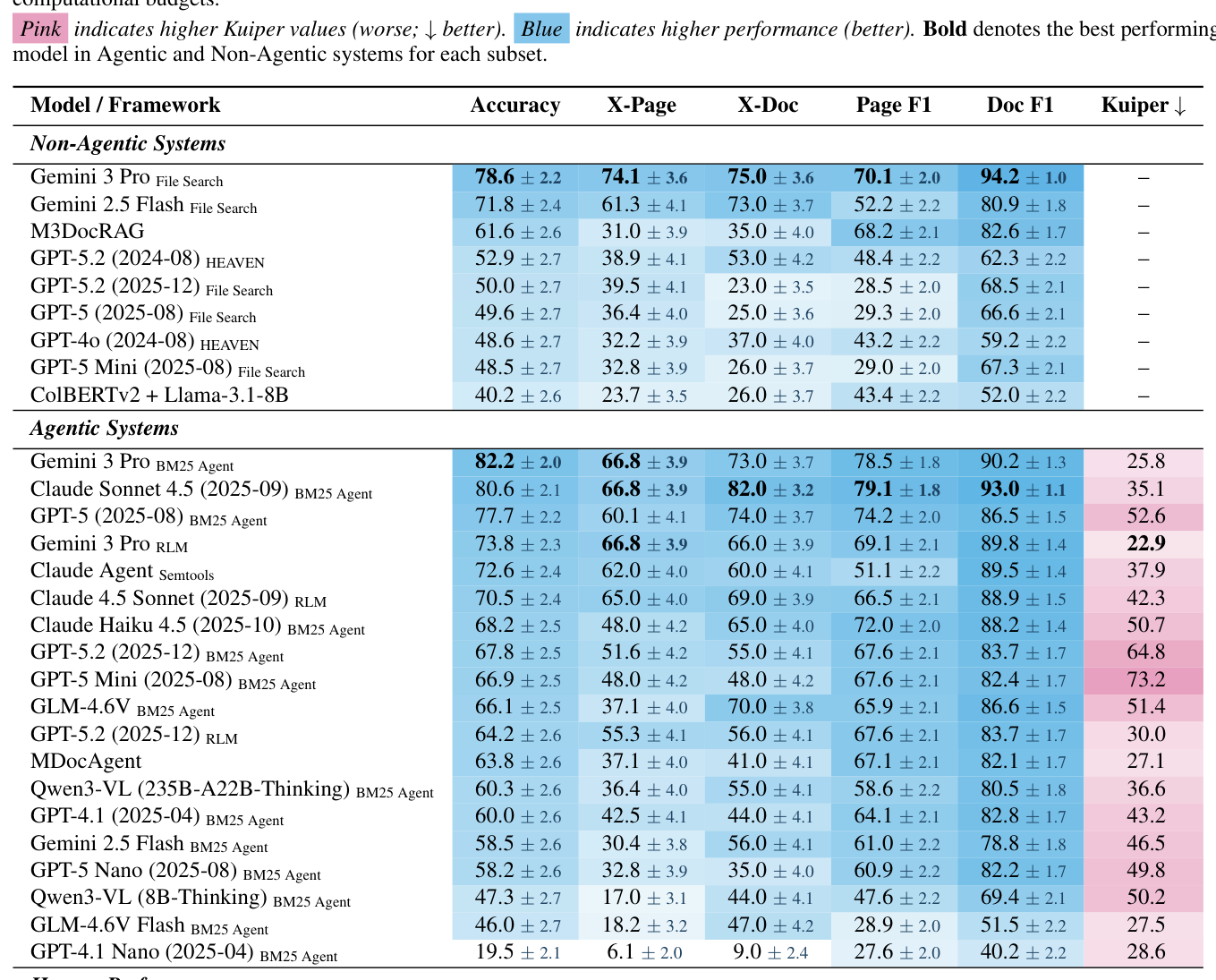 Table 3: Main evaluation results on MADQA. Agentic systems consistently outperform their static RAG counterparts, yet an 18% oracle gap reveals that retrieval—not reasoning—remains the primary bottleneck. We report aggregate Accuracy (± confidence intervals) alongside specific multi-hop reasoning subsets (X-Page and X-Doc). Attribution is measured via Page F1 and Doc F1 to assess grounding fidelity. The Kuiper statistic (↓ is better) quantifies effort calibration; it is excluded for Non-Agentic systems as they operate with fixed computational budgets.
Table 3: Main evaluation results on MADQA. Agentic systems consistently outperform their static RAG counterparts, yet an 18% oracle gap reveals that retrieval—not reasoning—remains the primary bottleneck. We report aggregate Accuracy (± confidence intervals) alongside specific multi-hop reasoning subsets (X-Page and X-Doc). Attribution is measured via Page F1 and Doc F1 to assess grounding fidelity. The Kuiper statistic (↓ is better) quantifies effort calibration; it is excluded for Non-Agentic systems as they operate with fixed computational budgets.
.
- 최고 성능 Agent는 Raw accuracy 측면에서 Human searcher와 유사한 수준(Human BM25 Agent: 82.2% )을 보였지만, 문제 해결 방식에서는 근본적인 차이를 보였습니다. Agent는 Humans와 낮은 Item agreement (Cohen's к = 0.24) 를 보이며, 약한 Strategic planning을 보완하기 위해 Brute-force search 에 의존하는 경향이 있습니다.
- Agent는 Oracle 성능(Oracle Retriever: 99.4% ) 대비 거의 18% 의 Oracle Gap 을 줄이지 못했습니다 [Table 3]. 이는 Retrieval bottleneck이 여전히 주요한 문제임을 시사합니다.
- Agent는 "Cold Start" 효율성에서 Humans에 비해 뒤처집니다. Humans가 첫 번째 Query에서 ~50% 의 Accuracy를 달성하는 반면, Gemini 3 Pro 는 ~12% 에 불과하며, 높은 비용의 Recovery strategy를 통해 따라잡으려 합니다 [Figure 9].
- Recursive Language Models (RLM) 은 이론적으로 유연하지만, Claude Sonnet 4.5 RLM 의 경우 2억 7천만 개 이상의 Input token을 처리하며 $850 의 비용을 발생시키고도 BM25 MLLM counterpart의 Accuracy를 따라잡지 못하는 등 Catastrophic effort overhead 를 보였습니다 [Figure 7].
- Error decomposition 분석
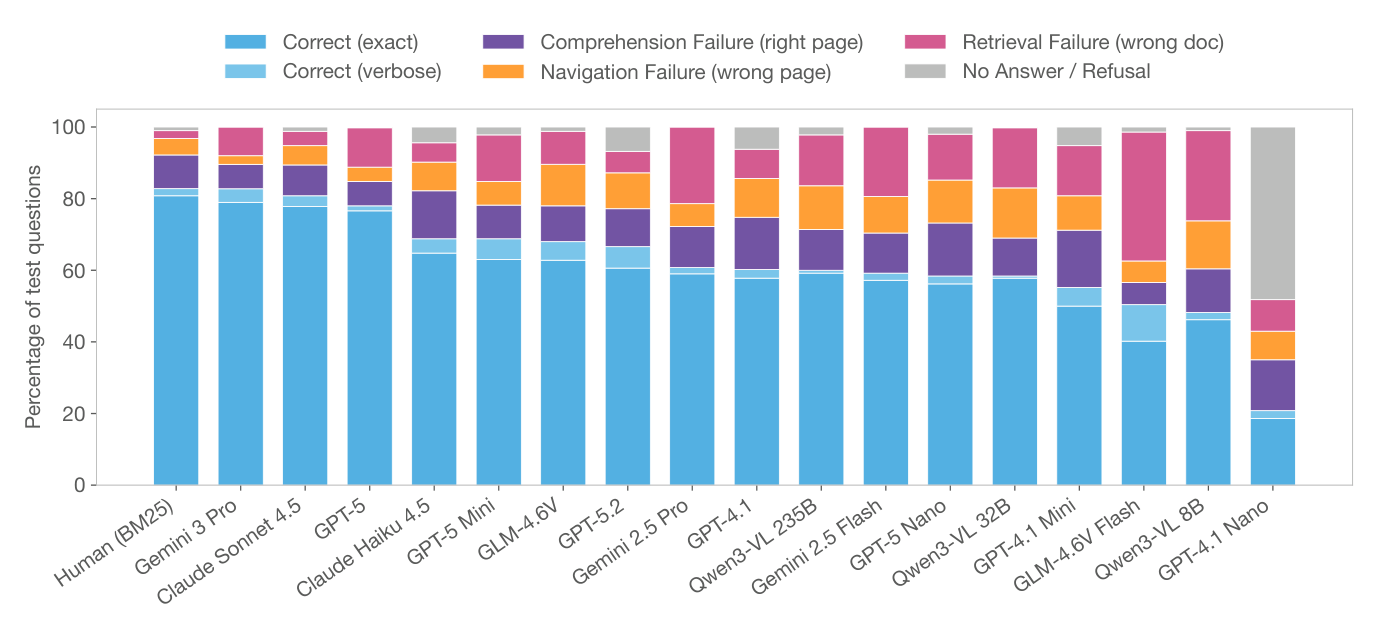 Figure 8: Error decomposition across all BM25 MLLM agents, ordered by accuracy. Each bar decomposes a system’s test predictions into correct (exact and verbose) and four error types. Weaker models are dominated by refusals and retrieval failures, while stronger models shift toward comprehension errors—suggesting that retrieval is largely solved for top systems and answer extraction remains the bottleneck.
Figure 8: Error decomposition across all BM25 MLLM agents, ordered by accuracy. Each bar decomposes a system’s test predictions into correct (exact and verbose) and four error types. Weaker models are dominated by refusals and retrieval failures, while stronger models shift toward comprehension errors—suggesting that retrieval is largely solved for top systems and answer extraction remains the bottleneck.
에 따르면, 약한 모델은 Refusal 과 Retrieval failure 가 지배적이며, 강력한 모델은 Comprehension failure (예: Claude Sonnet 4.5 는 Retrieval failure 4.0% 대비 Comprehension failure 8.6% )로 전환되어 Retrieval은 해결되었으나 Answer extraction이 Bottleneck으로 작용함을 나타냅니다.
- Multi-hop Query의 난이도를 예측하는 데 있어 Physical page distance보다 Semantic distance 가 더 강력한 예측 변수였으며, Evidence가 개념적으로 상이한 Context에 걸쳐 있을 때 Accuracy는 38 Percentage points 감소했습니다 [Table 14].
4. Conclusion & Impact (결론 및 시사점)
결론적으로, 현재 Multimodal Agents 는 복잡한 문서 기반 질문에 높은 정확도로 답변할 수 있지만, 어떤 추가 탐색이 유익한지 신뢰성 있게 인식하지 못하고 상당한 Effort를 소모합니다. 이는 Agents의 Calibrated, efficient reasoning 능력 부족을 나타냅니다.
저자들은 MADQA 벤치마크를 공개하여, Brute-force retrieval 에서 Calibrated, efficient reasoning 으로의 전환을 촉진하고자 합니다. 이 연구는 다음과 같은 두 가지 핵심 방향을 제시합니다:
- Episodic memory 를 통해 Agents가 Corpus-specific terminology 및 Document structure를 학습하여 비생산적인 탐색 루프를 줄일 수 있습니다.
- Search tool feedback을 활용한 Reinforcement learning 은 탐색 정책을 크게 개선할 수 있습니다. 이러한 방향은 Real-world 문서 자동화 워크플로우를 위한 보다 Strategic하고 계산적으로 효율적인 Multimodal Agents 개발에 중요한 시사점을 제공하며, 벤치마크는 Frontier 역량을 평가하는 Discriminative signal 역할을 할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] AgentVista: Evaluating Multimodal Agents in Ultra-Challenging Realistic Visual Scenarios
- [논문리뷰] VisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents
- [논문리뷰] SenseNova-MARS: Empowering Multimodal Agentic Reasoning and Search via Reinforcement Learning
- [논문리뷰] OSWorld-MCP: Benchmarking MCP Tool Invocation In Computer-Use Agents
- [논문리뷰] BESPOKE: Benchmark for Search-Augmented Large Language Model Personalization via Diagnostic Feedback
Review 의 다른글
- 이전글 [논문리뷰] Spatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training
- 현재글 : [논문리뷰] Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
- 다음글 [논문리뷰] TeamHOI: Learning a Unified Policy for Cooperative Human-Object Interactions with Any Team Size
댓글