[논문리뷰] Spatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training
링크: 논문 PDF로 바로 열기
저자: Fangfu Liu, Diankun Wu, Jiawei Chi, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Spatial-TTT : 본 논문에서 제안하는 프레임워크로, Test-Time Training (TTT) 을 활용하여 스트리밍 Visual 기반 Spatial Intelligence 를 구현하고, 적응형 Fast Weights 로 Spatial State 를 업데이트합니다.
- Test-Time Training (TTT) : 추론(Inference) 시점에 파라미터(Fast Weights)를 온라인으로 계속 업데이트하여, 모델이 다양한 입력과 변화하는 환경에 동적으로 적응할 수 있도록 하는 훈련 패러다임입니다.
- Fast Weights : TTT 메커니즘에서 동적으로 업데이트되는 특정 파라미터 서브셋으로, 입력 스트림으로부터 Contextual Information 을 압축하고 저장하는 비선형 메모리 역할을 합니다.
- Hybrid Architecture : Spatial-TTT 의 아키텍처 디자인으로, TTT Layers 와 표준 Self-Attention Anchor Layers 를 3:1 비율로 교차 배치하여, 효율적인 Long-Context Compression 과 사전 학습된 지식(Pretrained Knowledge) 보존의 균형을 이룹니다.
- Spatial-Predictive Mechanism : Spatial-TTT 내 TTT Layers 에 도입된 메커니즘으로, 경량의 Depth-wise 3D Spatiotemporal Convolutions 를 사용하여 Q, K, V Projections 에 Spatiotemporal Inductive Bias 를 직접 주입하고, 기하학적 대응 및 시간적 연속성을 포착하도록 합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
인간은 시각적 관찰 스트림을 통해 실제 공간을 인지하고 이해하므로, 잠재적으로 무한한 비디오 스트림에서 Spatial Evidence 를 스트리밍 방식으로 유지하고 업데이트하는 능력은 Spatial Intelligence 에 필수적입니다. 그러나 기존 Multimodal Large Language Models (MLLMs) 은 2D 시각 이해에서는 인상적인 성능을 보였지만, 3D 기하학적 사전 지식(Geometric Priors)의 부족으로 3D 공간 이해가 필요한 작업에서는 성능이 크게 저하되는 한계가 있었습니다. 특히, Long-Horizon Video Streams 에 대해 Spatial Cue 가 수천 프레임에 걸쳐 흩어져 있어 점진적으로 통합되어야 하는 시나리오에서, 단순히 입력 시퀀스를 확장하면 Quadratic Attention Complexity 로 인해 엄청난 계산 비용이 발생하거나, Temporal Subsampling 은 정확한 3D 추론에 필수적인 미세한 Spatial Details 를 손실하게 됩니다. 또한, 기존 TTT 디자인은 Point-wise Linear Projections 를 사용하여 Visual Tokens 간의 Neighborhood Structure 를 무시하여, Fast Weights 가 3D 구조를 압축하고 메모리를 구조화하는 데 어려움을 겪었습니다. 마지막으로, 기존 Spatial Dataset 의 희소성 및 국지성은 Fast-Weight Update Dynamics 학습을 위한 약한 Gradient Signal 만을 제공했습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문에서는 스트리밍 비주얼 기반 Spatial Intelligence 를 위한 새로운 프레임워크인 Spatial-TTT 를 제안합니다. Spatial-TTT 는 Test-Time Training (TTT) 패러다임을 기반으로, Long-Horizon Scene Video 에서 Spatial Evidence 를 포착하고 정리하기 위해 적응형 Fast Weights 를 업데이트합니다. 방법론적으로 Spatial-TTT 는 Hybrid Architecture 를 사용합니다. 이 아키텍처는 TTT Layers 를 표준 Self-Attention Anchor Layers 와 3:1 비율로 교차 배치하여, 사전 학습된 지식을 보존하면서 효율적인 Long Spatial-Context Compression 을 가능하게 합니다
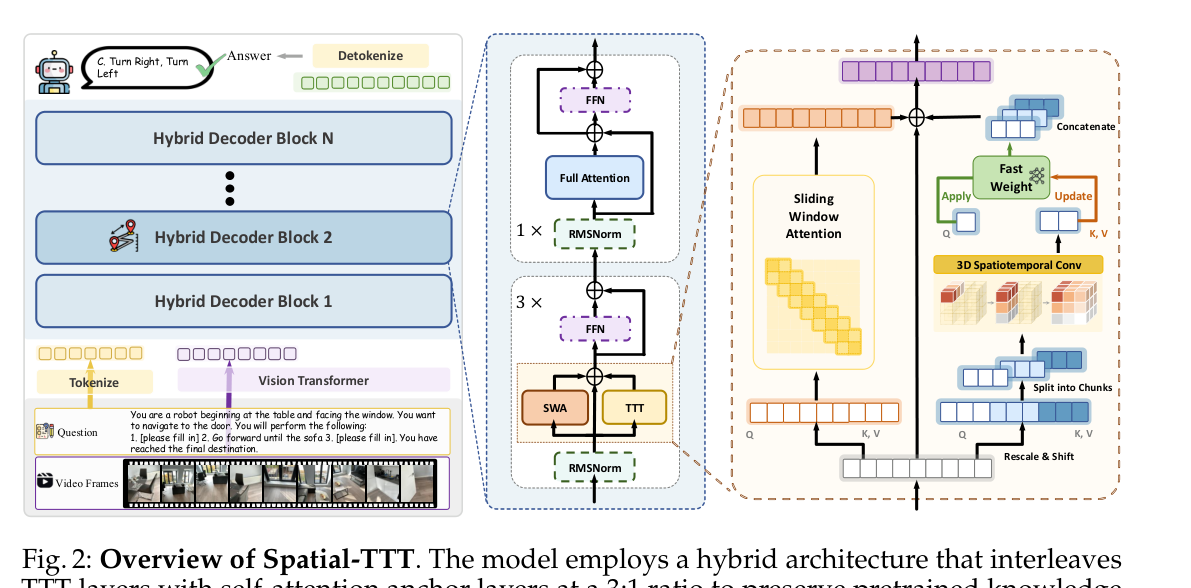 Figure 2: Overview of Spatial-TTT. The model employs a hybrid architecture that interleaves TTT layers with self-attention anchor layers at a 3:1 ratio to preserve pretrained knowledge while enabling efficient long spatial-context compression. Within each TTT layer, sliding window attention (SWA) and TTT branch operate in parallel with shared Q/K/V projections, where the TTT branch applies spatial predictive mechanism with depthwise spatiotemporal convolution to capture geometric structure and temporal continuity.
Figure 2: Overview of Spatial-TTT. The model employs a hybrid architecture that interleaves TTT layers with self-attention anchor layers at a 3:1 ratio to preserve pretrained knowledge while enabling efficient long spatial-context compression. Within each TTT layer, sliding window attention (SWA) and TTT branch operate in parallel with shared Q/K/V projections, where the TTT branch applies spatial predictive mechanism with depthwise spatiotemporal convolution to capture geometric structure and temporal continuity.
. 또한, 효율적인 Spatial Video Processing 을 위해 Large-Chunk Updates 와 병렬 Sliding-Window Attention (SWA) 을 채택하여 Intra-Chunk Spatiotemporal Continuity 를 유지합니다. Spatial Awareness 를 더욱 촉진하기 위해 3D Spatiotemporal Convolution 이 적용된 Spatial-Predictive Mechanism 을 도입하여 Geometric Correspondence 및 Temporal Continuity 를 포착하도록 합니다. 이는 Fast Weights 가 고립된 Tokens 대신 Spatiotemporal Contexts 간의 예측 매핑을 학습하도록 장려합니다. 아키텍처 설계 외에도, 효과적인 Fast-Weight Update Dynamics 학습을 위한 풍부한 Supervision 을 제공하기 위해 Dense Scene-Description Dataset 을 구축했습니다. 이 데이터셋은 글로벌 컨텍스트, 객체 및 개수, 공간 관계를 포함하는 포괄적인 3D 장면 설명을 요구합니다. 훈련 전략으로, Dense Scene-Description Dataset 으로 글로벌 3D 인식을 학습시킨 후, 대규모 Spatial VQA Data 로 스트리밍 공간 추론 능력을 튜닝하는 2단계 Spatial-Aware Progressive Training 방식을 사용합니다. 주요 실험 결과는 다음과 같습니다. VSI-Bench 에서 Spatial-TTT-2B 는 64.4 Avg. 점수를 달성하여, Gemini-3-pro (56.0) 및 Qwen3-VL-8B-Instruct (57.9) 를 포함한 모든 Proprietary 및 Open-source Baselines 를 능가하는 State-of-the-Art Performance 를 보였습니다
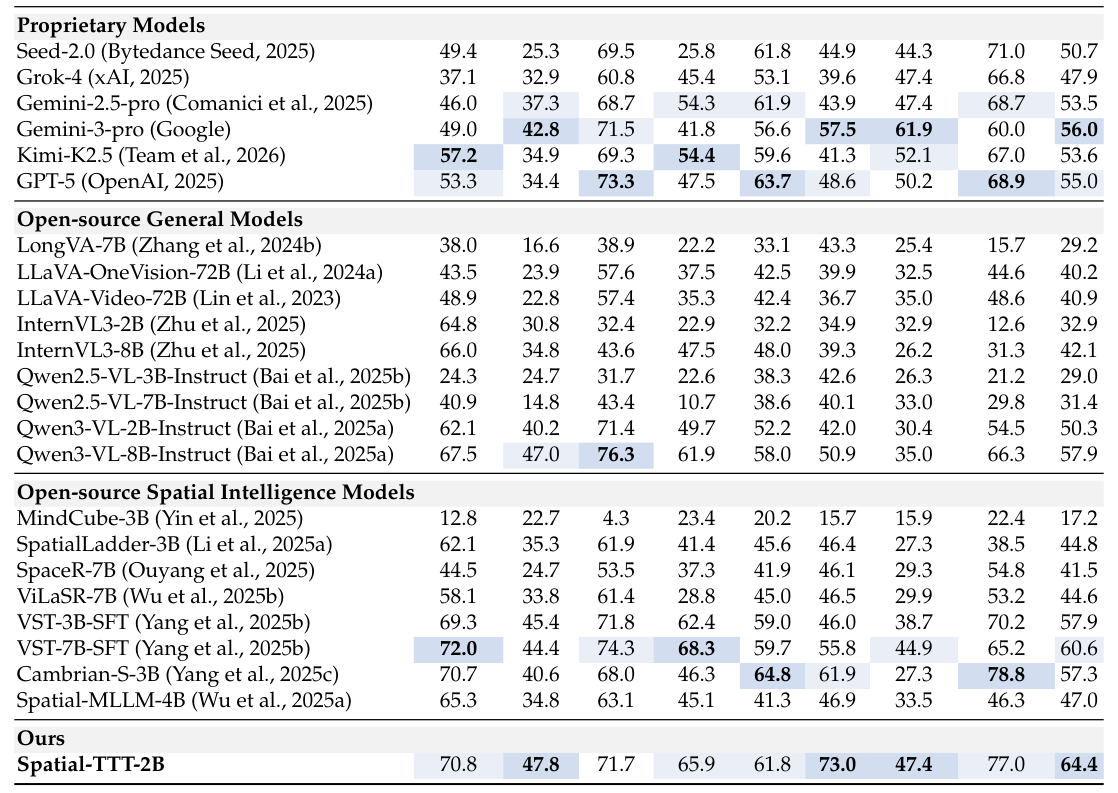 Table 1: Evaluation Results on VSI-Bench (Yang et al., 2025a). For Numerical Questions, we report MRA score. For Multiple-Choice Questions, we report ACC score, Avg. is the macro average across all tasks, following the original paper. For human, we directly use the reported results in VSI-Bench, which is on a subset of VSI-Bench with 400 samples. We and to denote the best and second-best results within proprietary models and open-source models, respectively.
Table 1: Evaluation Results on VSI-Bench (Yang et al., 2025a). For Numerical Questions, we report MRA score. For Multiple-Choice Questions, we report ACC score, Avg. is the macro average across all tasks, following the original paper. For human, we directly use the reported results in VSI-Bench, which is on a subset of VSI-Bench with 400 samples. We and to denote the best and second-best results within proprietary models and open-source models, respectively.
. 특히, Relative Direction 및 Route Plan 과 같은 Multiple-Choice Spatial Reasoning Tasks 에서 강점을 나타냈습니다. MindCube-Tiny 벤치마크에서는 76.2 ACC 점수로 모든 Baseline Models 를 능가했습니다 [Table 2]. VSI-SUPER-Count 벤치마크에서 Spatial-TTT 는 120분 영상 에서 38.4 Avg. 를 기록하며, 메모리 부족으로 성능이 0.0 에 그친 Qwen3-VL-2B 및 Cambrian-S-7B 와 같은 Baseline 들을 크게 능가했습니다 [Table 3]. 이는 Long-Horizon Video Streams 에 대한 뛰어난 Scalability 를 보여줍니다. Ablation Study 결과, Spatial-Predictive Mechanism 을 제거하면 Avg. 점수가 64.4에서 62.1 로 감소하고, Dense Scene-Description Supervision 을 제거하면 Avg. 점수가 64.4에서 61.3 로 감소하여, 제안된 각 구성 요소의 효과성을 입증했습니다. 또한, 1024 프레임 에서 Spatial-TTT-2B 는 Qwen3-VL-2B 대비 TFLOPs 및 메모리 사용량에서 40% 이상 의 감소를 보여 Linear Scaling 특성을 확인했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Streaming Visual-based Spatial Intelligence 를 위한 혁신적인 프레임워크인 Spatial-TTT 를 제안합니다. Spatial-TTT 는 Test-Time Training 을 활용하여 적응형 Fast Weights 를 Compact Memory 로 유지하고, Long-Horizon Video Streams 에서 3D Spatial Evidence 를 효율적으로 누적합니다. 제안된 Hybrid Architecture , Spatial-Predictive Mechanism , 그리고 Dense Scene-Description Dataset 은 모델이 Geometric Correspondence 와 Temporal Continuity 를 효과적으로 학습하고, Long-Horizon Spatial Understanding 을 강화하는 데 기여합니다. 광범위한 실험을 통해 Spatial-TTT 는 여러 Video Spatial Benchmarks 에서 State-of-the-Art Performance 를 달성했으며, 특히 Long-Horizon Videos 에 대한 우수한 효율성과 확장성을 입증했습니다. 이 연구는 Persistent Spatial Memory 를 갖춘 MLLMs 구축을 위한 유망한 방향을 제시하며, Embodied Robotics 및 Autonomous Driving 과 같은 실제 응용 분야에서 더욱 견고하고 확장 가능한 Spatial Intelligence 를 가능하게 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] S-Agent: Spatial Tool-Use Elicits Reasoning for Spatial Intelligence
- [논문리뷰] Rethinking the Role of Efficient Attention in Hybrid Architectures
- [논문리뷰] VisualClaw: A Real-Time, Personalized Agent for the Physical World
- [논문리뷰] The Ghosts of Polymarket: When Off-Chain Matches Meet On-Chain Reverts
- [논문리뷰] P3D-Bench: Benchmarking MLLMs for Parametric 3D Generation and Structural Reasoning
Review 의 다른글
- 이전글 [논문리뷰] ShotVerse: Advancing Cinematic Camera Control for Text-Driven Multi-Shot Video Creation
- 현재글 : [논문리뷰] Spatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training
- 다음글 [논문리뷰] Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
댓글