[논문리뷰] Voxtral TTS
링크: 논문 PDF로 바로 열기
저자: Alexander H. Liu, Alexis Tacnet, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Voxtral Codec : 원본 24 kHz 모노 웨이브폼을 12.5 Hz 프레임의 37개 이산 토큰(1 Semantic + 36 Acoustic)으로 압축하는 컨볼루션-트랜스포머 오토인코더입니다. 이는 ASR-distilled semantic token과 Finite Scalar Quantization (FSQ) acoustic token의 하이브리드 조합을 사용합니다.
- Semantic Token : 음성의 언어적 내용에 초점을 맞춘 저속 Speech Representation으로, Supervised ASR 모델(Whisper)로부터 Distill됩니다.
- Acoustic Token : 풍부한 음향적 세부 정보(예: 음색, 표현력)에 초점을 맞춘 고속 Speech Representation으로, Finite Scalar Quantization (FSQ)을 통해 Quantize됩니다.
- Flow-Matching (FM) Transformer : Decoder Backbone의 Hidden State를 Condition으로 사용하여 Acoustic Token을 예측하는 연속 Generative Model입니다. 이는 Smooth Velocity Field를 활용하여 음향 디테일을 Modeling합니다.
- Direct Preference Optimization (DPO) : Hybrid Discrete-Continuous Setting에 맞게 조정된 Post-training 방법론으로, WER 및 Speaker Similarity와 같은 지표를 개선하기 위해 Human Preference를 활용합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Natural하고 Expressive한 Text-to-Speech (TTS)는 유연한 Human-Computer Interaction의 중요한 요소이며, 가상 비서, 오디오북, 접근성 도구 등 다양한 Application에 활용됩니다. 최근 Neural TTS 모델들이 높은 Intelligibility를 달성했지만, 특히 Zero-Shot Voice Cloning 환경에서 인간 Speech의 뉘앙스와 표현력을 포착하는 것은 여전히 해결해야 할 과제로 남아있습니다.
기존 Zero-Shot TTS 시스템은 주로 짧은 Voice Prompt에서 추출된 Discrete Speech Token에 Condition을 부여하여 생성을 진행하며, Diffusion 및 Flow-based 모델은 Speech Generation에서 풍부한 Acoustic Variation을 Modeling하는 데 효과적입니다. 계층적 Generative Model인 Moshi와 같은 시스템은 Low-rate Semantic Stream과 Higher-rate Acoustic Stream으로 음성을 Factorize하여 활용하지만, Acoustic Generation은 여전히 Depth-wise Auto-Regressive하게 모델링됩니다. 이러한 배경에서, 연구자들은 Dense Acoustic Component가 반드시 Auto-Regressive하게 모델링되어야 하는지에 대한 의문을 제기하며, 대신 Conditional Continuous Model을 통해 더 효과적으로 생성될 수 있는지 탐구하고자 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
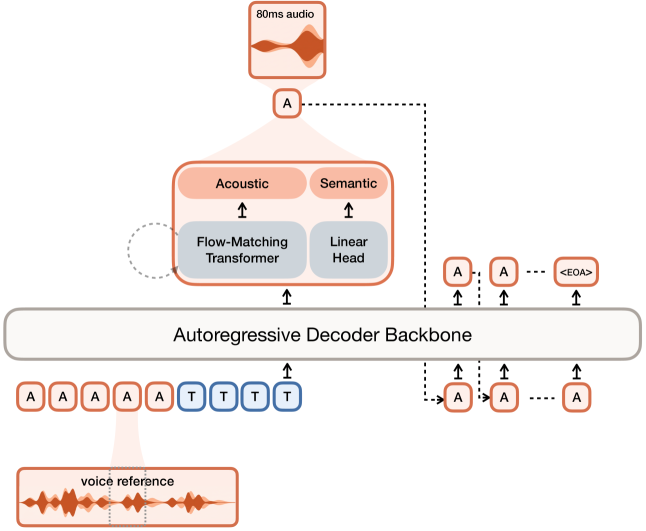
저자들은 Voxtral TTS 를 제안하며, 이는 Representation-aware Hybrid Architecture를 기반으로 하는 Multilingual Zero-Shot TTS 시스템입니다. 이 모델은 Voxtral Codec 이라는 새로운 오디오 코덱을 사용하여 Reference Voice Sample을 Semantic Token과 Acoustic Token으로 구성된 오디오 토큰으로 인코딩합니다
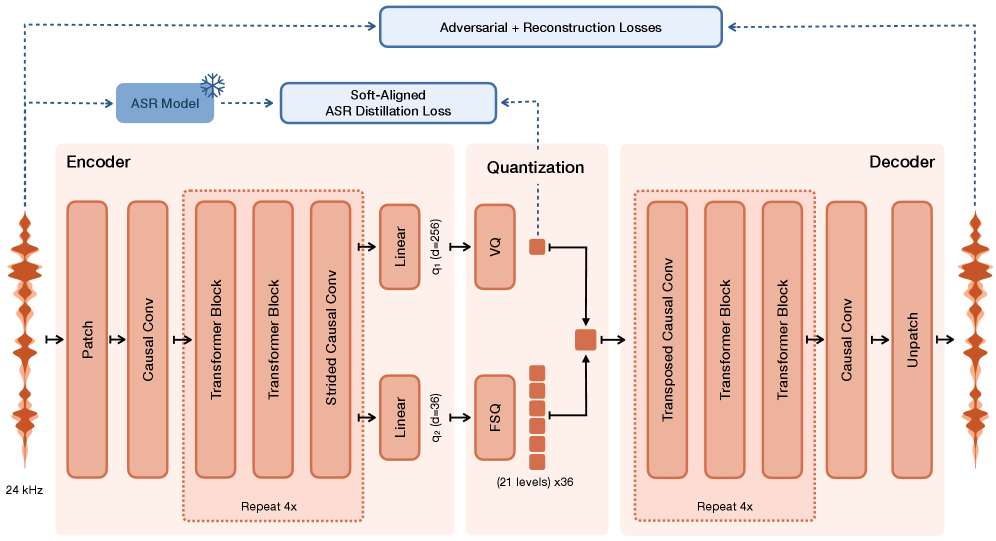
Voxtral Codec은 24 kHz 모노 Waveform을 12.5 Hz 프레임의 37개 이산 토큰 (1 Semantic + 36 Acoustic)으로 압축하며, 총 Bitrate는 2.14 kbps 입니다. Semantic Component는 8192 개 Codebook Size의 Learned Vector Quantizer (VQ)로, Acoustic Component는 36개 차원 각각이 Finite Scalar Quantization (FSQ)을 통해 21개 Uniform Level로 Quantize됩니다
Voxtral Codec 은 Expresso Dataset에서 유사한 Bitrate를 가진 Mimi 대비 모든 Objective Metric에서 우수한 성능을 보였습니다.
Voxtral TTS의 Decoder Backbone은 Ministral 3B 아키텍처를 따르는 Auto-Regressive Decoder-Only Transformer입니다. 이 Backbone은 Semantic Token Sequence를 Auto-Regressive하게 예측하며, 각 시점의 Hidden State는 Flow-Matching (FM) Transformer 로 전달되어 Acoustic Token을 예측합니다. FM Transformer는 Gaussian Noise를 Acoustic Embedding으로 운반하는 Velocity Field를 Modeling하며, 8개 의 Function Evaluations (NFEs)와 Classifier-Free Guidance (CFG) 를 사용하여 추론합니다. 이 설계는 Long-range Consistency를 위한 Auto-Regressive Modeling의 강점과 풍부한 Acoustic Detail을 위한 Continuous Flow-Matching의 강점을 결합합니다.
모델은 Pseudo-labeled 데이터를 사용하여 Pretrain되며, Semantic Token에 대한 Cross-Entropy Loss와 Acoustic Token에 대한 Flow-Matching Loss로 최적화됩니다. 이후 Direct Preference Optimization (DPO) 을 통해 모델을 Post-train하여 WER 및 Speaker Similarity 를 개선합니다. DPO는 대부분의 언어에서 WER 과 UTMOS Metric을 향상시키는 효과를 보였습니다.
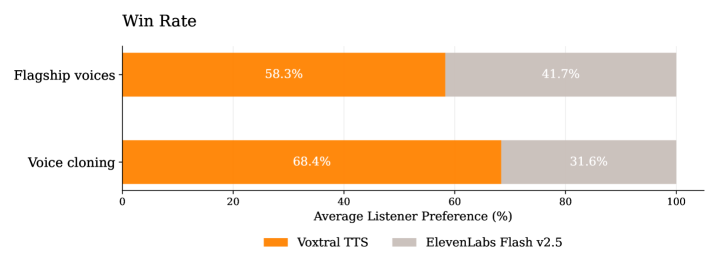
핵심 결과로, Human Evaluation에서 Voxtral TTS 는 Multilingual Zero-Shot Voice Cloning Task에서 ElevenLabs Flash v2.5 대비 68.4% 의 높은 Win Rate를 달성하며 Naturalness와 Expressivity 측면에서 선호도가 높았습니다
또한 Automatic Evaluation에서 ElevenLabs v3 대비 더 높은 Speaker Similarity Score를 기록했습니다. Inference 및 Serving 측면에서는 vLLM-Omni 를 통해 Single NVIDIA H200 GPU에서 Concurrency 32 일 때 1,430.78 characters per second per GPU 의 Throughput을 달성하며, Latency는 Sub-second를 유지했습니다. Flow-Matching Transformer에 CUDA Graph Acceleration 을 적용하여 Latency를 47% 개선하고 RTF를 2.5배 감소시켰습니다.
4. Conclusion & Impact (결론 및 시사점)
저자들은 Semantic Token의 Auto-Regressive Generation과 Acoustic Token의 Flow-Matching을 결합한 Hybrid Architecture를 활용하는 Multilingual TTS 모델인 Voxtral TTS 를 성공적으로 개발했습니다. 이 모델은 ASR-Distilled Semantic Token과 FSQ Acoustic Token을 사용하는 Voxtral Codec 을 기반으로 합니다.
Voxtral TTS 는 최소 3초 의 Reference Audio만으로 Expressive하고 Voice-Cloned Speech를 생성할 수 있으며, Human Evaluation에서 기존 API Baseline보다 우수한 성능을 보였습니다. 특히 Multilingual Zero-Shot Voice Cloning 시나리오에서 ElevenLabs Flash v2.5 대비 68.4% 의 높은 Win Rate를 달성하며 그 강력한 Generalizability를 입증했습니다. 이 연구는 High-Quality, Expressive TTS 시스템의 개발에 중요한 기여를 하며, 모델 Weight를 CC BY-NC License 하에 공개함으로써 학계 및 산업계의 추가 연구와 발전을 장려합니다. 또한 vLLM-Omni 와의 통합을 통해 Production 환경에서의 Low-Latency Streaming Inference 가능성을 보여주어 실제 서비스 적용에 대한 큰 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] dots.tts Technical Report
- [논문리뷰] NORA-1.5: A Vision-Language-Action Model Trained using World Model- and Action-based Preference Rewards
- [논문리뷰] NormGuard: Reward-Preserving Norm Constraints in Flow-Matching Reinforcement Learning
- [논문리뷰] Rethinking the Role of Efficient Attention in Hybrid Architectures
- [논문리뷰] The Ghosts of Polymarket: When Off-Chain Matches Meet On-Chain Reverts
댓글