[논문리뷰] LiVeAction: a Lightweight, Versatile, and Asymmetric Neural Codec Design for Real-time Operation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Dan Jacobellis, Neeraja J. Yadwadkar
1. Key Terms & Definitions (핵심 용어 및 정의)
- LiVeAction: 본 논문에서 제안하는 가볍고 다목적이며 비대칭적인 신경망 코덱 아키텍처로, 리소스가 제한된 환경에서의 실시간 연산을 위해 설계됨.
- FSQ (Finite Scalar Quantization): 고정된 크기의 차원 병목과 스칼라 양자화를 결합하여 효율적인 압축을 구현하는 학습된 벡터 양자화 기법.
- WPT (Wavelet Packet Transform): 신호의 공간/시간적 해상도를 주파수 해상도로 변환하여 에너지 집중을 극대화하는 변환 기법.
- Asymmetric Design: 인코더와 디코더의 구조를 다르게 설계하여, 리소스가 제한된 환경(임베디드 기기)에서의 인코딩 연산 효율성을 극대화하는 설계 방식.
- BD-rate (Bjøntegaard-Delta rate): 두 압축 기법 간의 성능을 비교할 때, 동일한 왜곡 수준에서 비트레이트 차이를 나타내는 지표.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 고해상도 데이터 생성 센서 환경에서 발생하는 대역폭 및 전력 제약을 해결하기 위한 효율적인 신경망 코덱의 필요성을 다룬다. 기존의 상용 코덱(JPEG, MPEG)은 인간 지각에 최적화되어 있어 머신 퍼셉션 작업이나 비전통적 모달리티(공간 오디오, 하이퍼스펙트럴 등)에는 부적합하다. 또한, 최근의 generative neural codecs는 모델이 과도하게 매개변수화되어 있고 복잡한 계산량을 요구하여 리소스가 제한된 모바일 및 엣지 환경에서 실시간으로 운용하기 어렵다 [Figure 1]. 이러한 한계를 극복하기 위해 본 연구는 연산 효율성이 극대화된 새로운 코덱 설계를 제안한다.
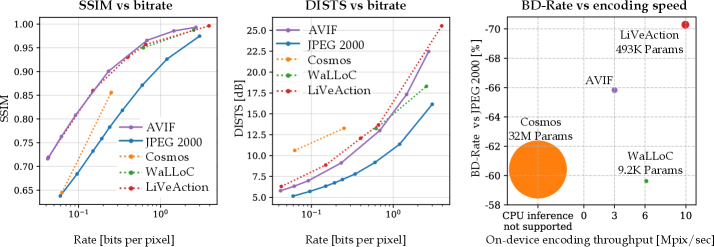
Figure 1 — RGB 이미지에 대한 RD-complexity 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
LiVeAction은 인코딩 효율성, 경쟁력 있는 rate-distortion 성능, 그리고 모달리티 범용성을 달성하기 위해 비대칭 구조와 단순화된 학습 목적 함수를 채택한다. 인코더는 FFT와 유사한 구조의 block-diagonal 연산을 사용하여 연산량을 크게 절감하며, 디코더는 효율적인 EfficientViT 블록을 기반으로 높은 표현력을 유지한다 [Figure 2]. 학습 과정에서는 복잡한 perceptual/adversarial loss를 배제하고, 샘플 분산에 기반한 단순화된 rate penalty를 사용하여 훈련 안정성을 높였다 [Figure 3]. 실험 결과, LiVeAction은 기존 상태-최첨단 기술인 Cosmos 대비 34%의 BD-rate 개선을 달성함과 동시에 인코딩 속도를 10배 이상 향상시켰다. 또한, 이미지 인식 성능 면에서도 더 적은 비트레이트로 동일한 수준의 top-1 classification accuracy를 달성하며 정량적으로 우수한 성능을 입증하였다 [Table II], [Figure 4].
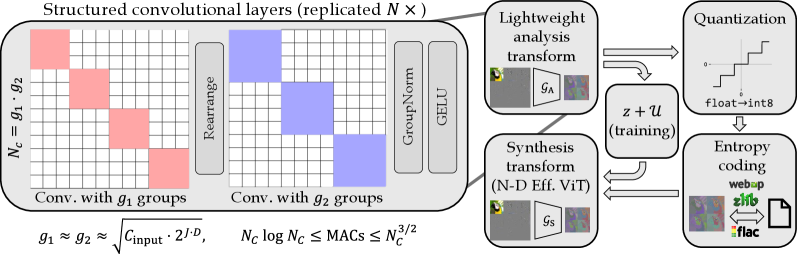
Figure 2 — 제안하는 LiVeAction 아키텍처
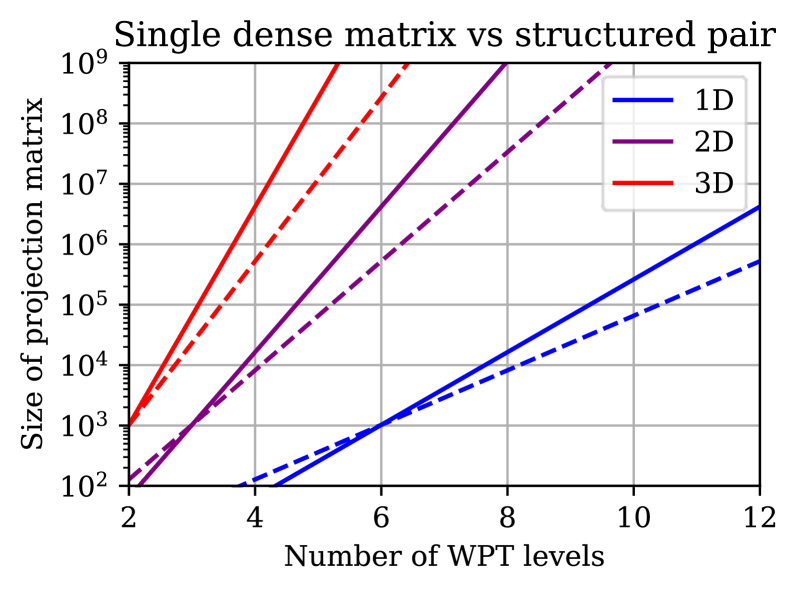
Figure 3 — 선형 투영과 구조화된 행렬 연산 비교
4. Conclusion & Impact (결론 및 시사점)
LiVeAction은 신경망 압축의 설계 복잡성을 낮추고 연산 효율성을 극대화함으로써 학습 기반 압축 기술을 새로운 신호 유형과 센서에 적용 가능하도록 한 중요한 진전을 이루었다. 본 연구는 리소스가 제한된 기기에서도 고충실도 압축을 실현하여 모바일 및 원격 센싱 분야의 실시간 애플리케이션을 가속화할 것으로 기대된다. 향후 연구에서는 가변 비트레이트 학습과 다운스트림 머신러닝 작업과의 공동 최적화를 통해 압축과 추론 정확도 간의 정렬을 개선할 계획이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Wan-Streamer v0.2: Higher Resolution, Same Latency
- [논문리뷰] NoPA: Non-Parametric Online 3D Scene Graph Generation
- [논문리뷰] DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
- [논문리뷰] Lip Forcing: Few-Step Autoregressive Diffusion for Real-time Lip Synchronization
- [논문리뷰] SwiftVR: Real-Time One-Step Generative Video Restoration
Review 의 다른글
- 이전글 [논문리뷰] LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling
- 현재글 : [논문리뷰] LiVeAction: a Lightweight, Versatile, and Asymmetric Neural Codec Design for Real-time Operation
- 다음글 [논문리뷰] Listwise Policy Optimization: Group-based RLVR as Target-Projection on the LLM Response Simplex
댓글