[논문리뷰] Listwise Policy Optimization: Group-based RLVR as Target-Projection on the LLM Response Simplex
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yun Qu, Qi Wang, Yixiu Mao, Heming Zou, Yuhang Jiang, Yingyue Li, Wutong Xu, Lizhou Cai, Weijie Liu, Clive Bai, Kai Yang, Yangkun Chen, Saiyong Yang, Xiangyang Ji
1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards): 모델이 생성한 응답에 대해 즉각적인 정오 판별(verifiable reward)을 통해 추론 능력을 강화하는 LLM post-training paradigm입니다.
- Group-based Policy Gradient: 동일한 프롬프트에 대해 여러 응답을 샘플링하여 그룹 내 상대적 보상(relative advantage)을 통해 정책을 업데이트하는 RLVR의 핵심 방법론입니다.
- Response Simplex: 샘플링된 KK개의 응답들에 대해 정책이 할당하는 확률 분포가 형성하는 기하학적 공간으로, 이 위에서 목표 분포로의 투영(projection)이 이루어집니다.
- Listwise Policy Optimization (LPO): 정책의 implicit한 보상 추정을 명시적인 target-projection으로 재정의하여 안정적인 학습과 유연한 divergence 선택을 가능하게 하는 제안 프레임워크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현재의 Critic-free, group-based RLVR 기법들이 사용하는 advantage normalization이 실제로는 응답 심플렉스 위에서 잠재적인 목표 분포를 암묵적으로 구성하고 있음을 규명합니다. [Figure 1] 기존의 정책 경사 기반 방법들은 표준적인 정책 업데이트가 이 암묵적인 목표 분포로 향하는 1차 근사(first-order approximation)에 불과하여, 최적화 과정에서 이론적 불투명성과 성능 한계를 가진다는 문제점이 있습니다. 따라서 본 연구는 이러한 암묵적 근사를 넘어서, 최적화를 위한 목표 분포 설정과 이 목표로 향하는 투영 과정을 분리하여 명시적으로 수행하는 프레임워크가 필요하다고 제안합니다 [Figure 1].

Figure 1 — LPO의 명시적 target-projection
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Listwise Policy Optimization (LPO) 프레임워크를 제안하여 명시적인 target-projection을 구현합니다 [Figure 2]. LPO는 Proximal RL objective를 응답 심플렉스로 제한하여 온도 파라미터(temperature, τ)를 통해 제어 가능한 닫힌 형태의 Listwise Gibbs target을 도출하고, 이를 위해 Forward KL 및 Reverse KL 등의 발산(divergence) 측정치를 사용하여 정책을 투영합니다 [Figure 2]. 주요 실험 결과, LPO는 논리, 수학, 프로그래밍, 다중 모달 기하학 등 다양한 추론 작업에서 기존 GRPO, Dr.GRPO, MaxRL 베이스라인 대비 일관된 성능 우위를 점했습니다 [Figure 3]. 정량적 지표로, Pass@1 및 Pass@k 정확도에서 기존 방법론들 대비 더 높은 효율을 기록했으며, 특히 Forward KL 변형은 응답의 다양성을 보존하는 모드 커버리지(mode-coverage) 특성으로 인해 뛰어난 경쟁력을 보였습니다. 또한, LPO는 gradient norm을 안정화하고 최적화 경로상의 응답 엔트로피를 높게 유지함으로써 학습 안정성을 크게 개선하는 것으로 나타났습니다 [Figure 5].
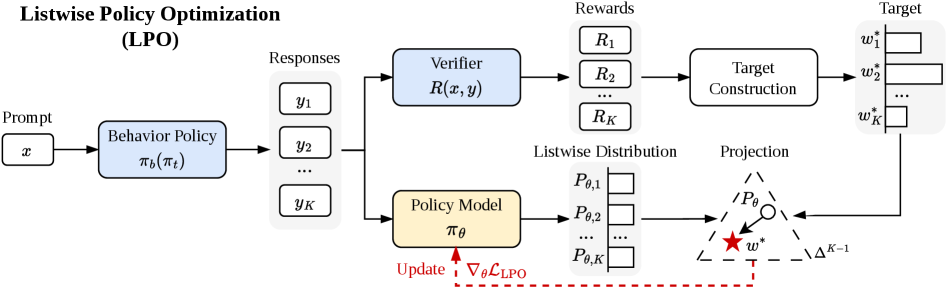
Figure 2 — LPO와 기존 PG 방법의 기하학적 비교
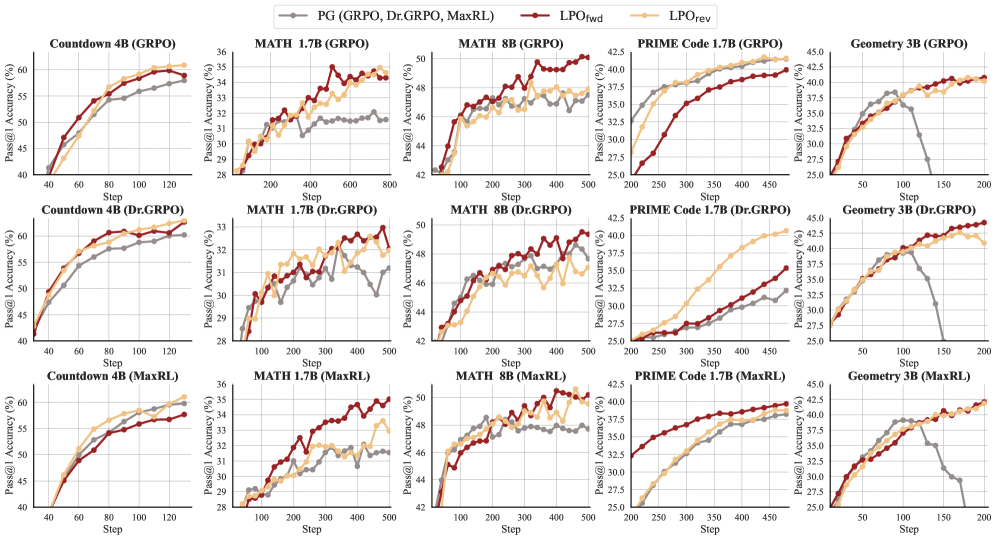
Figure 3 — Pass@1 학습 곡선 비교 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 group-based RLVR 알고리즘들이 공유하는 기하학적 구조를 "Target-Projection"이라는 틀로 통합적으로 분석하고, 이를 명시적으로 최적화하는 LPO를 개발하여 성능과 안정성을 모두 확보했습니다. 이 연구는 RLVR 설계 공간에서 목표 설정과 투영 과정을 분리함으로써, 추후 연구자들이 다양한 Divergence와 적응형 스케줄링 전략을 유연하게 결합할 수 있는 발판을 마련했습니다. 학계와 산업계는 이 프레임워크를 통해 모델의 추론 능력을 보다 효율적이고 견고하게 강화할 수 있을 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ThinkTwice: Jointly Optimizing Large Language Models for Reasoning and Self-Refinement
- [논문리뷰] Can LLMs Learn to Reason Robustly under Noisy Supervision?
- [논문리뷰] Heterogeneous Agent Collaborative Reinforcement Learning
- [논문리뷰] FAPO: Flawed-Aware Policy Optimization for Efficient and Reliable Reasoning
- [논문리뷰] Implicit Actor Critic Coupling via a Supervised Learning Framework for RLVR
Review 의 다른글
- 이전글 [논문리뷰] LiVeAction: a Lightweight, Versatile, and Asymmetric Neural Codec Design for Real-time Operation
- 현재글 : [논문리뷰] Listwise Policy Optimization: Group-based RLVR as Target-Projection on the LLM Response Simplex
- 다음글 [논문리뷰] MACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
댓글