[논문리뷰] MACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Kaixing Yang, Jiashu Zhu, Xulong Tang, Ziqiao Peng, Xiangyue Zhang, Puwei Wang, Jiahong Wu, Xiangxiang Chu, Hongyan Liu, Jun He
1. Key Terms & Definitions (핵심 용어 및 정의)
- MACE-Dance:
Motion-Appearance Cascaded Experts의 약자로, 모션 생성과 비디오 합성을 전문가 모듈로 분리하여 음악 기반 댄스 비디오를 생성하는 프레임워크입니다. - Guidance-Free Training (GFT): 별도의
Classifier-Free Guidance (CFG)추론 없이 학습 단계에서temperature parameter를 통해 출력의 다양성과 충실도를 조절하는 학습 전략입니다. - BiMamba-Transformer: 음악 및 모션의 로컬 의존성을 학습하는
Bidirectional Mamba와 전역적인 문맥(Global context)을 모델링하는Transformer를 결합한 하이브리드 아키텍처입니다. - SMPL: 3D 인체 포즈와 형태를 표현하는 표준 모델로, 본 논문에서는 2D 키포인트 대신 3D 모션을 중간 표현으로 사용하여 기하학적 일관성을 확보합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 음악 기반 댄스 비디오 생성 시 발생하는 모션의 비현실성과 시각적 일관성 부족 문제를 해결하는 것을 목표로 합니다. 기존 연구들은 주로 3D 모션 생성에만 집중하거나, 인물 이미지 애니메이션 기술을 그대로 적용하여 복잡한 댄스 동작을 제대로 처리하지 못하는 한계가 있습니다. 특히 기존의 end-to-end 방식은 음악과 영상 간의 모호한 상관관계로 인해 시각적 왜곡과 모션 결함이 자주 발생합니다 [Figure 1]. 이러한 문제로 인해 댄스의 3D 특성을 온전히 반영하면서도 고품질의 비디오를 생성할 수 있는 새로운 접근 방식이 요구됩니다.

Figure 1 — MACE-Dance 전체 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 모션 생성과 비디오 합성을 독립적으로 처리하는 Cascaded Mixture-of-Experts (MoE) 아키텍처인 MACE-Dance를 제안합니다 [Figure 2]. 모션 전문가(Motion Expert)는 BiMamba-Transformer 하이브리드 구조와 GFT 전략을 통해 음악으로부터 kinematically plausible한 3D SMPL 모션을 생성합니다. 이후 외형 전문가(Appearance Expert)는 decoupled Kinematic–Aesthetic fine-tuning 전략을 적용하여, reference image와 3D 모션을 기반으로 spatiotemporally coherent한 영상을 합성합니다 [Figure 3]. 성능 평가 결과, MACE-Dance는 3D 댄스 생성 데이터셋인 FineDance에서 최상위 성능(FIDk=17.83)을 달성하였으며, 댄스 비디오 생성 task에서도 기존 기법 대비 뛰어난 모션 충실도와 외형 일관성을 보였습니다 [Table 1][Table 2]. 특히 제안된 MACE-Dance는 FID_g 지표에서 0.28을 기록하며 비교군 중 가장 우수한 수치를 나타냈습니다 [Table 1].
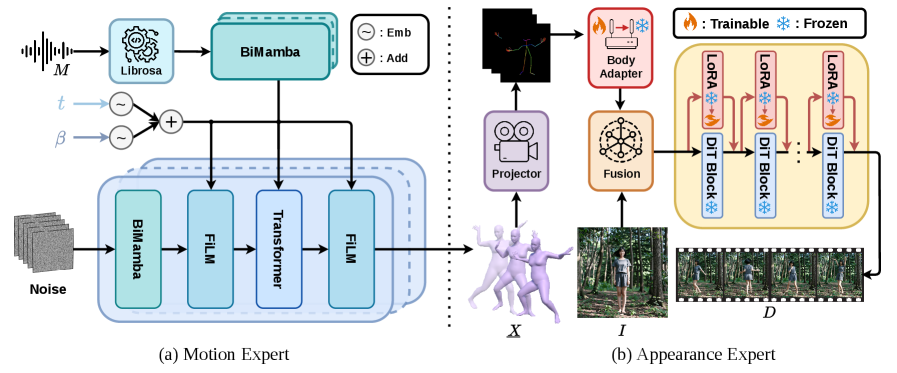
Figure 2 — MACE-Dance 아키텍처

Figure 3 — SOTA 비교 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 댄스 생성 작업을 모션과 외형으로 분리하여 전문가 모델을 활용함으로써, 음악과 동작의 일관성을 극대화한 고품질 댄스 비디오 생성 프레임워크를 정립했습니다. 특히 제안된 모션 표현 방식과 데이터셋, 평가 프로토콜은 향후 해당 분야의 표준화에 기여할 것으로 기대됩니다. 이 연구의 기술적 가치는 음악 기반의 자동 댄스 제작을 넘어, 추후 텍스트 제어 기술이나 실시간 상호작용 시스템으로 확장될 수 있는 강력한 토대를 마련했다는 점에 있습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Coarse-Guided Visual Generation via Weighted h-Transform Sampling
- [논문리뷰] JavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation
- [논문리뷰] ProPhy: Progressive Physical Alignment for Dynamic World Simulation
- [논문리뷰] Phased DMD: Few-step Distribution Matching Distillation via Score Matching within Subintervals
- [논문리뷰] SANA-Video: Efficient Video Generation with Block Linear Diffusion Transformer
Review 의 다른글
- 이전글 [논문리뷰] Listwise Policy Optimization: Group-based RLVR as Target-Projection on the LLM Response Simplex
- 현재글 : [논문리뷰] MACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
- 다음글 [논문리뷰] MDN: Parallelizing Stepwise Momentum for Delta Linear Attention
댓글