[논문리뷰] MDN: Parallelizing Stepwise Momentum for Delta Linear Attention
링크: 논문 PDF로 바로 열기
저자: Zunchang Liu, Xiaopeng Lin, Hongxiang Huang, Xiang Liu, Yulong Huang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Linear Attention (LA): self-attention의 $O(L^2)$ 계산 복잡도를 $O(L)$로 줄이기 위해 Softmax 연산을 선형 커널로 대체하는 시퀀스 모델링 기법.
- Delta Rule: 입력값($v_t$)과 예측값의 차이를 학습하여 모델의 재귀적 업데이트를 개선하는 기법으로, associative recall 성능을 향상시킴.
- Stepwise Momentum: 경사하강법(SGD) 기반 업데이트에 모멘텀을 결합하여 과거의 gradient 정보를 축적하고 최적화 궤적을 안정화하는 기법.
- Chunkwise Parallelism: 전체 시퀀스를 짧은 chunk로 분할하여 계산함으로써, 재귀적 모델의 순차적 연산 한계를 극복하고 하드웨어 가속기(GPU) 효율성을 극대화하는 병렬화 전략.
- Second-order Dynamical Systems: 모멘텀 기반 재귀를 2차 미분 방정식 형태로 해석하여, 모델 내 복소수 eigenvalue를 유도하고 oscillatory 모드를 학습 가능하게 만드는 이론적 프레임워크.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 Linear Attention 모델들이 가지는 재귀적 업데이트의 한계인 정보 소실과 최적화 효율 저하 문제를 해결하고자 한다. 특히, 기존 모델들은 naive SGD 업데이트에 의존하여 장기 기억 및 문맥 검색(in-context retrieval) 능력에 제약이 있다. Momentum 방식이 최적화 안정성을 제공할 수 있음에도 불구하고, stepwise momentum은 엄격한 인과성(causality) 유지와 높은 병렬 처리 효율성을 동시에 달성하기 어렵다는 구조적 한계가 존재한다. 저자들은 기존 기법들이 병렬화를 위해 인과성을 포기하거나 근사치를 사용하는 등의 문제점(Training-Inference Mismatch)을 해결하기 위해 새로운 알고리즘을 제안한다 [Figure 1].

Figure 1 — 학습 중 causal 구조 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 stepwise momentum rule을 적용하기 위해 Momentum DeltaNet (MDN)을 제안하며, 재귀적 업데이트 계수를 기하학적으로 재배열하는 chunkwise parallel 알고리즘을 도입하였다. 이 방법론은 엄격한 temporal causality를 준수하면서도 하드웨어 가속기에서 효율적으로 병렬 연산을 수행한다. 또한, momentum 기반 재귀를 2차 동적 시스템으로 분석하여, eigenvalue가 1사분면과 4사분면에 위치하도록 제한하는 안정적 gating 기법을 설계하였다 [Figure 2], [Figure 3].
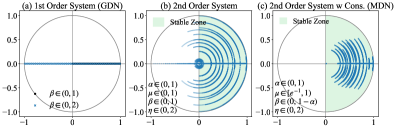
Figure 2 — Spectral root trajectories
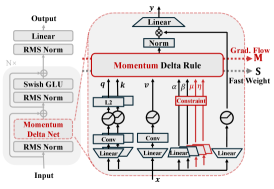
Figure 3 — MDN 아키텍처 다이어그램
성능 평가 결과, MDN은 400M 및 1.3B 파라미터 모델에서 기존 모델 대비 일관된 성능 향상을 보였다.
- LongBench 16K 길이 테스트에서 평균 점수 기준, MDN은 기존 최고 모델 대비 우수한 성능을 달성하였다 [Table 3].
- Needle-In-A-Haystack 벤치마크(특히 8K 컨텍스트)에서 MDN은 Multi-needle 환경에서 가장 강력한 베이스라인 대비 각각 13.40, 11.45, 8.95점 향상된 정확도를 기록하였다.
- 복합적인 reasoning 태스크와 in-context retrieval 작업에서도 기존 강력한 baseline인 GDN, Comba, KDA 등을 능가하는 성능을 보였다 [Table 2].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 stepwise momentum을 Linear Attention에 효과적으로 통합하는 chunkwise parallel 알고리즘을 통해 계산 복잡도와 모델 성능 사이의 균형을 성공적으로 달성하였다. 특히 2차 동적 시스템 기반의 해석은 향후 효율적이고 표현력이 풍부한 재귀 모델 설계에 중요한 이론적 토대를 제공한다. 이 연구는 LLM의 긴 문맥 처리와 효율적 최적화 분야에서 학계와 산업계에 중요한 기여를 할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention
- [논문리뷰] Gated Condition Injection without Multimodal Attention: Towards Controllable Linear-Attention Transformers
- [논문리뷰] Memory Caching: RNNs with Growing Memory
- [논문리뷰] HyTRec: A Hybrid Temporal-Aware Attention Architecture for Long Behavior Sequential Recommendation
- [논문리뷰] Test-Time Training with KV Binding Is Secretly Linear Attention
Review 의 다른글
- 이전글 [논문리뷰] MACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
- 현재글 : [논문리뷰] MDN: Parallelizing Stepwise Momentum for Delta Linear Attention
- 다음글 [논문리뷰] MISA: Mixture of Indexer Sparse Attention for Long-Context LLM Inference
댓글