[논문리뷰] Vega: Learning to Drive with Natural Language Instructions
링크: 논문 PDF로 바로 열기
The paper is "Vega: Learning to Drive with Natural Language Instructions" by Sicheng Zuo, Yuxuan Li, Wenzhao Zheng, Zheng Zhu, Jie Zhou, and Jiwen Lu. It was submitted on March 26, 2026.
I have the content now. Let's proceed with extracting metadata, summarizing, and then finding figure details.
Metadata:
- Authors: Sicheng Zuo, Yuxuan Li, Wenzhao Zheng, Zheng Zhu, Jie Zhou, et al.
- Keywords:
Autonomous Driving,Natural Language Instructions,Large Language Models (LLMs),End-to-End Control,World Models,Vision-Language Models (VLMs),Diffusion Models,Trajectory Planning
Part 1: Summary
1. Key Terms & Definitions
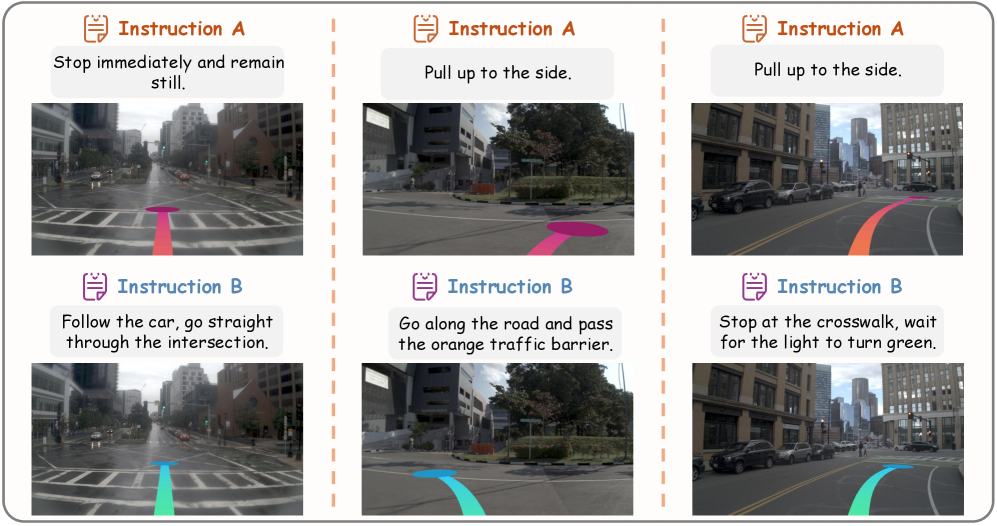
- Natural Language Instructions (NLIs) : 자율주행 시스템에 주어지는 "앞차를 추월하여 다음 신호를 잡아라"와 같이 사용자가 지정하는 유연하고 개방형의 자연어 명령어를 의미합니다.
- Vision-Language-Action (VLA) models : 시각적 입력과 언어적 입력을 처리하여 주행 액션으로 매핑하는 모델로, 대규모 언어 모델(LLM)의 풍부한 세계 지식을 활용하여 의사결정 프로세스에 언어를 통합합니다.
- World Models : 과거 관측값과 현재 액션을 조건으로 미래 상태를 예측하는 생성 모델로, 자율주행에서는 미래 이미지 생성이나 장면 시뮬레이션에 활용됩니다.
- Vega : Natural Language Instructions 기반의 Generation 및 Planning을 위한 Unified Vision-Language-World-Action 모델로, autoregressive 및 diffusion 패러다임을 결합하여 미래 예측 및 궤적 생성을 수행합니다.
- Integrated Transformer : Autoregressive VLM과 Diffusion Transformer를 단일 모델로 통합하여 시각-텍스트 이해, 시각 생성 및 액션 플래닝 기능을 심층적으로 통합하는 아키텍처입니다.
2. Motivation & Problem Statement
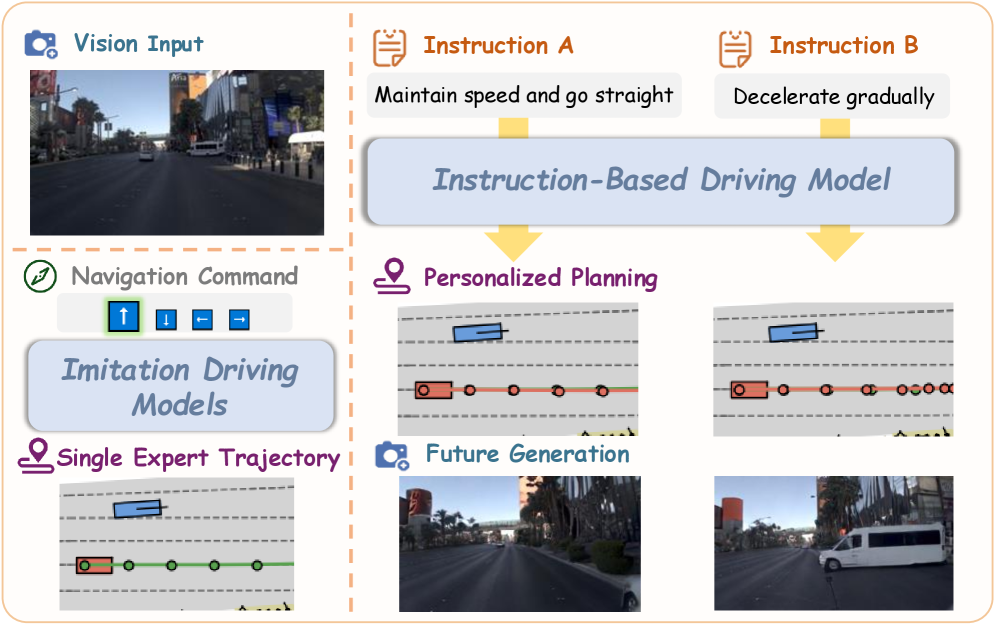
기존 자율주행 시스템은 주로 Perception, Prediction, Planning의 모듈형 파이프라인을 따르며, 이는 고비용의 3D annotation에 크게 의존하여 실제 적용에 한계가 있습니다. 최근 Vision-Language-Action (VLA) 모델이 부상하여 다양한 시나리오에서 뛰어난 generalization 능력을 보였지만, 대부분의 기존 VLA 모델은 언어를 장면 설명이나 의사결정 추론에만 사용하고, 다양한 사용자 Natural Language Instructions를 유연하게 따르는 capabilities가 부족합니다. 이들 모델은 평균화된 expert policy를 모방하거나 "좌회전", "직진"과 같은 제한된 simple navigational commands에 국한되어, open-ended하고 flexible한 Natural Language Instructions에 generalization하지 못하는 문제점을 가지고 있습니다. 저자들은 이러한 한계를 극복하고 Imitation Driving에서 Instructional Driving으로의 전환을 가능하게 하는 모델의 필요성을 제기합니다. 특히, instruction-based driving을 직접적으로 학습할 경우, high-dimensional visual-instruction inputs과 low-dimensional action prediction 간의 상당한 정보 불균형으로 인해 모델이 feasible한 trajectories를 생성하고 instructions를 정확히 따르는 데 어려움을 겪는다는 것을 발견했습니다.
3. Method & Key Results
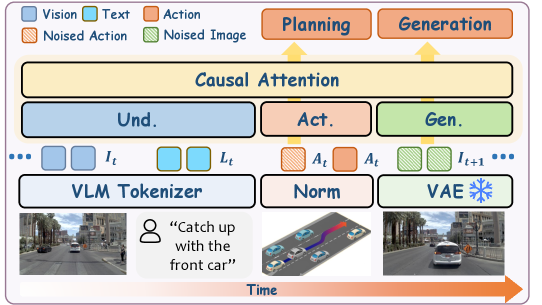
저자들은 Natural Language Instructions 기반의 Generation 및 Planning을 위해 Vega 라는 unified vision-language-world-action model을 제안합니다. Vega는 과거 observations와 language instructions를 조건으로 미래 image generation과 action planning을 jointly 수행하도록 훈련됩니다. 이 joint modeling은 예측 간의 consistency를 강화하여 mutual supervision 및 refinement를 가능하게 합니다. 모델은 autoregressive-diffusion transformer architecture를 채택하여 unified vision-language understanding, world modeling, action planning을 달성합니다. 특히, visual 및 instruction understanding에는 autoregressive pipeline을, image 및 action generation에는 diffusion pipeline을 사용합니다. 또한, 모든 modality 간의 상호작용을 위해 joint attention을 사용하며, Mixture-of-Transformers (MoT) 설계를 적용하여 각 modality와 관련된 parameters를 효과적으로 decoupling하고 joint generation 및 planning을 위한 모델 capacity를 향상시킵니다 [cite: 1, Figure 3].
실험 결과, Vega는 NAVSIM v2 벤치마크에서 SOTA와 견줄만한 86.9 EPDMS 를 달성했으며, best-of-N 전략을 사용했을 때 89.4 EPDMS 로 여러 metrics에서 최상위 성능을 보였습니다 [cite: 1, Table 1]. 특히 Driving Direction Compliance , Traffic Light Compliance , Lane Keeping , History Comfort 와 같은 metrics에서 SOTA methods를 능가했습니다 [cite: 1, Table 1]. 이는 Vega가 robust한 instruction following capabilities를 학습했으며, future image prediction training의 이점을 얻었음을 시사합니다. NAVSIM v1 벤치마크에서는 87.9 PDMS 를 달성했으며, best-of-N 전략을 통해 89.8 PDMS 로 개선되었습니다 [cite: 1, Table 2]. Ablation study는 future frame prediction task가 모델의 planning capabilities를 향상시키지만, 어떤 미래 프레임을 선택하는지는 성능에 제한적인 영향을 미친다는 것을 보여주었습니다 [cite: 1, Table 3]. Interleaving image-action sequences를 사용하는 것이 모델이 dynamics를 학습하는 데 도움이 되어 더 빠른 convergence와 낮은 loss를 가져온다는 점도 확인되었습니다 [cite: 1, Figure 4].
4. Conclusion & Impact
본 논문은 다양한 Natural Language Instructions를 따르지 못하는 기존 자율주행 모델의 한계를 해결하기 위해 Vega 를 제안합니다. Vega는 future visual generation을 dense supervision signal로 활용하는 unified vision-language-world-action model로, instructions, actions, 그리고 visual outcomes 간의 causal relationships를 학습합니다. Instruction-annotated dataset과 integrated transformer architecture를 기반으로, Vega는 SOTA planning performance를 달성하며 visual generation과 action planning 모두에서 강력한 instruction-following capabilities를 보여줍니다. 이 연구는 보다 intelligent하고 personalized된 driving systems의 가능성을 열며, 자율주행 분야에서 Natural Language Instructions를 통한 사용자 상호작용 및 유연한 주행 행동 구현에 중요한 진전을 이끌어낼 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks
- 현재글 : [논문리뷰] Vega: Learning to Drive with Natural Language Instructions
- 다음글 [논문리뷰] Voxtral TTS
댓글