[논문리뷰] SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks
링크: 논문 PDF로 바로 열기
저자: Gabriel Orlanski, Devjeet Roy, Alexander Yun, Changho Shin, Alex Gu, Albert Ge, Dyah Adila, Frederic Sala, Aws Albarghouthi
1. Key Terms & Definitions (핵심 용어 및 정의)
- SlopCodeBench : Agent가 변화하는 Specification 하에서 자신의 이전 Solution 을 반복적으로 확장할 때 Code Quality 가 어떻게 진화하는지 측정하기 위한 Language-agnostic Benchmark 이다. 총 20개 의 Problem과 93개 의 Checkpoint로 구성된다.
- Structural Erosion : Codebase의 전체 Complexity Mass 중 High-Complexity Functions 에 집중된 비율을 나타내는 Metric이다. 각 Callable의 Cyclomatic Complexity (CC) 와 Source Lines of Code (SLOC) 를 기반으로 계산되며, CC가 10 을 초과하는 함수에 집중된 Complexity Mass의 비율로 정의된다.
- Verbosity : Codebase 내의 중복되거나 불필요한 Code Lines의 비율을 측정하는 Metric이다. AST-Grep Rules 를 통한 불필요한 Code Pattern 감지 및 Structural Duplication (Clone Lines / LOC)을 통해 산출된다.
- Iterative Coding : Agent가 초기 Design Decisions 의 Cost를 스스로 감당하며, 이전 Solution 을 기반으로 Code를 지속적으로 확장 및 수정하는 방식의 Software Development 프로세스를 의미한다. 이는 Long-Horizon Tasks 에서 Architectural Decisions 의 중요성을 강조한다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존 Coding Agent Benchmark 들은 압도적으로 Single-shot Solutions 을 Complete Specification에 대해 평가하고 있으며, 이는 Agent가 현재 Specification 에 대한 Correct Code 를 생성할 수 있는지 여부만을 측정한다. 그러나 이러한 방식은 Code가 향후 변경 사항에 대해 얼마나 Extensible 한지, 즉 Extension Robustness 를 측정하지 못하는 한계점을 가지고 있다. 반복적인 수정 과정에서 Agent가 생성한 Code는 종종 Verbose 해지거나 Anti-patterns 를 축적하여 품질이 저하되는 경향이 있다. 이러한 저품질, 고볼륨의 Code는 Slop 으로 불리며, 전통적인 Software Engineering에서는 높은 유지보수 비용과 느린 수정 속도와 연관되어 있지만, Pass Rate 는 안정적으로 유지될 수 있어 기존 Pass-rate-centric Benchmark로는 이러한 현상을 포착하기 어렵다.
저자들은 Agent가 자신의 초기 Design Decisions 에 대한 Cost를 감당하며 장기적인 관점에서 반복적으로 Code를 확장하는 시나리오에서 Code Quality 변화를 정확히 측정할 수 있는 새로운 Benchmark 의 필요성을 제기한다. 기존의 Multi-turn 또는 Long-horizon Coding Benchmark 들조차 Agent Design Decisions 를 너무 엄격하게 제약하거나, Agent가 자신의 초기 Design Decisions 의 결과에 직면하지 않도록 Gold-standard Code 를 제공하여 True Iterative Coding 을 제대로 측정하지 못한다. 따라서 Internal Interfaces 를 규정하지 않고, Test Suite 를 숨기며, Black-box, Language-agnostic 한 문제 설계를 통해 Agent의 Architectural Decisions 가 직접 평가 대상이 되고 Quality Degradation 이 관찰될 수 있는 Benchmark가 필요하다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Agent가 변화하는 Specification 하에서 자신의 이전 Solution 을 반복적으로 확장할 때 Code Quality 가 어떻게 진화하는지 측정하기 위한 SlopCodeBench (SCBench) 를 제안한다. SCBench는 20개 의 Problem과 93개 의 Checkpoint로 구성된 Language-agnostic Benchmark 이다. 각 Checkpoint는 CLI 또는 API Boundary에서의 Observable Behavior 만을 명시하여 Internal Structure 를 제약하지 않으며, Test Suite 는 Agent에게 숨겨져 있다.
SCBench는 Correctness 외에 두 가지 Trajectory-level Quality Signals 을 추적한다: Verbosity 는 중복되거나 불필요한 코드의 비율을 측정하고, Structural Erosion 은 Cyclomatic Complexity (CC) 와 Source Lines of Code (SLOC) 를 기반으로 Complexity가 높은 함수에 Complexity Mass가 집중되는 정도를 측정한다.
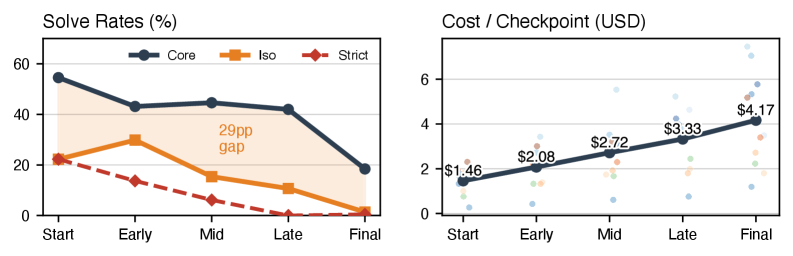
실험 결과, 11개 모델 중 어떤 Agent도 20개 의 Problem을 End-to-End 로 완전히 해결하지 못했으며, 가장 높은 Checkpoint Strict Solve Rate 는 Opus 4.6 의 17.2% 에 불과했다. Quality Degradation 은 꾸준히 발생하여, Erosion 은 Trajectory의 80% 에서, Verbosity 는 89.8% 에서 증가했다. 특히, Checkpoint가 진행됨에 따라 Core Test 통과율과 Isolated Pass Rate 사이의 간격이 크게 벌어졌으며, Strict Solve Rate 는 최종 Checkpoint에서 0.5% 까지 급격히 하락했다 [Figure 2, cite: 5]. 또한, Checkpoint당 평균 Cost 는 초기 대비 최종 Progress Bin 에서 2.9배 증가했지만, 이러한 추가 비용이 Correctness 개선으로 이어지지는 않았다 [Figure 2, cite: 5].
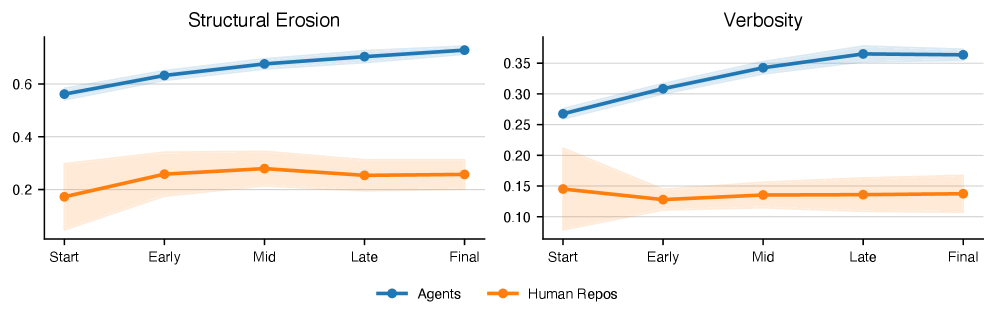
인간이 유지보수하는 48개 오픈소스 Python Repository와의 비교 연구에서, Agent Code는 인간 Code 대비 2.2배 더 Verbose 하고 훨씬 더 Eroded 된 것으로 나타났다. Erosion 측면에서는 Agent가 Complexity Mass의 0.68±0.20 을 High-CC Function에 집중시킨 반면, 인간 Repository는 0.31±0.12 에 그쳤다. Verbosity 는 Agent가 0.33±0.10 인 반면, 인간 Code는 0.15±0.06 이었다. 시간 경과에 따른 변화를 보면, 인간 Code의 Quality Metric은 Plateau 를 유지하는 반면, Agent Code는 각 Iteration 마다 Monotonically 악화되는 경향을 보였다 [Figure 4, cite: 7].
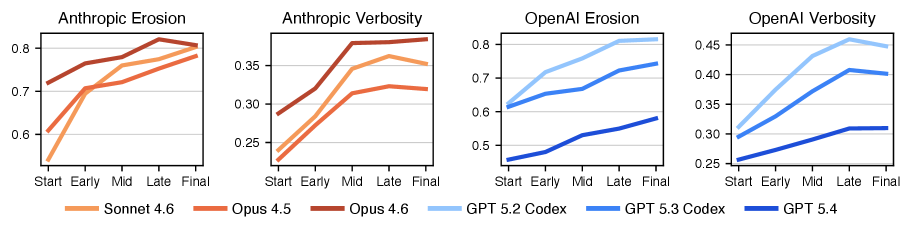
Prompt Intervention Study 에서는 Quality-aware Prompts (anti_slop, plan_first)가 초기 Verbosity 와 Erosion 을 감소시키는 데 효과적이었지만, Degradation Rate 자체를 늦추거나 Pass Rate 를 개선하지 못했다 [Figure 5, cite: 8]. 예를 들어, GPT 5.4 모델에 anti_slop Prompt를 적용했을 때 초기 Verbosity 는 34.5% 감소했지만, Correctness Metrics 에는 유의미한 변화가 없었으며, 오히려 Per-checkpoint Cost 가 47.9% 증가했다. 이는 Prompt가 시작점을 더 깨끗하게 설정할 수 있지만, 일단 Iteration 이 시작되면 Compounding 이 동일한 속도로 재개됨을 시사한다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 SlopCodeBench 를 통해 11개 모델이 20개 의 Iterative Problems 에서 Long-Horizon Iterative Tasks 를 수행할 때 Code Quality 가 심각하게 저하됨을 명확히 입증했다. 어떤 Agent도 Problem을 End-to-End 로 완전히 해결하지 못했으며, Verbosity 는 Trajectory의 90% 에서, Structural Erosion 은 80% 에서 증가하는 경향을 보였다. 이러한 Quality Degradation 패턴은 인간이 유지보수하는 Repository의 Code Evolution과는 뚜렷한 차이를 보이며, Prompt-side Interventions 는 초기 품질을 개선할 수 있었으나 Degradation Rate 자체를 늦추는 데는 실패했다.
이 연구는 기존의 Pass-rate-centric Benchmark 들이 Test Suite가 Structural Decay 를 인식하지 못하기 때문에 Agent의 Extension Robustness Failure Mode 를 체계적으로 과소평가하고 있다는 중요한 사실을 지적한다. 이는 현재의 Agent들이 Iterative Software Development에 필수적인 Design Discipline 이 부족함을 보여준다. 즉각적인 다음 연구 과제는 이러한 Code Quality Degradation을 단순히 지연시키는 것을 넘어, 어떻게 멈추게 할 수 있는지 탐구하는 것이 될 것이다. Structural Discipline 을 Checkpoint 전반에 걸쳐 강제하는 Training Time 또는 Tooling 기반의 Intervention 이 향후 연구의 중요한 방향이 될 것으로 보인다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SWE-EVO: Benchmarking Coding Agents in Long-Horizon Software Evolution Scenarios
- [논문리뷰] OdysseyArena: Benchmarking Large Language Models For Long-Horizon, Active and Inductive Interactions
- [논문리뷰] The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution
- [논문리뷰] OmniOpt: Taxonomy, Geometry, and Benchmarking of Modern Optimizers
- [논문리뷰] Dockerless: Environment-Free Program Verifier for Coding Agents
Review 의 다른글
- 이전글 [논문리뷰] S2D2: Fast Decoding for Diffusion LLMs via Training-Free Self-Speculation
- 현재글 : [논문리뷰] SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks
- 다음글 [논문리뷰] Vega: Learning to Drive with Natural Language Instructions
댓글