[논문리뷰] S2D2: Fast Decoding for Diffusion LLMs via Training-Free Self-Speculation
링크: 논문 PDF로 바로 열기
저자: Ligong Han, Hao Wang, Han Gao, Kai Xu, Akash Srivastava et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Block-diffusion language models (Block-diffusion LMs) : 블록 단위의 Autoregressive (AR) 생성과 블록 내 병렬 denoising을 결합하여 기존 AR 모델보다 빠른 생성을 목표로 하는 언어 모델.
- Self-Speculative Decoding : 단일 모델이 'drafter' (토큰 제안)와 'verifier' (제안 검증) 두 가지 역할을 수행하여 생성 속도를 높이면서도 목표 모델 분포를 유지하는 기법.
- Training-Free : 추가적인 모델 학습이나 fine-tuning 없이 기존 모델의 추론 단계에서 성능 향상을 달성하는 접근 방식.
- Routing Policies : S2D2 프레임워크 내에서 추론 비용과 예상되는 이득을 고려하여 speculative verification 단계를 언제 호출할지 결정하는 경량 메커니즘.
- Residual Energy : AR 검증 분포(verifier probability)와 diffusion 제안 분포(drafter probability) 간의 불일치를 정량화하는 개념으로, speculative acceptance 결정에 중요한 역할을 함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 언어 모델링 분야에서 큰 발전을 이끈 Autoregressive (AR) 모델들은 엄격한 좌-우향 생성 방식 때문에 디코딩 유연성과 추론 병렬성에서 한계를 가진다. 이러한 문제점을 해결하기 위해 블록 단위의 AR 디코딩과 블록 내 병렬 denoising을 결합한 Block-diffusion language models 가 제안되었으며, 이는 AR 모델보다 빠른 생성 잠재력을 제공한다. 그러나 실제적인 가속화를 위해 필요한 few-step regime 에서는 기존의 confidence-thresholded decoding 방식이 brittle 한 경향을 보인다: aggressive한 threshold는 결과 품질을 저하시키고, conservative한 threshold는 불필요한 denoising step을 유발하여 비효율적이다. 이 문제를 해결하려는 기존 접근 방식들은 대부분 추가적인 모델 학습이 필요하거나, 추론 시점에 불필요한 연산 오버헤드를 발생시킨다. 따라서 저자들은 추가적인 학습 없이, 추론 시점에 AR 구조를 활용하면서도 블록-diffusion의 병렬성을 유지하여 속도를 최우선으로 개선하는 방법을 모색하였다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
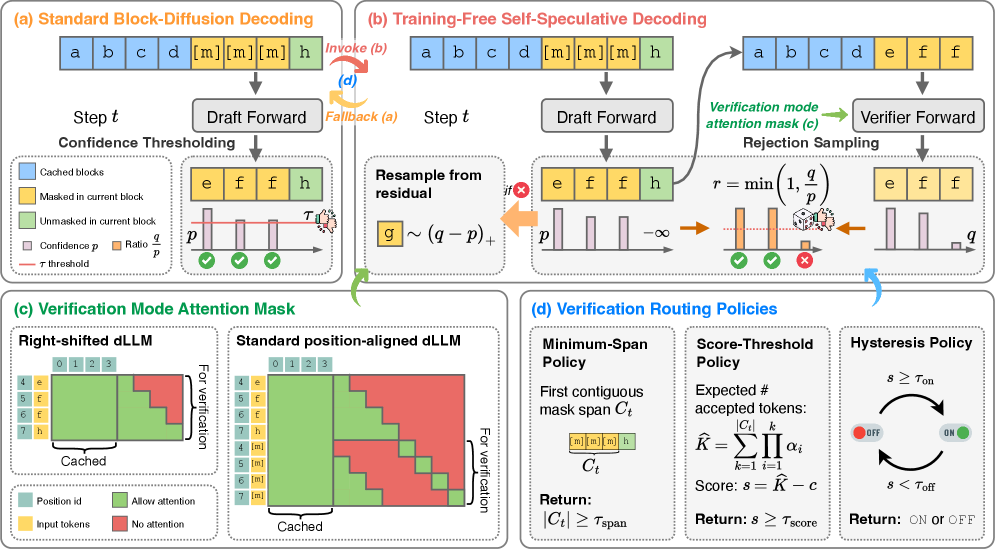
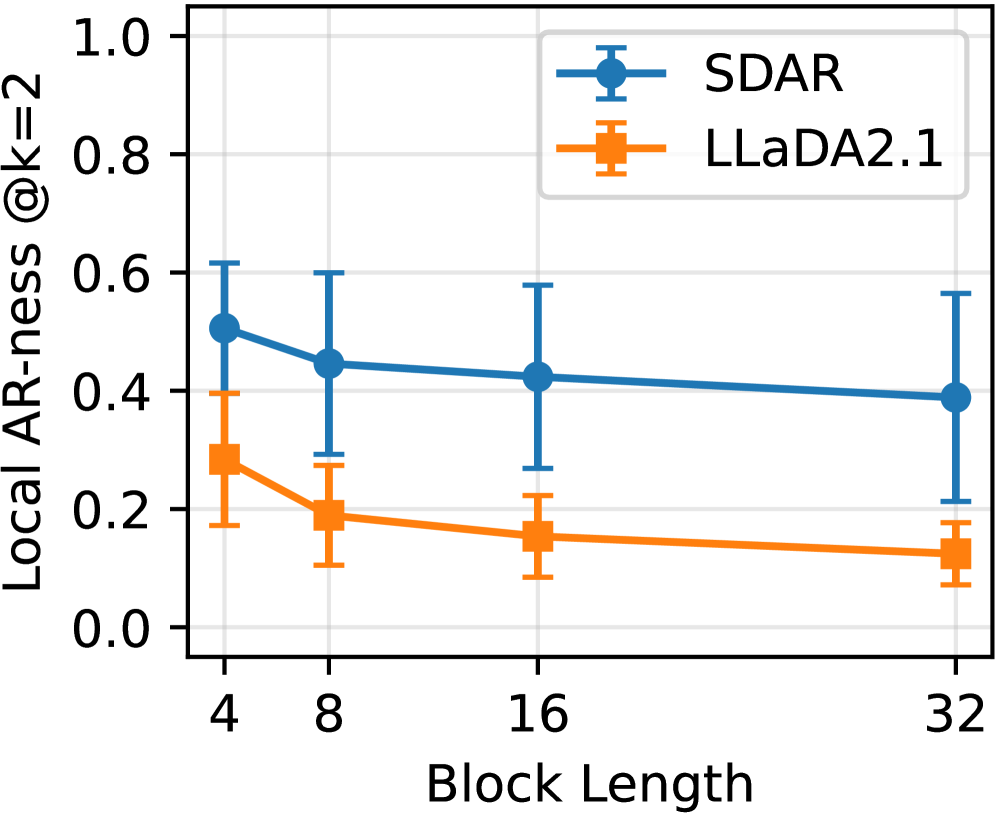
저자들은 Block-diffusion LMs 의 빠른 디코딩을 위해 S2D2 (Training-Free Self-Speculation for Diffusion LLMs) 프레임워크를 제안한다. 핵심 아이디어는 블록 크기(block size)를 1로 줄이면 블록-diffusion 모델이 Autoregressive 하게 작동한다는 관찰에서 시작한다. 이 점을 활용하여, 동일하게 사전 학습된 블록-diffusion 모델을 'drafter' (표준 블록-diffusion 디코딩)와 'verifier' (블록 크기 1의 AR 모드)의 두 가지 역할로 재사용하여 추가적인 학습 없이 self-speculative decoding을 가능하게 한다 [cite: 1, Figure 1]. S2D2는 표준 블록-diffusion 디코딩 과정에 speculative verification 단계를 삽입하며, verifier와 drafter 확률 간의 비율을 기반으로 rejection sampling 을 통해 토큰을 수락한다. 이 과정에서 검증 작업이 추가적인 forward pass 를 필요로 하므로, 저자들은 검증의 이점이 비용을 상쇄하는 경우에만 이를 호출하도록 Minimum-span , Score-threshold , Hysteresis 와 같은 경량 Routing Policies 를 사용한다 [cite: 1, Figure 1]. 이는 diffusion이 토큰을 병렬로 제안하는 동시에 AR 모드가 local sequence-level critic 역할을 하는 하이브리드 디코딩 궤적을 생성한다.
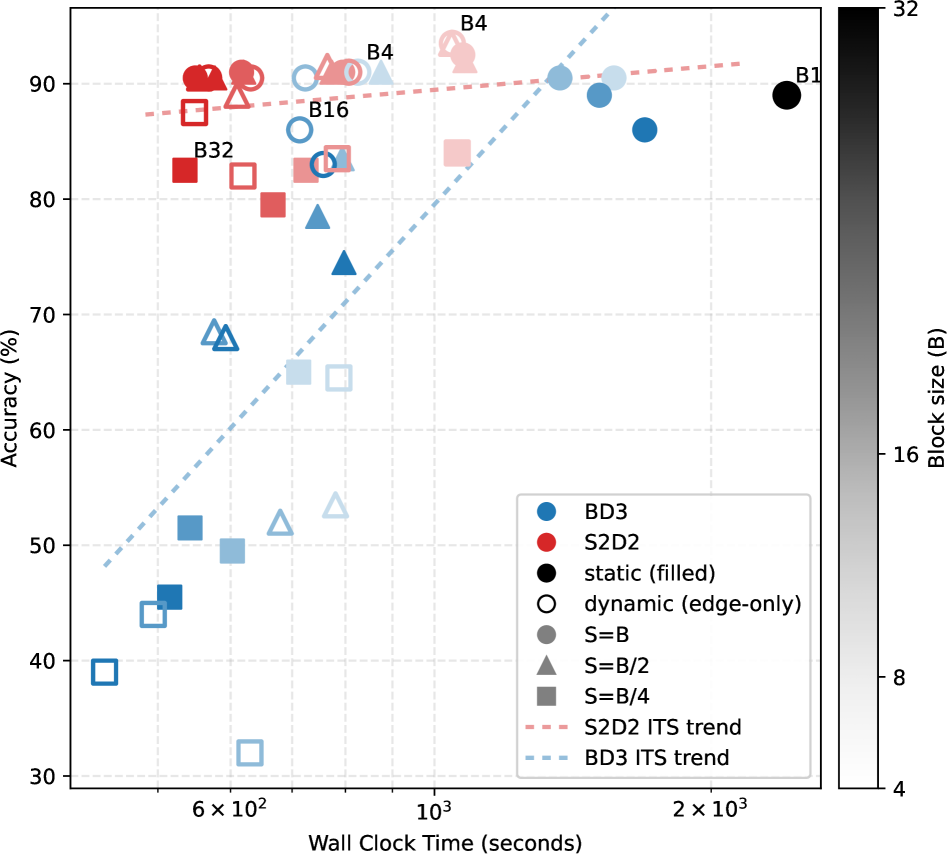
실험 결과, S2D2는 세 가지 주요 Block-diffusion 모델 계열에 걸쳐 강력한 confidence-thresholding baseline 대비 일관되게 accuracy–speed tradeoff 를 개선했다. SDAR-1.7B 모델에서는 S2D2 (config-B)가 AR 디코딩 대비 최대 4.7배 의 속도 향상, 그리고 튜닝된 dynamic decoding baseline 대비 약 1.57배 의 속도 향상을 보이며 평균 정확도를 4.5점 (48.4%에서 52.9%) 향상시켰다 [cite: 1, Table 1]. Fast-dLLM v2 (config-C, SB=32)에서는 S2D2가 dynamic decoding보다 약 1.07배 빨랐으며, 평균 정확도는 4.5점 개선되었다 [cite: 1, Table 2]. LLaDA2.1-Mini 의 conservative setting 에서는 S2D2가 static baseline보다 4.4배 빨랐고, 정확도도 소폭 (0.6점) 높았다 [cite: 1, Table 3]. 특히, S2D2는 표준 diffusion 디코딩이 불안정한 대규모 블록(large-block) 환경에서 flatter inference-time scaling 과 더 나은 accuracy-speed frontier 를 달성했다 [cite: 1, Figure 3].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 단일 사전 학습된 Block-diffusion 모델을 drafter 및 블록 크기 1의 AR verifier로 재사용하는 Training-Free Self-Speculative Decoding 프레임워크인 S2D2를 제시했다. 이 plug-and-play 설계는 여러 Block-diffusion 모델에서 accuracy–speed tradeoff 를 일관되게 개선하며, 기존의 강력한 dynamic confidence-thresholding baseline 보다 높은 정확도와 낮은 latency 를 제공한다. 저자들은 speculative verification 이 local sequence-level correction mechanism 으로 작용하며, autoregressive energy correction 의 stochastic, greedy 형태로 해석될 수 있음을 분석을 통해 보여주었다 [cite: 1, Figure 2]. 이러한 관점은 향후 diffusion language models 를 위한 추가적인 training-free inference-time methods 개발에 중요한 시사점을 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Nemotron-Labs-Diffusion: A Tri-Mode Language Model Unifying Autoregressive, Diffusion, and Self-Speculation Decoding
- [논문리뷰] MultAttnAttrib: Training-Free Multimodal Attribution in Long Document Question Answering
- [논문리뷰] When LLMs Read Tables Carelessly: Measuring and Reducing Data Referencing Errors
- [논문리뷰] QVal: Cheaply Evaluating Dense Supervision Signals for Long-Horizon LLM Agents
- [논문리뷰] PhotoQuilt: Training-Free Arbitrary-Resolution Photomosaics via Bootstrapped Tiled Denoising
Review 의 다른글
- 이전글 [논문리뷰] Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
- 현재글 : [논문리뷰] S2D2: Fast Decoding for Diffusion LLMs via Training-Free Self-Speculation
- 다음글 [논문리뷰] SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks
댓글