[논문리뷰] BEAVER: A Training-Free Hierarchical Prompt Compression Method via Structure-Aware Page Selection
링크: 논문 PDF로 바로 열기
저자: Zhengpei Hu, Kai Li, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- LLMs (Large Language Models) : 방대한 텍스트 데이터를 학습하여 인간과 유사한 언어를 이해하고 생성하는 대규모 인공지능 모델.
- Context Window : LLM이 한 번에 처리하고 추론할 수 있는 입력 텍스트의 최대 길이.
- Prompt Compression : LLM 입력 프롬프트의 길이를 줄여
inference latency를 감소시키고throughput을 향상시키면서도 핵심 정보를 보존하는 기술. - Training-Free : 특정 작업이나 데이터셋에 대한 추가적인 모델 훈련이나
fine-tuning없이 작동하는 방법론. - ITF (Inverse Term Frequency) : BEAVER에서 사용되는
in-context가중치 부여 방식으로, 문맥 내에서 자주 나타나지만 정보 가치가 낮은 토큰의 중요도를 낮추는 데 활용됨.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 LLMs의 context window가 기하급수적으로 확장되면서 long-document understanding의 잠재력이 커졌지만, 이는 심각한 inference latency와 정보 utilization 병목 현상을 야기했습니다. 기존 prompt compression 방법론들은 높은 training costs를 수반하거나, 공격적인 token pruning으로 인해 semantic fragmentation을 초래하는 한계점을 가지고 있었습니다. 이러한 문제들은 단순히 context length를 늘리는 것만으로는 robustness를 보장할 수 없으며, 효율성과 정확성 간의 균형을 맞출 수 있는 새로운 패러다임이 필요함을 시사합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
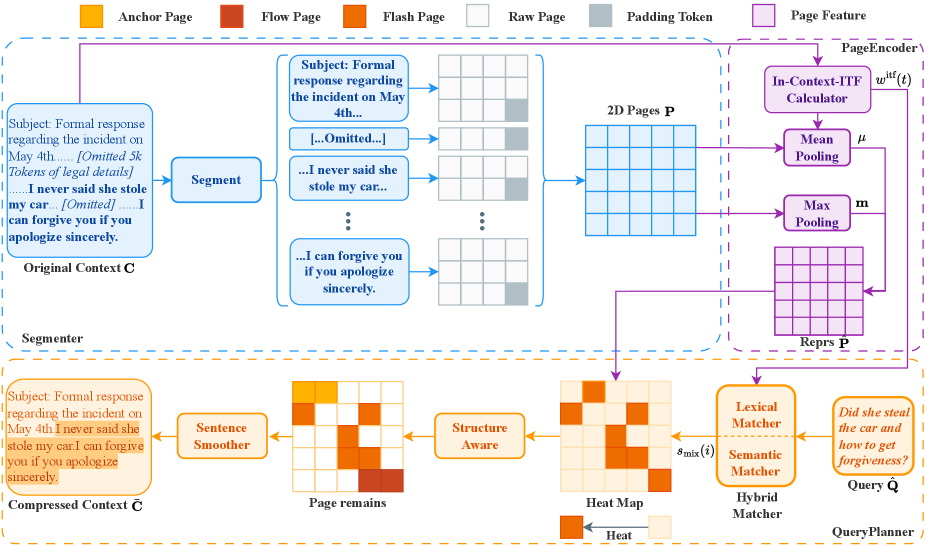
저자들은 이러한 한계를 극복하기 위해 BEAVER라는 새로운 training-free 프레임워크를 제안합니다. BEAVER는 선형적인 token removal 방식에서 structure-aware hierarchical selection 방식으로 전환하여 prompt compression을 수행합니다 [cite: 1, Figure 2]. 이 프레임워크는 세 가지 주요 구성 요소로 이루어져 있습니다. 첫째, Segmenter 는 가변 길이의 시퀀스를 semantic delimiters (예: 개행 문자)를 기반으로 논리적인 page tensors로 분할하여 GPU efficiency를 최적화하고 discourse integrity를 보존합니다. 둘째, PageEncoder 는 dual-path pooling (가중 평균 및 최대 풀링)과 context-statistics-adaptive weighting mechanism (in-context ITF)을 사용하여 hierarchical features를 효과적으로 포착합니다. 셋째, QueryPlanner 는 semantic 및 lexical dual-branch selection과 세 가지 structural priors (Anchors, Flow, Flash)를 통합하여 saliency mask를 생성하며, semantic drift를 억제합니다. 마지막으로, sentence-level smoothing 메커니즘을 적용하여 선택된 span을 가장 가까운 문장 경계까지 확장함으로써 syntactic completeness를 보장합니다 [cite: 1, Figure 3].
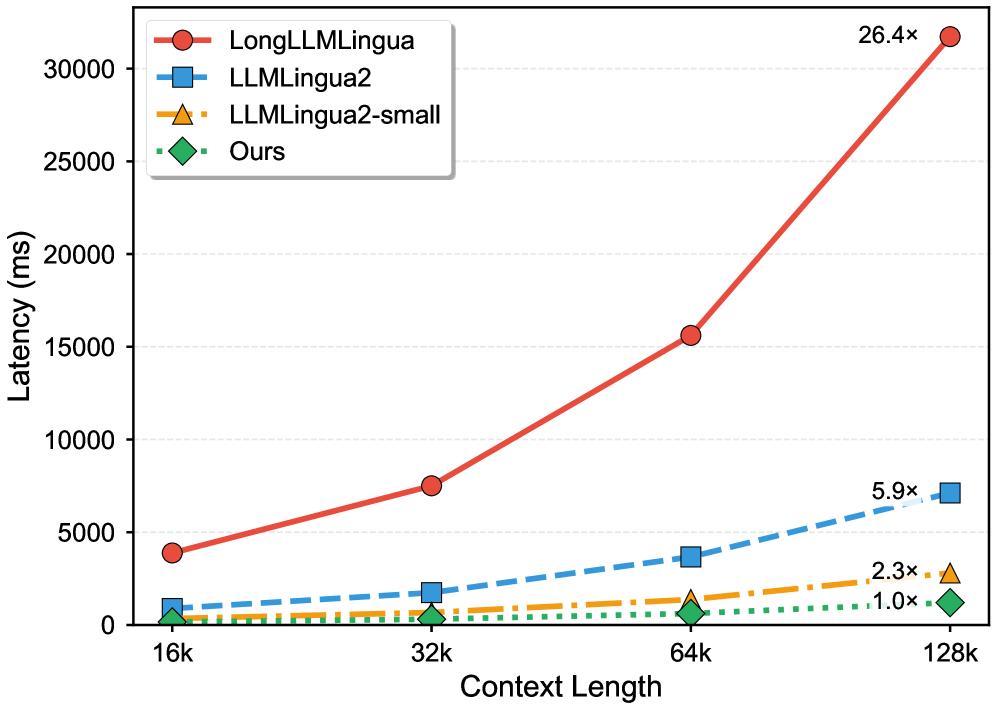
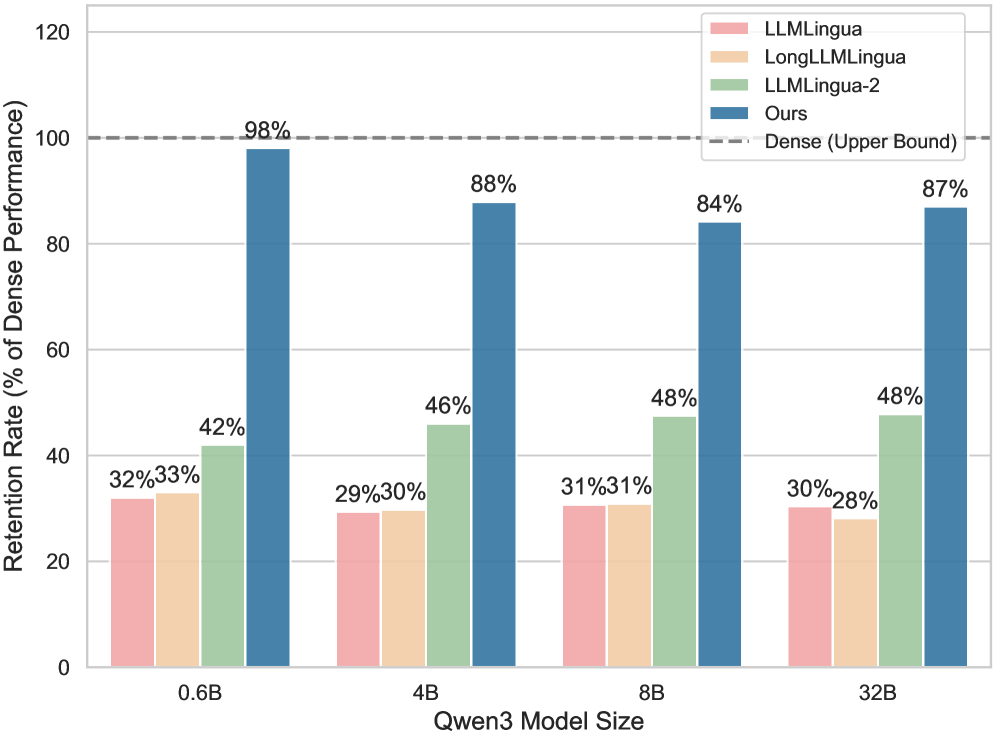
실험 결과 BEAVER는 네 가지 long-context benchmarks (LongBench, ZeroSCROLLS, RULER, L-Eval)에서 LongLLMLingua 및 LLMLingua-2와 같은 SOTA 방법론들과 비교하여 comparable하거나 superior performance를 달성했습니다. 특히, RULER benchmark에서는 multi-needle retrieval task에서 LLMLingua-2의 47.9 대비 83.7의 평균 점수를 기록하며 기존 baselines를 크게 능가하는 robustness를 보였습니다 [cite: 1, Table 2]. efficiency 측면에서는 128k contexts에서 LongLLMLingua 대비 26.4x의 latency speedup을 달성했으며, LLMLingua-2 및 LLMLingua-2-small 대비 각각 5.9x 및 2.3x의 speedup을 보였습니다 [cite: 1, Figure 4]. 또한, BEAVER는 training-free 특성 덕분에 Qwen3 series (0.6B–32B)에 걸쳐 84%–98%의 일관된 performance retention을 보여 model scalability 분석에서 LLMLingua-2 (42%) 및 LongLLMLingua (33%)를 크게 앞섰습니다 [cite: 1, Figure 5].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 long-context LLMs의 computational 및 memory bottlenecks를 해결하기 위한 hardware-efficient 및 training-free prompt compression 프레임워크인 BEAVER를 제안합니다. BEAVER는 hierarchical segment-page mechanism을 통해 불규칙한 시퀀스 압축을 최적화된 tensor operations로 전환하며, unsupervised in-context ITF weighting과 structure-aware hybrid planner를 활용하여 global semantics와 fine-grained lexical details를 효과적으로 보존합니다. 실험 결과, BEAVER는 question answering 및 fine-grained retrieval에서 SOTA performance를 확립하고 summarization tasks에서 높은 fidelity를 유지하는 것으로 나타났습니다. 특히 128k contexts에서 26.4x의 뛰어난 speedup을 제공하며 우수한 scalability를 입증했습니다. BEAVER는 parameter updates가 필요 없는 plug-and-play module로서, 효율적인 large-scale long-document understanding을 위한 실용적이고 robust한 기반을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MultAttnAttrib: Training-Free Multimodal Attribution in Long Document Question Answering
- [논문리뷰] QVal: Cheaply Evaluating Dense Supervision Signals for Long-Horizon LLM Agents
- [논문리뷰] PhotoQuilt: Training-Free Arbitrary-Resolution Photomosaics via Bootstrapped Tiled Denoising
- [논문리뷰] IV-CoT: Implicit Visual Chain-of-Thought for Structure-Aware Text-to-Image Generation
- [논문리뷰] CAVEWOMAN: How Large Language Models Behave Under Linguistic Input and Output Compression
Review 의 다른글
- 이전글 [논문리뷰] Astrolabe: Steering Forward-Process Reinforcement Learning for Distilled Autoregressive Video Models
- 현재글 : [논문리뷰] BEAVER: A Training-Free Hierarchical Prompt Compression Method via Structure-Aware Page Selection
- 다음글 [논문리뷰] Beyond Single Tokens: Distilling Discrete Diffusion Models via Discrete MMD
댓글