[논문리뷰] Astrolabe: Steering Forward-Process Reinforcement Learning for Distilled Autoregressive Video Models
링크: 논문 PDF로 바로 열기
저자: Songchun Zhang, Zeyue Xue, et al.
1. Key Terms & Definitions
- Distilled Autoregressive (AR) Video Models : 미리 학습된
bidirectional video diffusion models에서 지식을 증류(distillation)하여 효율적인streaming generation을 가능하게 하는 모델입니다.KV-caching을 활용하여 실시간long video generation을 지원합니다. - Forward-Process Reinforcement Learning (RL) :
reverse-process unrolling없이clean generated samples에 보상(rewards)을 직접 적용하여diffusion models를 최적화하는trajectory-freeRL접근 방식입니다. - Rolling KV Cache :
streaming generation에서 메모리 사용량을bound하기 위해 사용되는 메커니즘으로,global semantic context를 유지하는frame sink와local conditioning을 제공하는rolling window로 구성됩니다. - Multi-reward Formulation :
visual quality (VQ),motion quality (MQ),text-video alignment (TA)등 여러 품질 차원(quality dimensions)을 통합하여scalar reward functions의 한계와reward hacking을 완화하는 복합적인 보상 체계입니다. - Uncertainty-Aware Selective Regularization :
reward hacking을 방지하기 위해KL penalty를auxiliary consensus가 부족한 (즉, 불확실성이 높은) 샘플에만 선택적으로 적용하는 전략으로,high-quality generations의optimization freedom을 보존합니다.
2. Motivation & Problem Statement
Distilled autoregressive (AR) video models는 efficient streaming generation을 가능하게 하지만, 종종 human visual preferences와 misalign되어 artifacts나 unnatural motion dynamics를 보입니다. 기존 Reinforcement Learning (RL) 프레임워크는 이러한 AR architectures에 적합하지 않다는 문제가 있습니다. 특히, reverse-process RL은 re-distillation이나 solver-coupled optimization이 필요하며, 이는 상당한 memory 및 computational overhead를 발생시켜 streaming models의 efficiency advantages를 상쇄합니다. 또한, long video generation 시 sequence-level rollouts는 temporal credit assignment problem과 prohibitive memory overhead를 야기하여 scalable exploration을 어렵게 합니다.
3. Method & Key Results
저자들은 distilled AR video models를 human preferences에 맞춰 정렬하기 위한 efficient하고 stable online RL framework인 Astrolabe 를 제안합니다
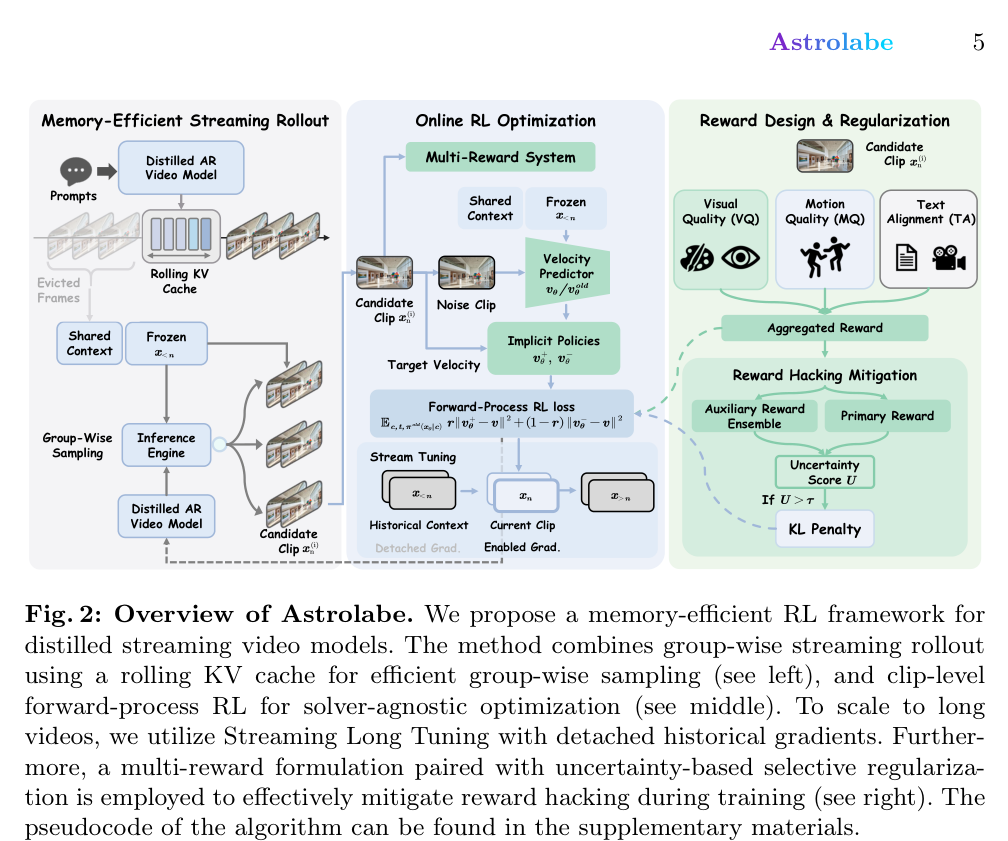
이 방법론은 여러 핵심 요소를 포함합니다. 첫째, trajectory-free alignment strategy를 도입하여 reverse-process unrolling 없이 inference endpoints에서 positive 및 negative generations를 contrast함으로써 implicit policy improvement direction을 설정합니다. 둘째, memory-efficient streaming rollout을 위해 rolling KV cache와 frame sinks를 사용하여 long videos에 대한 scalable exploration을 가능하게 합니다. RL updates는 local clip windows에만 적용되며, prior context를 conditioning하여 long-range coherence를 유지합니다. 셋째, reward hacking을 방지하기 위해 Visual Quality (VQ) (측정: HPSv3 ), Motion Quality (MQ) (측정: VideoAlign ), Text-Video Alignment (TA) (측정: VideoAlign )를 통합하는 multi-reward formulation을 사용합니다. 마지막으로, uncertainty-aware selective regularization과 dynamic reference update 메커니즘을 통해 online learning 중 distributional shifts를 stabilize합니다.
실험 결과는 Astrolabe 가 다양한 distilled AR video models에서 generation quality를 일관되게 향상시킴을 보여줍니다. Short-Video Single-Prompt Generation 설정에서,
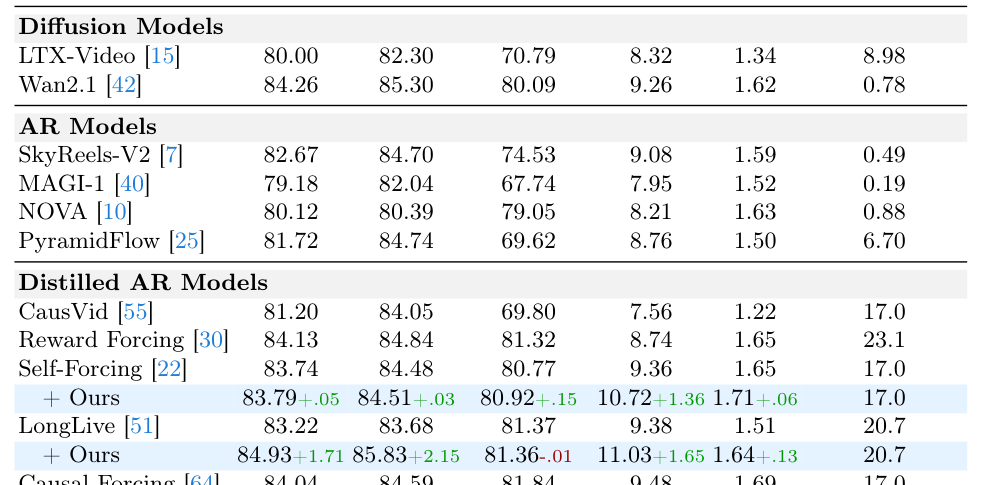
은 Self-Forcing + Ours 가 HPSv3에서 10.72+1.36 을, MQ에서 1.71+.06 을 달성하여 Self-Forcing (HPSv3 9.36 , MQ 1.65 ) 대비 성능 향상을 보였음을 나타냅니다. Long-Video Single-Prompt Generation에서는
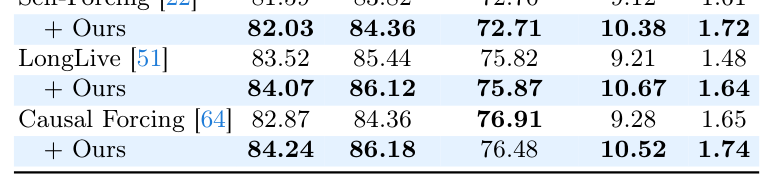
에서 Causal Forcing + Ours 가 HPSv3에서 10.52 를, MQ에서 1.74 를 기록하여 Causal Forcing (HPSv3 9.28 , MQ 1.65 )보다 우수한 성능을 보였습니다. Multi-Prompt Long-Video Generation에서도 [Table 3]에 따르면 LongLive + Ours 가 Quality Score 85.15 로 LongLive 의 84.28 보다 높았으며, 전반적인 generation quality, visual aesthetics, long-range motion consistency를 향상시켰습니다. 이러한 개선은 기존 모델의 inference speed를 유지하면서 달성되었습니다.
4. Conclusion & Impact
Astrolabe 는 distilled autoregressive video models를 human preferences에 맞춰 정렬하기 위한 memory-efficient하고 stable online RL framework입니다. 이 연구는 reverse-process RL의 trajectory storage overhead를 제거하고, streaming training scheme을 통해 long-video scalability를 달성하며, multi-reward formulation과 uncertainty-aware selective KL penalty로 reward hacking을 효과적으로 완화합니다. Astrolabe 는 distilled AR architectures 전반에서 generation quality를 일관되게 향상시켜 robust하고 scalable alignment solution을 제공합니다. 이는 real-time interactive video applications을 위한 efficient streaming video generation 모델의 실용성을 크게 높이는 중요한 기여입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] DreamWorld: Unified World Modeling in Video Generation
- [논문리뷰] Context Forcing: Consistent Autoregressive Video Generation with Long Context
- [논문리뷰] SkyReels-V3 Technique Report
- [논문리뷰] DrivingGen: A Comprehensive Benchmark for Generative Video World Models in Autonomous Driving
- [논문리뷰] VideoAR: Autoregressive Video Generation via Next-Frame & Scale Prediction
Review 의 다른글
- 이전글 [논문리뷰] AgentDS Technical Report: Benchmarking the Future of Human-AI Collaboration in Domain-Specific Data Science
- 현재글 : [논문리뷰] Astrolabe: Steering Forward-Process Reinforcement Learning for Distilled Autoregressive Video Models
- 다음글 [논문리뷰] BEAVER: A Training-Free Hierarchical Prompt Compression Method via Structure-Aware Page Selection
댓글