[논문리뷰] NGM: A Plug-and-Play Training-Free Memory Module for LLMs
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yuwen Qu, Wenhui Dong, Chenyang Si, Caifeng Shan, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- NGM (N-gram Memory): LLM의 사전 학습된 Token Embedding을 활용하여 별도의 학습 과정 없이 로컬 패턴을 기억하고 추론 시 이를 주입하는 plug-and-play 방식의 메모리 모듈입니다.
- Causal N-gram Encoder: 입력 시퀀스의 Token Embedding을 sliding window 방식으로 평균화하여 다중 스케일(multi-scale)의 NN-gram 표현을 생성하는 컴포넌트입니다.
- Cosine-Gated Memory Injector: 디코더의 Hidden State와 N-gram 표현 간의 Cosine Similarity를 측정하고, ReLU 게이팅을 통해 유효한 메모리 신호만을 잔차 연결(residual connection)로 주입하는 메커니즘입니다.
- Residual Alignment: LLM의 Hidden State와 사전 학습된 Embedding 공간이 기하학적으로 일치하는 성질을 이용하여, 별도의 학습 없이도 메모리 신호를 효과적으로 융합할 수 있게 하는 이론적 근거입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM이 추론 시 고유한 로컬 패턴(식별자, 전문 용어, 구문 등)을 재구성하기 위해 과도한 연산 자원을 소모하는 문제를 해결하고자 합니다. 기존의 Conditional Memory 접근법은 학습이 필요한 메모리 테이블이나 별도의 저장소 인프라를 요구하여 유연성과 효율성을 제한합니다. 저자들은 이미 학습된 LLM의 Embedding 공간 자체가 유용한 로컬 메모리 구조를 내재하고 있다는 점에 착안하였습니다 [Figure 1]. 따라서 본 연구는 추가적인 학습이나 파라미터 업데이트 없이, 기존의 사전 학습된 LLM에 직접 적용 가능한 training-free 방식의 메모리 모듈 개발을 목표로 합니다.
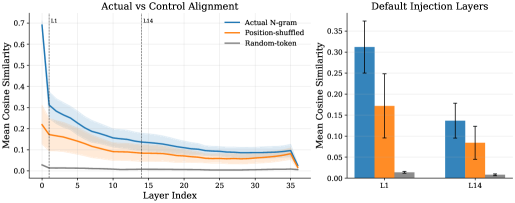
Figure 1 — Hidden state와 N-gram 정렬
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 backbone 모델의 파라미터를 고정한 상태에서 로컬 메모리 신호를 주입하는 NGM 프레임워크를 제안합니다 [Figure 2]. Causal N-gram Encoder는 입력 시퀀스의 Token Embedding을 통해 다양한 스케일의 NN-gram 표현을 생성하며, Cosine-Gated Memory Injector는 이 신호를 ReLU 기반 Cosine Gate로 필터링한 후 모델의 Hidden State에 잔차로 더합니다. 실험 결과, Qwen3 시리즈(0.6B-14B) 전반에서 평균 성능이 +0.5에서 +1.2 포인트 향상되었으며, 특히 코드 생성(LiveCodeBench +3.0) 및 지식 집약적 태스크(GPQA +3.03)에서 뚜렷한 개선을 보였습니다 [Table 1]. 또한, 멀티모달 모델인 Qwen3-VL-2B에서도 추가적인 아키텍처 변경 없이 성능 향상(+1.53 on MMStar)을 입증하였습니다 [Table 2]. 정량적 분석 결과, 메모리 주입 신호는 시퀀스의 로컬 위치에서 가장 강하게 작용하는 것으로 나타났습니다 [Figure 3].
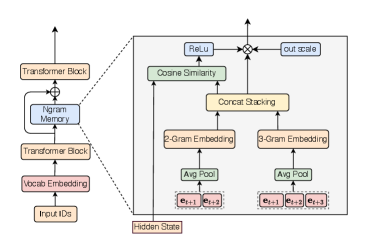
Figure 2 — NGM 전체 아키텍처
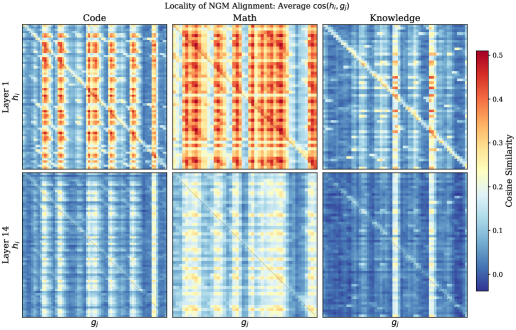
Figure 3 — NGM 상호작용의 로컬리티
4. Conclusion & Impact (결론 및 시사점)
본 논문은 사전 학습된 LLM의 Embedding 공간을 효율적인 로컬 메모리 소스로 재해석한 NGM을 제안하며, 이는 파라미터 추가나 재학습 없이 성능 향상을 달성할 수 있음을 입증하였습니다. 이 연구는 모델의 아키텍처를 변경하지 않고도 추론 성능을 보완할 수 있는 plug-and-play 솔루션을 제공한다는 점에서 실용적 가치가 큽니다. 향후 연구에서는 고정된 게이트 방식의 한계를 보완하기 위해 가벼운 파라미터 기반의 문맥 적응형(context-adaptive) 변형을 고려할 수 있습니다. 본 연구는 LLM의 추론 효율성과 성능 확장을 위한 새로운 sparse lookup 차원을 제시했다는 평가를 받습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Off-the-Shelf LLMs as Process Scorers: Training-Free Alternative to PRMs for Mathematical Reasoning
- [논문리뷰] Darwin Family: MRI-Trust-Weighted Evolutionary Merging for Training-Free Scaling of Language-Model Reasoning
- [논문리뷰] PromptBridge: Cross-Model Prompt Transfer for Large Language Models
- [논문리뷰] Latent Collaboration in Multi-Agent Systems
- [논문리뷰] HiGS: History-Guided Sampling for Plug-and-Play Enhancement of Diffusion Models
Review 의 다른글
- 이전글 [논문리뷰] Monitoring the Internal Monologue: Probe Trajectories Reveal Reasoning Dynamics
- 현재글 : [논문리뷰] NGM: A Plug-and-Play Training-Free Memory Module for LLMs
- 다음글 [논문리뷰] OProver: A Unified Framework for Agentic Formal Theorem Proving
댓글