[논문리뷰] OProver: A Unified Framework for Agentic Formal Theorem Proving
링크: 논문 PDF로 바로 열기
메타데이터
저자: David Ma, Kaijing Ma, Shawn Guo, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- OProver: Lean 4 환경에서 retrieval, compiler feedback, 그리고 iterative repair를 단일 정책으로 통합한 agentic formal theorem proving 프레임워크입니다.
- OProofs: 1.77M개의 Lean statement와 6.86M개의 compiler-verified proof를 포함하며, 증명 과정에서의 failed attempt, feedback, repair trajectory 등을 체계적으로 기록한 학습 데이터셋입니다.
- Agentic Proving: 고정된 모델이 단일 패스로 증명을 생성하는 대신, Lean compiler로부터 feedback을 받아 실패한 증명을 여러 라운드에 걸쳐 수정(refinement)하는 지능형 증명 방식입니다.
- GSPO (Group Sequence Policy Optimization): 증명 성능 향상을 위해 여러 proof attempt를 그룹화하고, 그룹 내 상대적 보상을 정규화하여 학습하는 RL 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 formal theorem proving 시스템이 증명 실패 시의 feedback과 retrieval을 inference-time heuristic으로만 사용하여 학습과 추론 간의 불일치(mismatch)가 발생하는 문제를 해결하고자 합니다. 대다수의 시스템은 최종적으로 검증된 증명만을 학습 데이터로 활용하여, 증명이 수정되는 과정에서 발생하는 중요한 정보들이 활용되지 못하고 있습니다. 결과적으로 학습 단계에서는 compiler feedback을 경험하지 못한 모델이 배포 단계에서 이를 직면하게 되어 성능 최적화가 제한됩니다. 본 연구는 이러한 증명 생성, 실패, 수정의 전 과정을 학습 정책(policy) 내로 통합하여, 모델이 retrieval과 feedback을 능동적으로 활용하도록 설계된 프레임워크를 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 agentic proving을 multi-round refinement loop로 공식화하고, 이를 학습 가능한 정책으로 내재화하는 OProver를 제안합니다 [2.1]. 학습 과정은 세 단계로 구성되는데, 우선 OProofs 데이터셋을 이용한 continued pretraining을 수행하고, 이후 agentic proving rollout, SFT(Supervised Fine-Tuning), RL이 교대로 실행되는 반복적(iterative) post-training 루프를 거칩니다 [2.3]. 이 루프를 통해 증명 모델과 데이터셋인 OProofs가 함께 발전하는 co-evolution 파이프라인을 구축하였습니다 [2.3].
주요 실험 결과, OProver-32B 모델은 MiniF2F (93.3%), ProverBench (58.2%), PutnamBench (11.3%) 벤치마크에서 기존의 모든 open-weight whole-proof prover를 상회하는 최고 수준의 Pass@32 성능을 달성하였습니다 [4.1]. 특히 PutnamBench와 같은 고난도 벤치마크에서 우수한 성과를 거두었으며, 8B 모델조차 기존 32B 모델들을 능가하는 효율성을 입증하였습니다 [4.1]. Ablation study 결과, compiler feedback을 통한 반복적 수정이 성능 향상의 핵심 동력임을 확인하였습니다 [4.4]. [Table 2]
4. Conclusion & Impact (결론 및 시사점)
본 연구는 formal theorem proving을 단순한 생성 문제가 아닌, 증명 환경과의 상호작용을 통한 반복적 정제 과정으로 재정의하였습니다. 제안된 OProver 프레임워크와 OProofs 데이터셋은 retrieval-grounded 및 feedback-conditioned proof revision을 모델의 내재적 정책으로 성공적으로 편입시켰습니다. 이 연구는 formal reasoning 분야에서 데이터 구축과 모델 학습의 co-evolution이 어떻게 성능을 극대화할 수 있는지에 대한 실증적 토대를 마련하였습니다. 향후 복잡한 자동화 증명 및 검증 분야에서 본 프레임워크가 표준적인 접근 방식으로 활용될 것으로 기대됩니다.
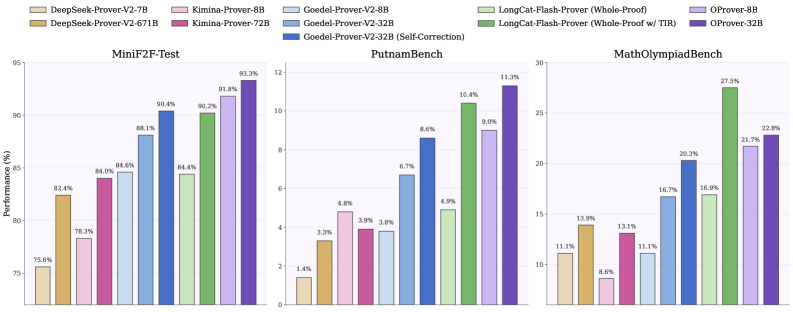
Figure 1 — 벤치마크별 Pass@32 성능 비교
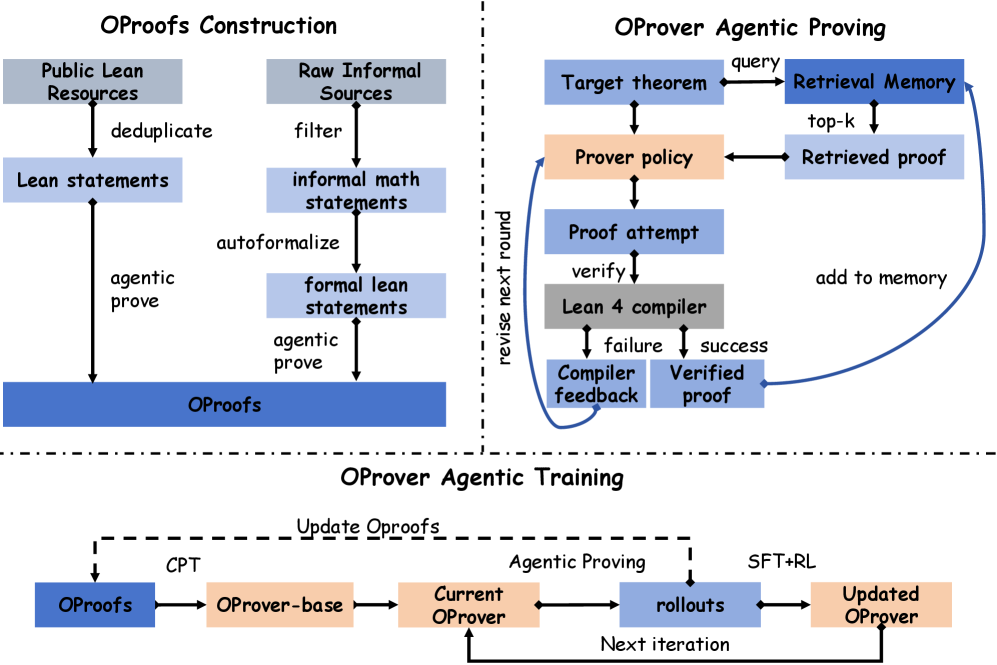
Figure 2 — OProver 프레임워크 아키텍처
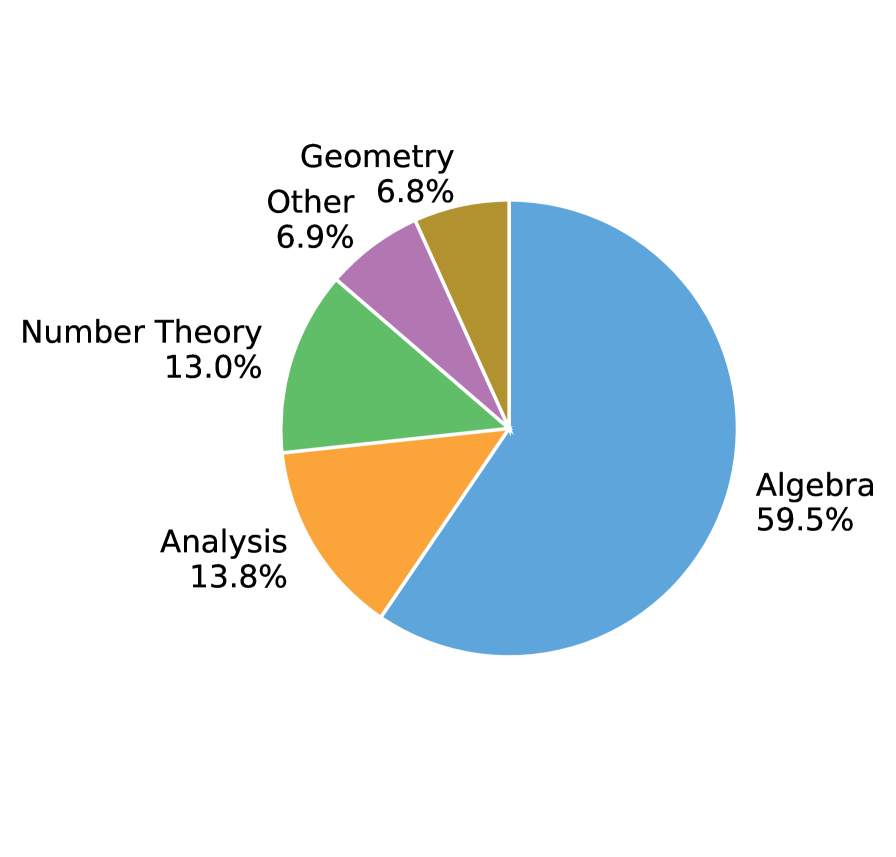
Figure 3 — OProofs 데이터셋 통계
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
- [논문리뷰] Single-Rollout Asynchronous Optimization for Agentic Reinforcement Learning
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] TurnOPD: Making On-Policy Distillation Turn-Aware for Efficient Long-Horizon Agent Training
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
Review 의 다른글
- 이전글 [논문리뷰] NGM: A Plug-and-Play Training-Free Memory Module for LLMs
- 현재글 : [논문리뷰] OProver: A Unified Framework for Agentic Formal Theorem Proving
- 다음글 [논문리뷰] Post-Trained MoE Can Skip Half Experts via Self-Distillation
댓글