[논문리뷰] Beyond Single Tokens: Distilling Discrete Diffusion Models via Discrete MMD
링크: 논문 PDF로 바로 열기
저자: Emiel Hoogeboom, David Ruhe, Jonathan Heek, Thomas Mensink, Tim Salimans
1. Key Terms & Definitions (핵심 용어 및 정의)
- Discrete Diffusion Models (DDMs) : 텍스트나 이미지 픽셀 값과 같은 이산 변수를 생성하도록 학습된 확산 모델. 연속형 변수를 다루는 일반적인 확산 모델과 달리, Uniform diffusion 또는 Masked diffusion과 같이 이산적인 파괴(destruction) 과정을 통해 토큰을 점진적으로 변환하는 방식으로 작동.
- Distillation : 대규모의 복잡한 "Teacher" 모델의 성능을 유지하면서, 더 작고 효율적인 "Student" 모델(Generator)이 더 적은 추론 단계(sampling steps)로 비슷한 또는 더 나은 결과를 생성하도록 학습시키는 과정.
- Moment Matching Distillation (MMD) : Salimans et al. (2024)에 의해 제안된 연속형 확산 모델을 위한 증류 기법으로, 데이터 분포와 distilled generator의 조건부 기대값이 동일하도록 모멘트를 매칭하는 데 중점을 둠.
- Discrete-MMD (D-MMD) : 본 논문에서 제안하는 MMD의 일반화된 형태로, 특히 이산 확산 모델의 증류를 위해 설계됨. MMD의 min-max formulation을 확장하여 이산형 데이터에 적용.
- GPT-2 Gradient Moment (GPT-2 GM) : 이산 확산 모델의 샘플 품질을 평가하기 위해 제안된 새로운 메트릭. Reference AR 모델(예: GPT-2)의 샘플 loss-gradient의 제곱 노름을 측정하여, 생성된 샘플이 학습 데이터와 얼마나 유사한지를 정량화. 낮은 값이 더 좋은 품질을 의미.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Discrete diffusion models는 고품질 데이터를 생성할 수 있지만, 일반적으로 샘플링에 많은 반복(sampling steps) 이 필요하며 이는 높은 계산 비용 과 FLOPs 로 이어진다는 문제점이 있습니다. 기존 연속형 확산 모델 분야에는 sampling steps를 크게 줄이는 다양한 distillation 방법론이 존재하지만, 이산 확산 모델에 적용 가능한 효과적인 distillation 접근 방식은 부족했습니다. 특히, 기존 이산 distillation 방법론들은 고품질 및 다양성을 유지하기 어렵거나(e.g., SDTT는 mode collapse 경향), factorized output distribution의 한계로 상관관계 있는 출력을 학습하기 어렵다는 한계가 있었습니다(e.g., Di4C). 이러한 문제로 인해 이산 확산 모델의 실용적인 적용이 제한되며, 적은 단계로도 고품질 샘플을 생성할 수 있는 효율적인 distillation 기법의 개발이 시급합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 연속형 MMD(Moment Matching Distillation)의 아이디어를 Discrete-MMD (D-MMD) 로 일반화하여 이산 확산 모델을 증류하는 새로운 알고리즘을 제안합니다. D-MMD는 generator gη가 teacher 모델 gθ에 대한 손실을 최소화하면서 auxiliary 모델 gφ에 대한 손실을 최대화하고, 동시에 auxiliary 모델은 generator에 대한 손실을 최소화하며 teacher 모델과 유사하게 유지되도록 규제되는 min-max formulation으로 최적화됩니다. 특히, 이산 확산 모델의 특성을 고려하여, categorical sample x에서 η로의 직접적인 gradient가 어렵기 때문에, hard samples 대신 soft probability vector pη(zt)를 사용하여 직접적인 모멘트 매칭을 수행합니다. 또한, temperature scaling 및 top-p sampling과 같은 기술을 활용하여 teacher model의 가이던스를 distillation 과정에 통합합니다. 마스크 확산(masked diffusion)의 경우 입력 노이즈(input noise) 컨디셔닝이 FID 및 generator output entropy 에 중요한 영향을 미친다는 것을 발견했습니다 [Table 6].
실험 결과, D-MMD는 teacher 모델을 크게 능가하는 성능을 보였습니다.
- CIFAR-10 이미지 생성 :
- Uniform Diffusion Teacher 가 1024 steps에서 7.5 FID 를 달성한 반면, Uniform D-MMD 는 32 steps에서 3.7 FID 를 달성하여 teacher를 2배 이상 능가했습니다
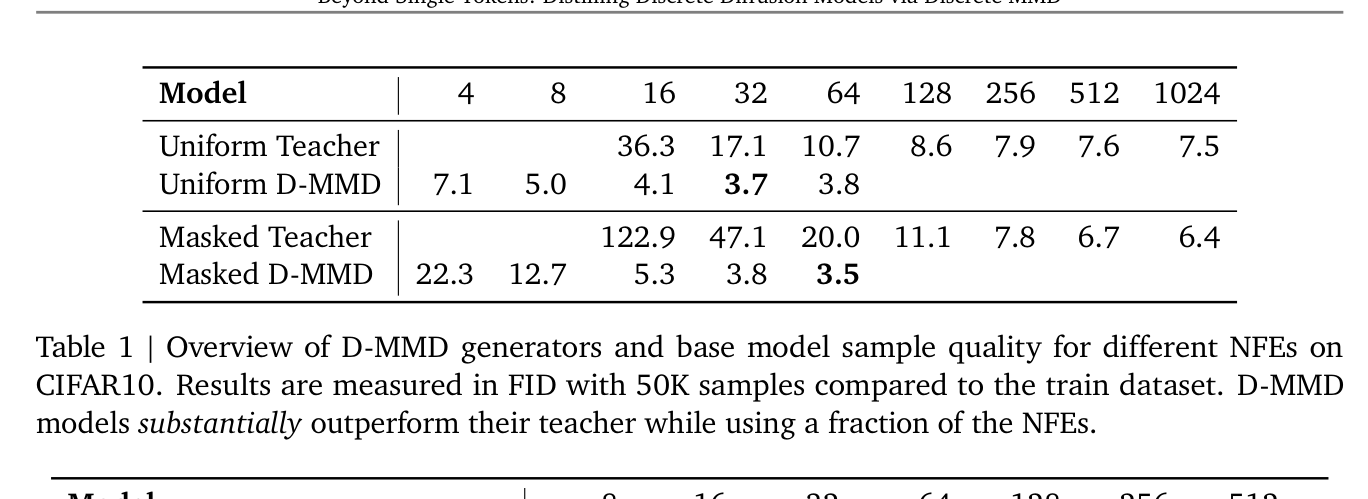
* **Masked Diffusion Teacher** 가 **1024** steps에서 **6.4 FID** 를 달성한 반면, **Masked D-MMD** 는 **64** steps에서 **3.5 FID** 를 달성하여 teacher를 **거의 2배** 능가했습니다 [Table 1].
* 기존 Di4C와 비교했을 때, Di4C Teacher는 **40** steps에서 **8.0 FID** 를 달성했지만, Uniform D-MMD는 **8** steps에서 **5.0 FID** 를 달성하여 Di4C보다 적은 단계에서 더 우수한 성능을 보였습니다 [Table 4].
- Open Web Text (OWT) 텍스트 생성 :
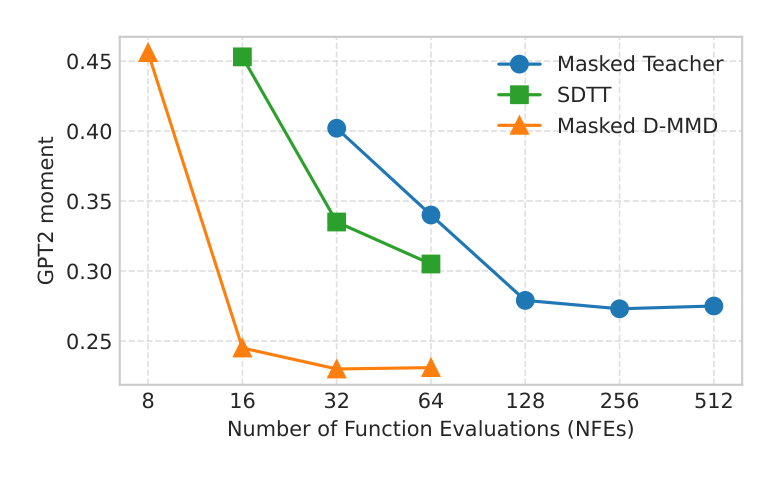
- Masked Teacher 가 256 steps에서 0.275 GPT-2 GM 을 달성한 반면, Masked D-MMD 는 16 steps에서 0.236 GPT-2 GM 을 달성하여 teacher를 능가했습니다 [Table 2].
- Uniform D-MMD 역시 32 steps에서 0.307 GPT-2 GM 을 달성하여 Uniform Teacher 의 0.375 GPT-2 GM (32 steps)보다 우수했습니다 [Table 2].
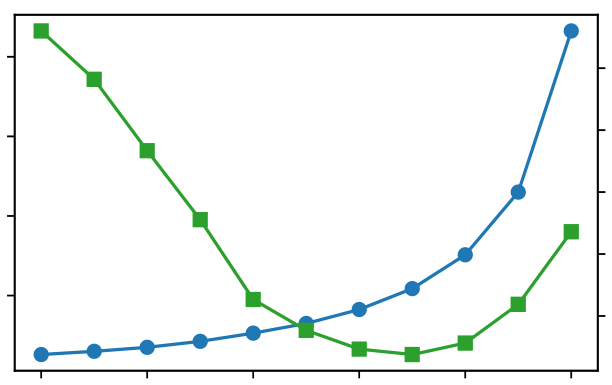
- GPT-2 GM 은 perplexity가 낮은 온도 샘플링에서 계속 개선되는 반면, grad moment는 결국 저하되는 경향을 보여, perplexity가 샘플 품질을 완전히 반영하지 못함을 시사합니다
- Block autoregressive diffusion 실험에서는 16-step D-MMD generator가 256-step teacher 의 성능과 일치했습니다 [Table 3]. 종합적으로 D-MMD는 teacher 모델 대비 현저히 적은 수의 NFEs (Number of Function Evaluations)로 teacher의 성능을 능가하거나 대등한 수준의 고품질 샘플을 생성할 수 있음을 입증했습니다
4. Conclusion & Impact (결론 및 시사점)
본 논문은 이산 확산 모델을 few-step generator로 증류할 수 있는 새로운 원리 기반 기법인 Discrete-MMD (D-MMD) 를 성공적으로 제안했습니다. D-MMD는 연속형 MMD 프레임워크를 이산 데이터에 맞게 일반화하여, 샘플 품질과 다양성을 효과적으로 유지합니다. 실험 결과는 D-MMD를 통해 distilled generator가 teacher 모델보다 현저히 적은 denoising steps로도 더 좋은 성능을 낼 수 있음을 보여줍니다. 이는 teacher 모델이 mode-covering 방식인 최대 우도(maximum likelihood)로 학습되는 반면, D-MMD와 같은 증류 기법은 mode-seeking 경향을 보이기 때문입니다. 이 연구는 이산 확산 모델의 효율성과 실용성을 크게 향상시켜, 고품질 이미지 및 텍스트 생성을 위한 계산 비용을 절감하는 데 중요한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
- [논문리뷰] LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
- [논문리뷰] Self-Evaluation Is Already There: Eliciting Latent Judge Calibration in Base LLMs with Minimal Data
- [논문리뷰] MIRA: Mid-training Rubric Anchoring for Source-Aware Data Selection
- [논문리뷰] minWM: A Full-Stack Open-Source Framework for Real-Time Interactive Video World Models
Review 의 다른글
- 이전글 [논문리뷰] BEAVER: A Training-Free Hierarchical Prompt Compression Method via Structure-Aware Page Selection
- 현재글 : [논문리뷰] Beyond Single Tokens: Distilling Discrete Diffusion Models via Discrete MMD
- 다음글 [논문리뷰] Cooperation and Exploitation in LLM Policy Synthesis for Sequential Social Dilemmas
댓글