[논문리뷰] Nudging Beyond the Comfort Zone: Efficient Strategy-Guided Exploration for RLVR
링크: 논문 PDF로 바로 열기
메타데이터
저자: Chanuk Lee, Sangwoo Park, Minki Kang, Sung Ju Hwang
1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards): 수학적 해답이나 코드 검증 결과와 같이 정답이 명확한 보상을 활용하여 언어 모델의 추론 능력을 최적화하는 학습 패러다임입니다.
- Strategy Nudging: 모델의 입력에 경량의 전략적 컨텍스트(예: 특정 수학적 개념이나 키워드)를 부가하여, 단순히 동일한 분포에서 샘플링하는 대신 다양한 추론 모드를 강제로 탐색하도록 유도하는 기법입니다.
- Inter-Intra Group Advantage: 서로 다른 컨텍스트 그룹 간의 신뢰도를 비교하는 inter-context 신호와 특정 컨텍스트 내의 품질을 평가하는 intra-context 신호를 결합하여, 컨텍스트 조건부 탐색 환경에서도 안정적으로 credit assignment를 수행하는 방식입니다.
- Distillation Objective: 컨텍스트가 부여된 탐색 과정에서 발견된 효과적인 추론 전략을 컨텍스트가 없는 원래의 정책(
Base Policy)으로 전이(Transfer)시켜, 추론 단계에서 별도의 힌트 없이도 높은 성능을 유지하게 하는 학습 목적 함수입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 RLVR 환경에서 고질적인 문제인 탐색의 병목 현상을 해결하고자 합니다. 기존 방식은 탐색 효율을 높이기 위해 샘플링 횟수(Rollout)를 무작정 늘리는 방식을 취하지만, 이는 계산 비용이 극심하고 long-tail에 위치한 희귀한 정답 추론 경로를 발견하는 데 한계가 있습니다 [Figure 1]. 또한, 기존의 privileged information(오라클 힌트 등)을 활용하는 기법들은 비용이 높고 모델의 일반화 능력을 저해할 위험이 있어 확장 가능한 구조적 탐색 기법이 절실히 요구됩니다.
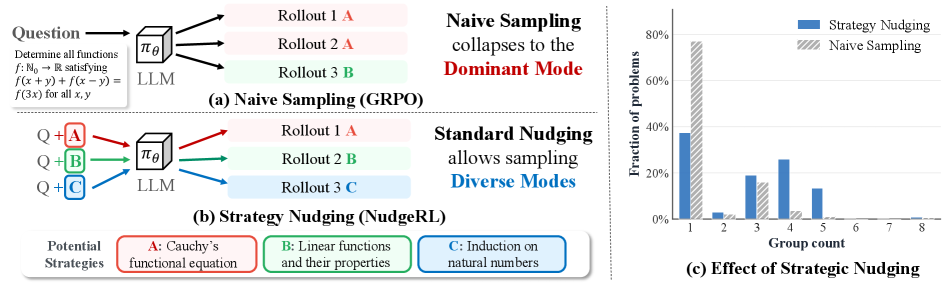
Figure 1 — Strategy Nudging의 개념
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 구조적이고 다양성 중심의 탐색을 위해 NudgeRL 프레임워크를 제안합니다. NudgeRL은 Strategy Nudging을 통해 입력에 전략적 컨텍스트를 추가하여 명시적으로 다양한 추론 모드를 활성화하고, Inter-Intra Group Advantage를 통해 컨텍스트 기반의 보상 변화를 정교하게 학습합니다 [Figure 2]. 또한, Distillation augmented objective를 도입하여 컨텍스트 환경에서 습득한 지식을 기반 모델로 전이함으로써 추론 단계의 성능을 극대화합니다.

Figure 2 — NudgeRL 학습 메커니즘
정량적 결과로서, NudgeRL은 표준 GRPO 대비 최대 8배 더 많은 rollout budget을 투입한 결과보다 우수한 성능을 입증하였습니다. Qwen3-4B-Instruct 모델 기준, NudgeRL은 8개의 rollout만으로도 32개의 rollout을 사용한 GRPO를 상회하는 0.489의 pass@1을 기록하였습니다. 또한, 오라클 기반의 POPE 기법과 비교했을 때도 5개 벤치마크 평균 성능에서 일관된 우위를 점하며, 효율적인 컨텍스트 기반 탐색의 확장성을 증명했습니다 [Table 1, Figure 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Strategy Nudging이라는 새로운 개념을 통해 RLVR의 탐색 효율성을 획기적으로 개선했습니다. 이 연구는 비싼 오라클 정보 없이도 경량화된 컨텍스트 만으로 구조적 탐색이 가능함을 보여주며, 이는 거대 모델 학습의 계산 자원을 절감하고 더 적은 시도로 정확한 추론 경로를 확보하게 함으로써 학계와 산업계의 RLVR 활용 폭을 넓히는 중요한 이정표가 될 것입니다.
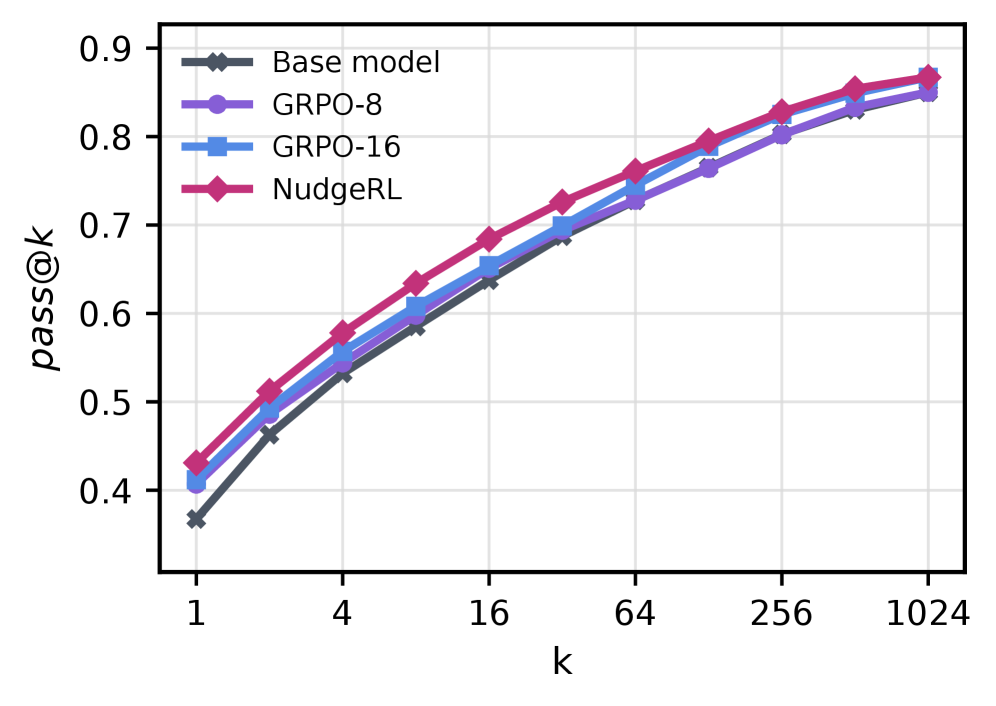
Figure 3 — AIME 벤치마크 학습 성능 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
- [논문리뷰] Quantile Advantage Estimation for Entropy-Safe Reasoning
- [논문리뷰] Transferability for General Reasoning: An Automated Curriculum for Multi-Domain RLVR
- [논문리뷰] Self-Evaluation Is Already There: Eliciting Latent Judge Calibration in Base LLMs with Minimal Data
- [논문리뷰] Combinatorial Synthesis: Scaling Code RLVR via Atomic Decomposition and Recombination
Review 의 다른글
- 이전글 [논문리뷰] MobileEgo Anywhere: Open Infrastructure for long horizon egocentric data on commodity hardware
- 현재글 : [논문리뷰] Nudging Beyond the Comfort Zone: Efficient Strategy-Guided Exploration for RLVR
- 다음글 [논문리뷰] OmniHumanoid: Streaming Cross-Embodiment Video Generation with Paired-Free Adaptation
댓글