[논문리뷰] Near-Future Policy Optimization
링크: 논문 PDF로 바로 열기
메타데이터
저자: Chuanyu Qin, Chenxu Yang, Qingyi Si, Naibin Gu, Dingyu Yao, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards): 모델이 생성한 결과물의 정답 여부를 검증 가능한 보상을 통해 강화학습을 수행하는 사후 학습(post-training) 프레임워크입니다.
- Mixed-Policy RL: 현재 정책(on-policy) 외에 외부Demonstration이나 과거 학습 경로 등 다른 소스의 데이터를 학습에 혼합하여 보조적인 학습 신호를 얻는 기법입니다.
- Signal Quality ($Q$): 오프라인 소스(guide)가 현재 정책이 실패하는 프롬프트에 대해 정답을 생성할 수 있는 능력입니다.
- Variance Cost ($V$): 오프라인 소스의 데이터를 중요도 샘플링(Importance Sampling)으로 학습에 통합할 때 발생하는 그래디언트 분산입니다.
- Effective Learning Signal ($\mathcal{S}$): $Q/V$로 정의되며, 모델이 학습 신호를 얼마나 효과적으로 흡수할 수 있는지를 나타내는 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 RLVR 과정에서 on-policy 탐색이 갖는 한계를 극복하고 최적의 보조 학습 신호를 확보하는 문제를 다룹니다. 기존의 Mixed-Policy 기법들은 외부 전문가 모델을 사용하거나(고품질이나 분포 차이가 큼), 과거 학습 기록을 재사용하는(분포는 가깝지만 품질이 낮음) 방식 사이의 Trade-off 문제에 직면해 있습니다. 즉, 충분히 강력하면서도(High $Q$) 학습 가능한(Low $V$) 소스를 찾는 것이 핵심 과제입니다 [Figure 2]. 본 연구는 $Q/V$를 최대화하는 적절한 보조 데이터 소스를 찾아 모델의 성능을 향상시키고자 합니다.
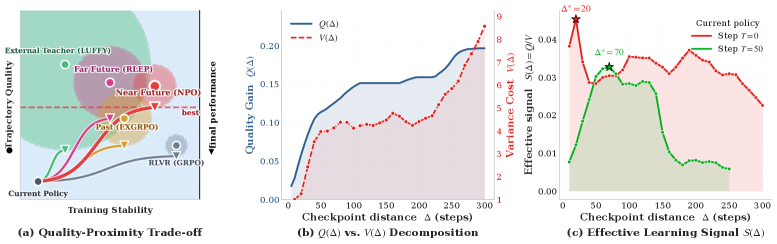
Figure 2 — 품질-안정성 Trade-off 분석
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 현재 정책의 학습 경로상에 존재하는 미래 체크포인트(near-future checkpoint)를 보조 데이터 소스로 활용하는 NPO (Near-Future Policy Optimization)를 제안합니다. 동일한 학습 Run 내의 미래 체크포인트는 현재 정책과 구조 및 초기화 조건을 공유하여 $V$를 낮게 유지하면서도, 추가적인 최적화 단계를 거쳤기에 현재보다 높은 $Q$를 제공합니다 [Figure 3]. NPO는 특정 프롬프트에서 현재 정책이 어려움을 겪을 때, 미래 정책이 생성한 검증된 정답을 rollout 그룹에 삽입하여 학습을 가이드합니다. 또한, 학습 상황을 모니터링하여 자동으로 개입 시점과 롤백 거리를 결정하는 AutoNPO를 제안합니다. 실험 결과, Qwen3-VL-8B-Instruct 모델에서 GRPO 대비 평균 성능을 57.88에서 63.15로 향상시켰으며, 학습 초기 수렴 가속화와 후기 성능 고점 돌파라는 두 가지 효과를 동시에 입증했습니다 [Table 1, Figure 1].
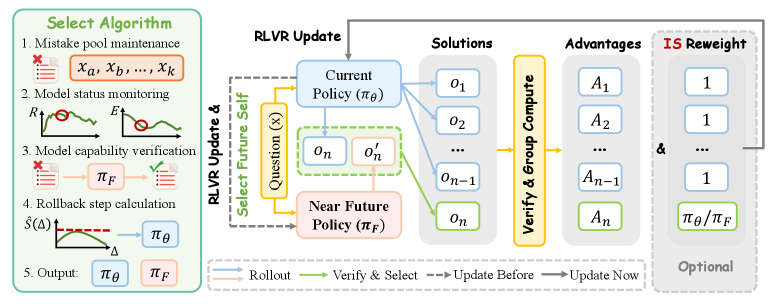
Figure 3 — NPO 및 AutoNPO 메커니즘 개요
4. Conclusion & Impact (결론 및 시사점)
본 논문은 RLVR의 효율적인 보조 학습을 위해 미래 시점의 자기 자신을 가이드로 활용하는 NPO 프레임워크를 제안하고, $Q/V$ Trade-off의 이론적 토대를 마련했습니다. NPO는 복잡한 보상 설계 없이 간단한 롤아웃 조작만으로 성능을 개선할 수 있어 실용성이 높습니다. 이는 향후 대규모 언어 모델의 사후 학습 전략에 있어 모델 스스로 학습 신호를 정교화하는 'Self-Taught RLVR' 패러다임의 중요한 발판이 될 것으로 기대됩니다.
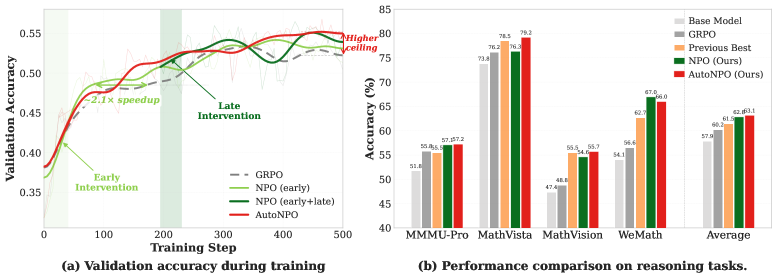
Figure 1 — NPO 학습 효과 및 벤치마크 성능
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Self-Distilled RLVR
- [논문리뷰] Combinatorial Synthesis: Scaling Code RLVR via Atomic Decomposition and Recombination
- [논문리뷰] Guiding LLM Post-training Data Engineering with Model Internals from Sparse Autoencoders
- [논문리뷰] The Unlearnability Phenomenon in RLVR for Language Models
- [논문리뷰] Video Models Can Reason with Verifiable Rewards
Review 의 다른글
- 이전글 [논문리뷰] MMCORE: MultiModal COnnection with Representation Aligned Latent Embeddings
- 현재글 : [논문리뷰] Near-Future Policy Optimization
- 다음글 [논문리뷰] ReImagine: Rethinking Controllable High-Quality Human Video Generation via Image-First Synthesis
댓글