[논문리뷰] Apriel-Reasoner: RL Post-Training for General-Purpose and Efficient Reasoning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Rafael Pardinas, Ehsan Kamalloo, David Vazquez, Alexandre Drouin
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards) : 모델의 출력이 정확한지 프로그램적으로 검증 가능한 보상 함수를 사용하여 강화학습을 수행하는 기법입니다.
- PipelineRL : 롤아웃(Rollout) 생성과 학습(Training) 단계를 비동기적으로 처리하여 모델 가중치를 실시간으로 업데이트하는 분산형 RL 시스템입니다.
- GSPO (Group Sequence Policy Optimization) : 시퀀스 단위의 중요도 가중치를 사용하여 토큰 단위의 학습 불안정성을 해소하고 효율적인 최적화를 돕는 정책 최적화 알고리즘입니다.
- DAP (Difficulty-Aware Length Penalty) : 문제의 난이도에 따라 페널티 강도를 조절하여 어려운 문제에는 더 긴 추론 시간을 부여하고 쉬운 문제는 간결하게 생성하도록 유도하는 기법입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 대규모 언어 모델의 일반적인 추론 성능을 향상시키면서, 불필요하게 긴 추론(Overthinking)을 방지하여 추론 비용과 지연 시간(Latency)을 최소화하는 것을 목표로 합니다. 기존의 폐쇄적인 Frontier 모델들은 복합적인 도메인에서의 학습 기법이나 데이터 조합이 공개되지 않아 재현성(Reproducibility)에 문제가 있습니다. 또한, 다중 도메인 RL 학습 시 각 도메인의 롤아웃 길이와 난이도가 달라 학습 데이터가 편향되는 문제가 발생합니다. 본 연구는 이를 해결하기 위해 투명하고 재현 가능한 RL post-training 레시피인 Apriel-Reasoner 를 제안합니다.
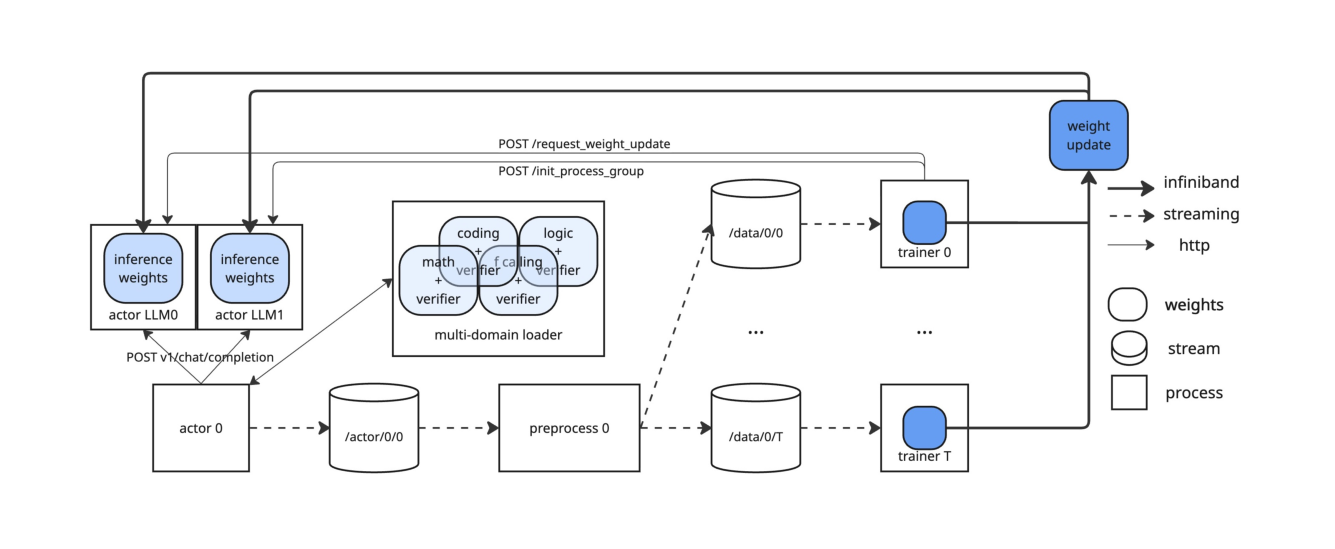
## 3. Method & Key Results (제안 방법론 및 핵심 결과) Apriel-Reasoner 는 Apriel-Base 를 기반으로 비동기적 다중 도메인 학습을 수행하며, Adaptive Domain Sampling 을 통해 도메인별 학습 편향을 동적으로 보정합니다. 제안된 DAP 는 문제 해결 성공률(Solve rate)에 기반하여 페널티를 modulate함으로써, 어려운 문제에는 긴 추론 공간을 제공하고 쉬운 문제는 짧은 추론으로 처리하게 합니다. 실험 결과, Apriel-Reasoner 는 32K 토큰 추론 예산 환경에서 AIME 2025 , GPQA , MMLU-Pro , LiveCodeBench 모두에서 베이스라인 모델 대비 성능 개선을 입증하였습니다. 특히 기존 모델들보다 30-50% 더 짧은 추론 트레이스를 생성하면서도 더 높은 정량적 정확도를 기록하여, Pareto frontier 관점에서 우수한 효율성을 보였습니다. 이와 같은 결과는
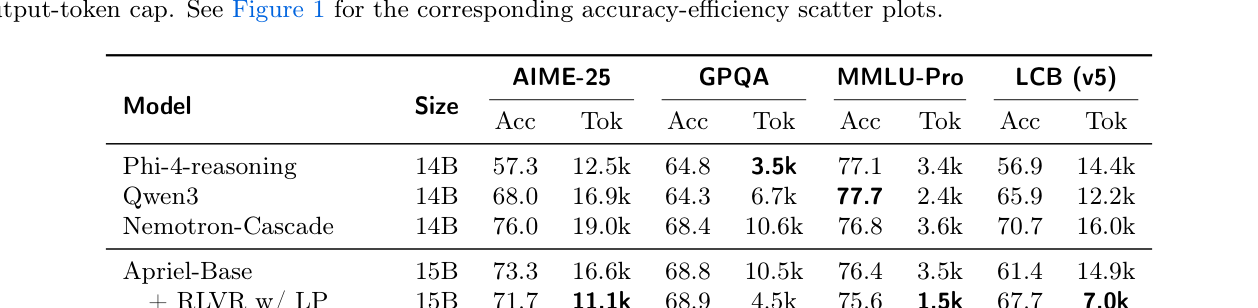
를 통해 확인할 수 있으며, 도메인 구성에 따른 성능 차이는
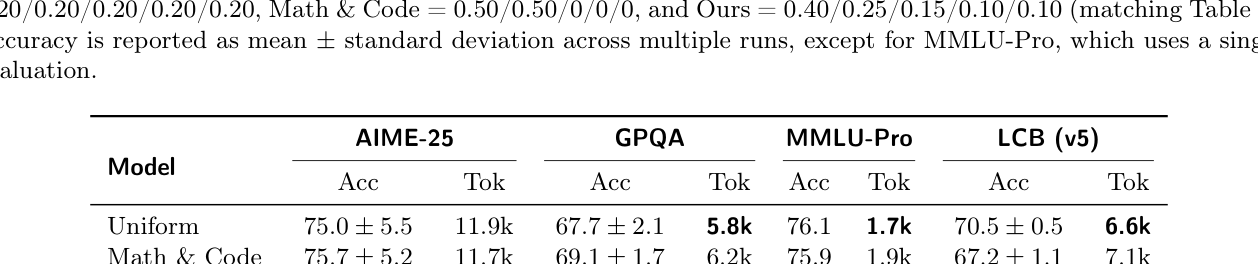
에 요약되어 있습니다.
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 15B 파라미터 규모의 Apriel-Reasoner 모델을 통해 다중 도메인 RL post-training의 효율성과 재현성을 성공적으로 달성했습니다. 본 연구에서 도입한 적응형 샘플링과 난이도 인지 페널티 기법은 복잡한 추론 문제 해결과 Inference 효율성 사이의 상충 관계를 효과적으로 해결했습니다. 본 연구의 성과는 투명한 학습 파이프라인 공개를 통해 향후 오픈 웨이트 모델들의 연구와 실제 배포 환경에서의 비용 최적화 전략에 중요한 이정표가 될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LaSeR: Reinforcement Learning with Last-Token Self-Rewarding
- [논문리뷰] Learning Adaptive Reasoning Paths for Efficient Visual Reasoning
- [논문리뷰] Act Wisely: Cultivating Meta-Cognitive Tool Use in Agentic Multimodal Models
- [논문리뷰] ThinkTwice: Jointly Optimizing Large Language Models for Reasoning and Self-Refinement
- [논문리뷰] InftyThink+: Effective and Efficient Infinite-Horizon Reasoning via Reinforcement Learning
Review 의 다른글
- 이전글 [논문리뷰] ASI-Evolve: AI Accelerates AI
- 현재글 : [논문리뷰] Apriel-Reasoner: RL Post-Training for General-Purpose and Efficient Reasoning
- 다음글 [논문리뷰] Ask or Assume? Uncertainty-Aware Clarification-Seeking in Coding Agents
댓글