[논문리뷰] ReImagine: Rethinking Controllable High-Quality Human Video Generation via Image-First Synthesis
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhengwentai Sun, Keru Zheng, Chenghong Li, Hongjie Liao, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Image-First Synthesis: 비디오 생성 전체를 처음부터 학습하는 대신, 고품질 이미지 생성 모델을 우선 활용하여 인물 외형과 구조를 정의하고 이를 기반으로 비디오를 생성하는 전략.
- SMPL-X: 인체의 포즈, 형태, 얼굴 표현을 모델링하는 3D 파라메트릭 인체 모델로, 논문에서 포즈 및 뷰포인트 가이던스(guidance)의 핵심 입력으로 사용됨.
- Flow Matching: 확산 모델(Diffusion Model)의 확률적 미분 방정식을 일반화하여, 노이즈에서 데이터로의 변환을 확률 흐름(Probability Flow)으로 학습시키는 최신 프레임워크.
- Training-Free Temporal Consistency: 별도의 비디오 학습 과정 없이, 추론 단계(inference stage)에서 사전 학습된 모델의 잠재 공간(latent space)을 조정하여 프레임 간의 일관성을 강화하는 기법.
- RoPE (Rotary Positional Embedding): 토큰의 상대적 위치 정보를 회전 행렬을 통해 인코딩하는 방식이며, 본 논문에서는 다양한 입력 조건(포즈, 외형, 노이즈)을 구분하기 위해 수정된 Condition-Aware RoPE를 사용함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 고품질 인물 비디오 생성 연구들이 포즈, 외형, 카메라 뷰포인트에 대한 동시 제어 역량이 부족하고, 대규모 고품질 멀티뷰 비디오 데이터의 희소성으로 인해 성능 한계에 직면했다는 문제를 해결하고자 한다. 대부분의 기존 방식은 외형 모델링과 시간적 일관성(temporal consistency) 학습을 비효율적으로 결합하여 제어력과 시각적 품질 간의 트레이드오프를 강제한다. 따라서 저자들은 데이터 부족 문제를 회피하면서도 강력한 이미지 생성 사전 지식(prior)을 활용할 수 있는 새로운 Image-First 접근 방식을 제안한다 [Figure 2].
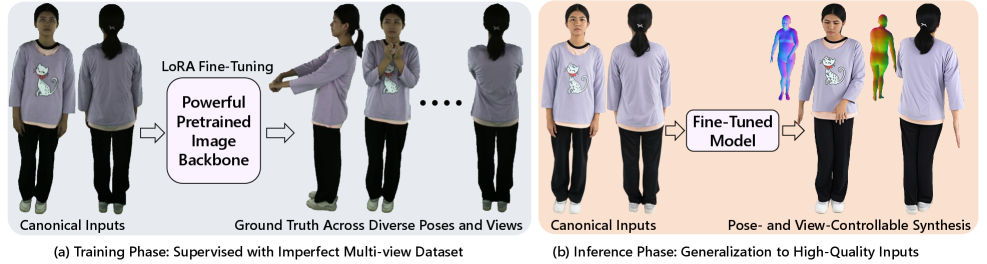
Figure 2 — Image-first 훈련 및 추론 구조
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 ReImagine 프레임워크를 제안하며, 1) Pose- and View-Guided Image Synthesis Module과 2) Training-Free Temporal Consistency Module이라는 두 단계로 구성된다. 첫 단계에서는 사전 학습된 FLUX.1 모델을 LoRA로 미세 조정하여 3D SMPL-X 노멀 맵(normal map)과 정면/후면 이미지를 입력으로 받아 고품질 이미지를 생성한다 [Figure 3]. 두 번째 단계에서는 생성된 프레임의 미세한 지터링(jittering)이나 불안정성을 해결하기 위해 저노이즈 재-디노이징(low-noise re-denoising)과 3D FFT를 활용한 스파이오템포럴(spatiotemporal) 정규화를 적용한다 [Figure 4].
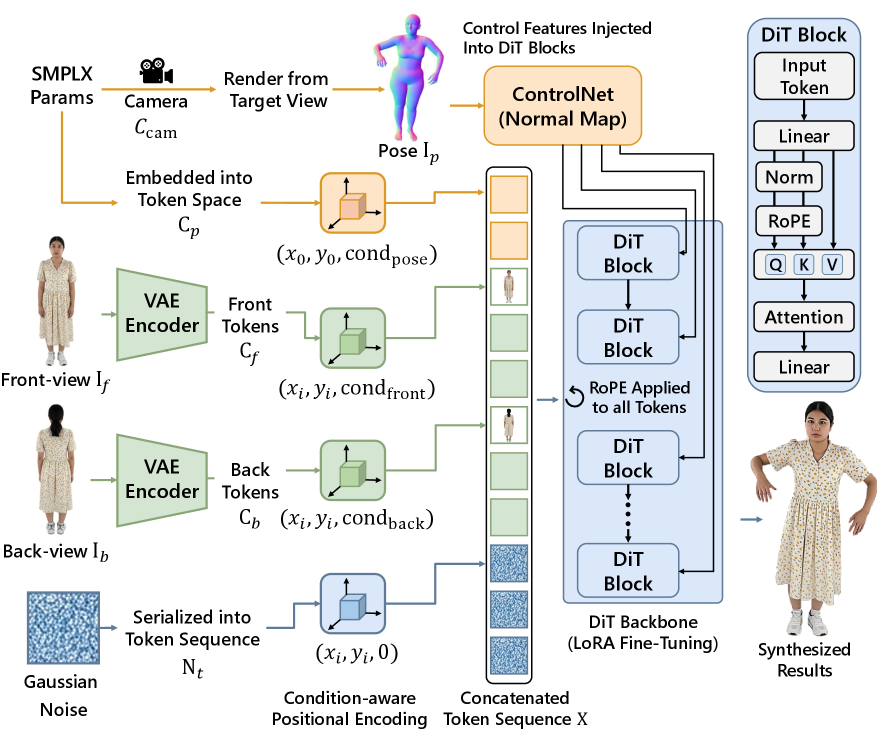
Figure 3 — 포즈 및 뷰 가이드 모듈
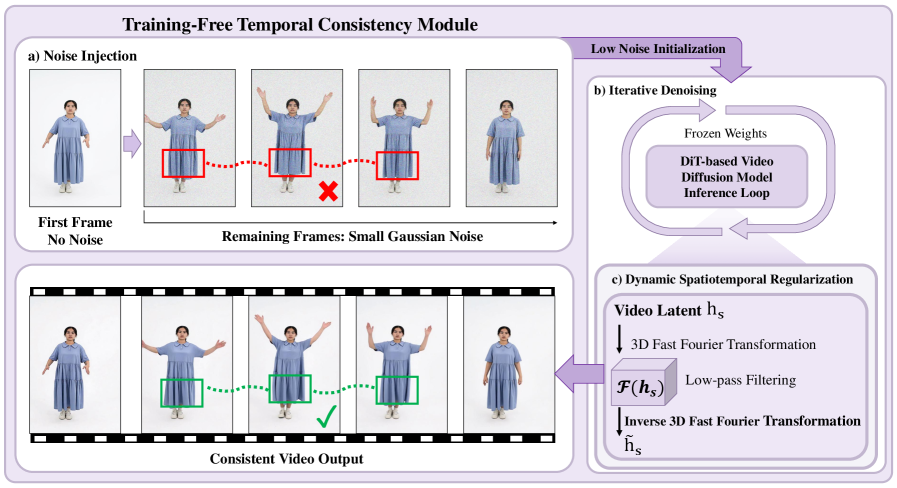
Figure 4 — 훈련 없는 시간적 일관성 모듈
정량적 실험 결과, ReImagine은 MVHumanNet++ 데이터셋에서 FVD 0.275를 기록하여 기존 최첨단 모델인 Wan-Animate의 0.403 대비 탁월한 시간적 일관성을 증명하였다 [Table 1]. 또한, DNA-Rendering 데이터셋에 대한 제로샷(zero-shot) 평가에서도 PSNR 22.98, SSIM 0.847을 달성하며 뷰포인트 변화에 대해 가장 강력한 제어력을 보였다 [Table 1]. 이는 비디오 전체를 직접 학습시키는 방식보다 Image-First formulation이 높은 시각적 충실도와 안정성을 제공함을 시사한다 [Figure 9].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 인물 비디오 생성을 고품질 이미지 기반의 제어 가능한 합성 문제로 재정의함으로써 데이터 요구 사항을 크게 낮추고 성능을 향상시켰다. 사전 학습된 이미지 백본과 훈련이 필요 없는 시간적 정규화 기법을 결합하여, 부족한 멀티뷰 비디오 데이터 환경에서도 고품질의 제어 가능한 비디오를 생성할 수 있음을 입증했다. 이 연구는 향후 디지털 휴먼 생성, 가상 피팅, 메타버스 콘텐츠 제작 분야에서 효율적이고 강력한 생성 파이프라인으로 활용될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Xiaomi-Robotics-0: An Open-Sourced Vision-Language-Action Model with Real-Time Execution
- [논문리뷰] DreamID-V:Bridging the Image-to-Video Gap for High-Fidelity Face Swapping via Diffusion Transformer
- [논문리뷰] Kandinsky 5.0: A Family of Foundation Models for Image and Video Generation
- [논문리뷰] From Editor to Dense Geometry Estimator
- [논문리뷰] Surflo: Consistent 3D Surface Flow Model with Global State
Review 의 다른글
- 이전글 [논문리뷰] Near-Future Policy Optimization
- 현재글 : [논문리뷰] ReImagine: Rethinking Controllable High-Quality Human Video Generation via Image-First Synthesis
- 다음글 [논문리뷰] Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
댓글