[논문리뷰] OmniHumanoid: Streaming Cross-Embodiment Video Generation with Paired-Free Adaptation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yiren Song, Xiyao Deng, Pei Yang, Yihan Wang, Mike Zheng Shou, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- TAPE: Transferable motion, paired-free Adaptation, embodiment Preservation, and generation Efficiency의 약어로, 본 논문이 제안하는 cross-embodiment video generation을 위한 핵심 원칙입니다.
- Embodiment Video LoRA: 특정 로봇의 외형 및 형태적 특성(geometry, texture)을 학습하는 lightweight 모듈로, denoising branch에 부착되어 Paired-free Adaptation을 가능하게 합니다.
- Shared Motion Transfer Model: 여러 embodiment에 걸쳐 공통적으로 적용 가능한 motion dynamics(행동, 상호작용 등)를 추출하는 conditioning branch 기반의 핵심 모델입니다.
- Streaming video-to-video distillation: 50단계의 iterative denoising 과정을 4단계의 효율적인 causal generation 과정으로 변환하여 실시간 추론을 가능하게 하는 기법입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 로봇 학습을 위한 고품질 데이터 수집의 높은 비용과 확장성 문제를 해결하기 위해, 다양한 humanoid embodiment 간의 cross-embodiment video generation을 수행하고자 합니다. 기존의 방식들은 motion과 appearance/morphology를 분리하지 못해 특정 로봇마다 paired 데이터가 필요하다는 제약이 있으며, 고차원 로봇 관절의 temporal consistency를 유지하는 데 어려움이 있습니다. 또한, 기존 video-to-video 모델들은 복잡한 denoising 과정으로 인해 실시간 상호작용이나 대규모 데이터 생성에 적합하지 않은 속도 문제를 보입니다. 이를 극복하기 위해 제안된 OmniHumanoid는 모션과 외형을 명시적으로 분리하고, Paired-free Adaptation을 통해 unseen embodiment로의 확장을 지원합니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 Diffusion Transformer(DiT) 백본을 기반으로 motion과 appearance를 분리하는 unidirectional information-flow 설계와 branch-isolated attention 디자인을 채택합니다. 제안된 방법론은 모션 정보를 처리하는 conditioning branch와 embodiment 특징을 렌더링하는 denoising branch를 물리적으로 분리하며, rolling LoRA loading 전략을 통해 효율적인 학습을 수행합니다. 실험 결과, 본 모델은 Synthetic Held-out Embodiment Benchmark에서 PSNR 25.47, SSIM 0.9039를 기록하며 비교 대상인 SOTA 모델들을 상회하는 성능을 보였습니다 [Table 1]. 또한, [Figure 2]의 구조적 설계를 통해 unseen robot(Unitree-G1 등)에 대한 뛰어난 일반화 능력을 입증하였으며, streaming distillation을 통해 기존 0.10 FPS에서 4.96 FPS 수준으로 추론 속도를 획기적으로 개선하였습니다.
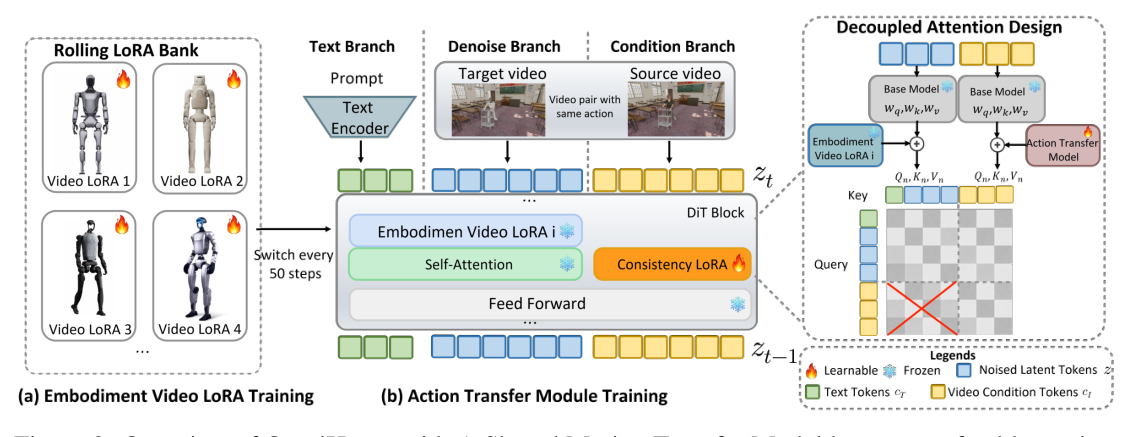
Figure 2 — 전체 모델의 unidirectional 정보 흐름과 branch-decoupled 아키텍처를 시각화한 핵심 다이어그램
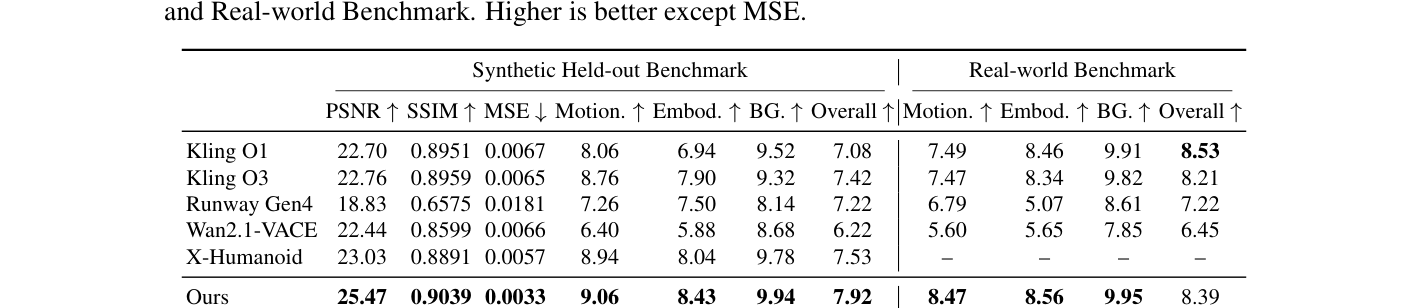
Table 1 — 제안 모델이 SOTA 대비 성능 우위를 점하고 있음을 보여주는 핵심 정량적 비교 지표
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 cross-embodiment video generation을 위한 factorized 프레임워크인 OmniHumanoid를 통해 데이터 수집 비용을 절감하고 로봇 학습의 확장성을 크게 향상했습니다. motion-alignment 기반의 합성 데이터셋 구축과 LoRA 기반의 가벼운 적응(adaptation) 전략은 향후 로봇 데이터 생성의 새로운 패러다임을 제시합니다. 본 기술은 실시간 로봇 데이터 생산 및 embodied intelligence 연구 분야의 실무적 deployability를 한층 높일 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SwiftVR: Real-Time One-Step Generative Video Restoration
- [논문리뷰] SwiftI2V: Efficient High-Resolution Image-to-Video Generation via Conditional Segment-wise Generation
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] Infinite Worlds with Versatile Interactions
- [논문리뷰] TerraDiT-Ω: Unified Spatial Control for Satellite Image Synthesis with Any Geospatial Primitive
Review 의 다른글
- 이전글 [논문리뷰] Nudging Beyond the Comfort Zone: Efficient Strategy-Guided Exploration for RLVR
- 현재글 : [논문리뷰] OmniHumanoid: Streaming Cross-Embodiment Video Generation with Paired-Free Adaptation
- 다음글 [논문리뷰] PAGER: Bridging the Semantic-Execution Gap in Point-Precise Geometric GUI Control
댓글