[논문리뷰] Incantation: Natural Language as the Action Interface for Multi-Entity Video World Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Shangwen Zhu, Qianyu Peng, Zhao Pu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Action Interface: 비디오 세계 모델에서 사용자가 다음 프레임의 상태 변화를 지시하는 제어 프로토콜입니다.
- Cross-Entity Semantic Transfer: 특정 엔티티(entity)가 학습하지 않은 행동을 자연어 프롬프트를 통해 다른 엔티티의 행동과 개념적으로 공유하여 수행하는 능력입니다.
- ODE-initialized Self-Forcing Distillation: 실시간 스트리밍 추론을 위해 복잡한 교사 모델을 효율적인 학생 모델로 증류하는 2단계 학습 기법입니다.
- RoPE-decoupled KV-Cache Sliding Window: 긴 시퀀스 생성 시 메모리 사용량을 고정하고 위치 정보의 왜곡을 방지하기 위한 효율적인 스트리밍 추론 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대적인 대화형 비디오 세계 모델들이 가진 구조적 한계인 Action Interface의 고착화 문제를 해결합니다. 기존의 애니메이션 ID나 디바이스 입력, 또는 전체 씬 캡션 기반의 제어 방식은 행동 의미론(action semantics)이 특정 엔티티나 엔진에 종속되어 있어, 정교한 멀티 엔티티 제어나 엔티티 간/월드 간 일반화를 수행하기 어렵습니다. 이러한 방식은 새로운 엔티티마다 별도의 행동 어휘를 설계해야 하는 공학적 부담을 초래하며, 다수의 엔티티가 동시에 존재하는 단일 시점(shared viewpoint) 환경에서의 개별적이고 독립적인 제어를 지원하지 못합니다. [Figure 1]

Figure 1 — 엔티티 간 교차 제어 시연
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Incantation이라는 새로운 대화형 비디오 세계 모델을 제안하며, 자연어를 개별 엔티티에 대한 행동 인터페이스로 도입하여 기존의 구조적 한계를 극복합니다. 이 프레임워크는 사전 학습된 비디오 확산 모델을 기반으로 하며, per-frame natural-language conditioning을 통해 각 엔티티에 독립적인 텍스트 슬롯을 할당합니다 [Figure 2]. 핵심적인 기술적 방법론으로는 Bidirectional History Attention을 유지하여 기존의 학습된 사전 지식을 보존하고, Decoupled Text Cross-Attention을 통해 현재 프레임의 행동 프롬프트가 과거 프레임에 영향을 주지 않도록 설계하였습니다 [Figure 4]. 실시간 스트리밍을 위해 ODE-initialized Self-Forcing Distillation을 사용하여 2단계 추론만으로 생성이 가능하게 하였으며, 480p 해상도에서 19.7 FPS의 Throughput을 달성했습니다. 실험 결과, Action-Index 기반의 기존 방식 대비 Cross-Entity Transfer 성능은 89% vs 43%로 나타났으며, 학습되지 않은 Out-of-Vocabulary (OOV) 프롬프트에 대해서도 90%의 ACA (Action Control Accuracy)를 기록하여 탁월한 범용성을 입증했습니다 [Table 1]. [Figure 3]과 [Figure 5]는 이 모델이 Elden Ring 및 KOF와 같은 복잡한 환경에서 멀티 엔티티 제어를 얼마나 정교하게 수행하는지 보여줍니다.
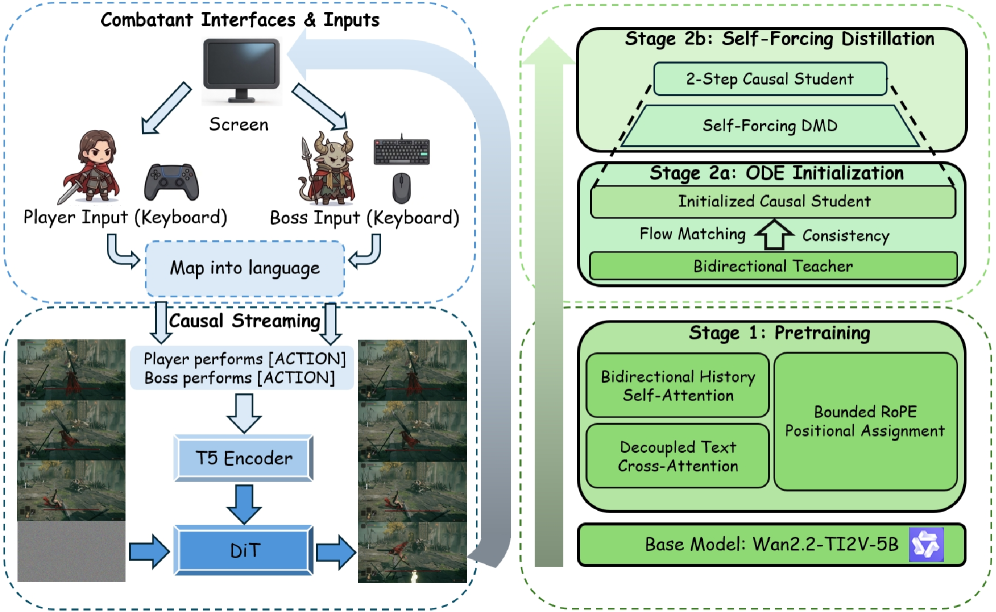
Figure 2 — Incantation 워크플로우
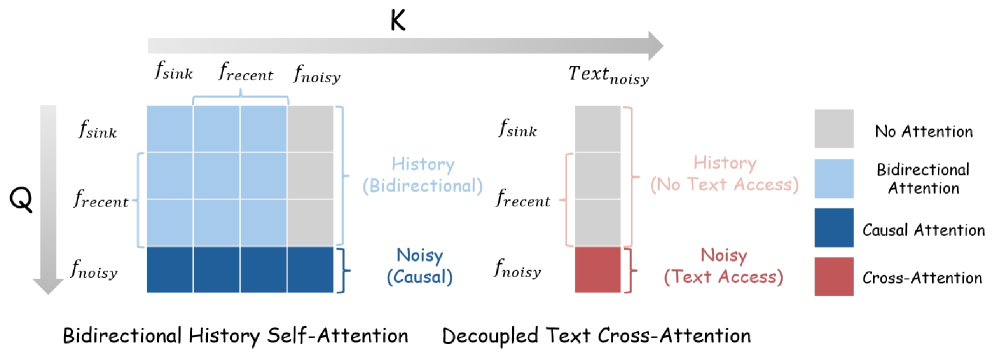
Figure 4 — 어텐션 설계 메커니즘
4. Conclusion & Impact (결론 및 시사점)
본 연구는 자연어 인터페이스를 도입함으로써 기존 interactive video world models가 겪던 엔티티 및 엔진 종속성 문제를 해결하고, 오픈 어휘 기반의 범용적인 제어 체계를 확립했습니다. 이 방식은 개별 엔티티에 대한 독립적이고 동시다발적인 제어를 가능하게 할 뿐만 아니라, 2시간 이상의 장시간 롤아웃에서도 안정적인 FVD 지표를 유지하는 성능을 보여주었습니다. 향후 이 연구는 로봇 학습이나 복합적인 에이전트 시뮬레이션 환경에서 더욱 정교하고 직관적인 인간-AI 상호작용을 구축하는 기반 기술로 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Wan-Streamer v0.1: End-to-end Real-time Interactive Foundation Models
- [논문리뷰] SwiftVR: Real-Time One-Step Generative Video Restoration
- [논문리뷰] OmniHumanoid: Streaming Cross-Embodiment Video Generation with Paired-Free Adaptation
- [논문리뷰] SwiftI2V: Efficient High-Resolution Image-to-Video Generation via Conditional Segment-wise Generation
- [논문리뷰] Qwen3.5-Omni Technical Report
Review 의 다른글
- 이전글 [논문리뷰] Geometric Phase Transition Enables Extreme Hippocampal Memory Capacity
- 현재글 : [논문리뷰] Incantation: Natural Language as the Action Interface for Multi-Entity Video World Models
- 다음글 [논문리뷰] KVPO: ODE-Native GRPO for Autoregressive Video Alignment via KV Semantic Exploration
댓글