[논문리뷰] Versatile Editing of Video Content, Actions, and Dynamics without Training
링크: 논문 PDF로 바로 열기
저자: Vladimir Kulikov, Roni Paiss, Andrey Voynov, Inbar Mosseri, Tali Dekel, Tomer Michaeli et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Rectified Flow Models : Noise-free 경로를 통해 샘플을 생성하는 ODE(Ordinary Differential Equation) 기반의
generative model로, 간단한prior분포에서 데이터 분포로의 변환을 학습합니다. - Inversion-Free Editing : 소스 비디오(
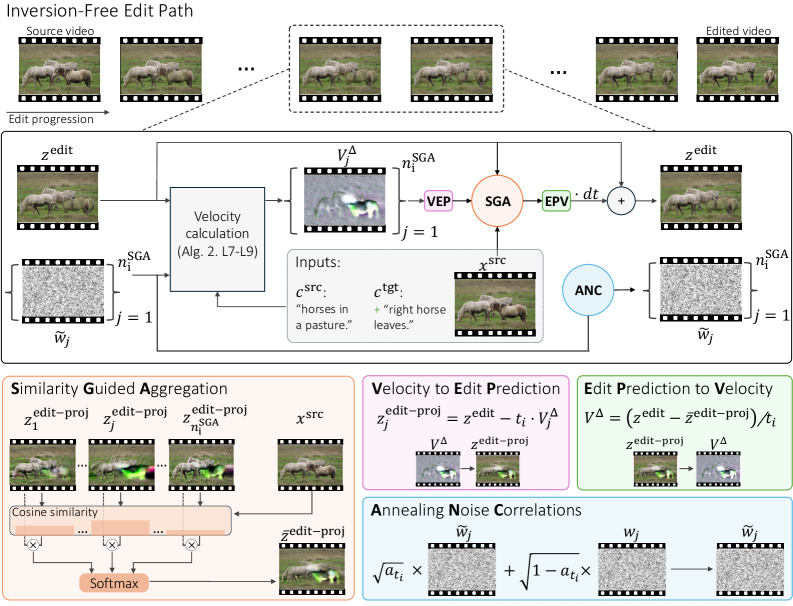
x_src)에서 편집된 비디오(x_edit)로 직접 변환하는 ODE를 구축하여 노이즈 없는 경로를 통해 편집을 수행하는 접근 방식입니다. - Similarity Guided Aggregation (SGA) :
low-frequency misalignment를 완화하기 위해 제안된 메커니즘으로, 소스 비디오와의 유사성(cosine similarity)을 기반으로 여러 편집velocity를soft-selection하여aggregation합니다 [cite: 1, Figure 4]. - Annealed Noise Correlation (ANC) :
high-frequency jitter를 줄이기 위해 도입된scheduler로, 샘플링 과정 후반으로 갈수록 연속적인timestep간의 노이즈correlation을 점진적으로 증가시킵니다 [cite: 1, Figure 4]. - n_max :
FlowEdit에서 소스 비디오에 추가되는 최대 노이즈 양을 제어하는hyperparameter로, 편집의expressivity와structural adherence간의trade-off를 결정합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 generative video models의 발전에도 불구하고, 실제 비디오에서 액션이나 dynamic event를 편집하거나, 삽입된 content가 다른 객체의 행동에 영향을 미치도록 하는 non-rigid, dynamic manipulation은 여전히 큰 도전 과제입니다. 기존 training-based 모델은 관련 훈련 데이터 수집의 어려움으로 인해 복잡한 편집에 한계를 보입니다. 마찬가지로, 기존 training-free 방법들은 structure- 및 motion-preserving edits에 국한되어 있으며, motion이나 interaction의 수정을 지원하지 않습니다. 특히, 기존 inversion-free 접근 방식을 일반적인 unconstrained editing에 그대로 적용할 경우 심각한 low-frequency misalignment와 high-frequency jitter가 발생합니다 [cite: 1, Figure 2, Figure 3]. 이러한 문제점들은 pretrained text-to-video flow models의 방대한 지식을 활용하여 real-world video를 유연하게 편집할 수 있는 새로운 training-free 방법론의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 training-free in-the-wild unconstrained video editing 방법인 DynaEdit 을 제안합니다. 이 방법은 pretrained text-to-video flow models의 생성 과정을 조작하여 scene의 dynamics를 변경하는 동시에, 편집으로 인해 영향을 받지 않아야 할 원본 비디오의 속성을 보존합니다. DynaEdit 은 기존 inversion-free 접근 방식을 general video editing에 적용했을 때 발생하는 low-frequency misalignment와 high-frequency jitter 문제를 해결하기 위해 두 가지 새로운 구성 요소를 도입합니다. 첫째, Similarity Guided Aggregation (SGA) 메커니즘은 초기 편집 단계에서 low spatio-temporal frequencies에 대한 중요한 변경이 노이즈 seed에 따라 크게 달라지는 문제를 해결합니다. SGA는 소스 비디오와의 유사성(cosine similarity)을 기반으로 여러 편집 velocity를 soft selection하고 aggregation하여 source frequencies에 더 잘 정렬된 편집을 유도합니다 [cite: 1, Figure 4]. 둘째, Annealed Noise Correlation (ANC) scheduler는 i.i.d. noise 사용으로 인해 발생하는 high-frequency jitter 문제를 해결합니다. ANC는 샘플링 과정 후반으로 갈수록 노이즈 간의 correlation을 점진적으로 증가시켜 high-frequency jitter를 줄이는 동시에 low-frequency alignment를 유지합니다 [cite: 1, Figure 4].
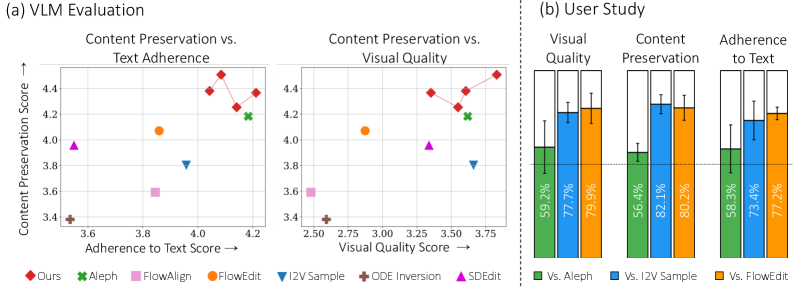
광범위한 실험을 통해 DynaEdit 은 복잡한 text-based video editing tasks에서 state-of-the-art 결과를 달성함을 입증했습니다 [cite: 1, Figure 7]. VLM-based evaluation에서 DynaEdit 은 content preservation에서 가장 높은 점수를 기록했으며, text adherence 및 visual quality 측면에서 훈련된 RunwayML Gen-4 Aleph 모델과 비등한 성능을 보였습니다 [cite: 1, Figure 7 (a)]. 특히, dynamic insertion 및 object swap 범주에서는 Aleph 모델보다 우수했습니다 [cite: 1, Figure 15]. 또한, user study에서는 DynaEdit 이 visual quality, source loyalty, target adherence의 세 가지 측면에서 경쟁 모델(Runway Aleph, FlowEdit, I2V sampling 포함)보다 높은 사용자 선호도를 얻었습니다 [cite: 1, Figure 7 (b)]. Ablation study 결과, SGA는 object dynamics 및 camera motion 측면에서 source video와의 좋은 alignment를 유지하는 데 critical하며 [cite: 1, Figure 16], ANC는 편집된 비디오에서 high-frequency jitter를 현저히 줄여 high-frequency fidelity를 향상시키는 데 중요함을 보여주었습니다 [cite: 1, Figure 17].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 dynamic 및 content에 대한 상당한 수정을 가능하게 하는 versatile training-free video editing framework인 DynaEdit 을 제시합니다. 이 방법은 inversion-free paradigm을 기반으로 하며, 기존 inversion-free 방법들이 structure-preserving edits에만 국한되었던 한계를 넘어 general video editing을 위한 잠재력을 unlock했습니다. Similarity Guided Aggregation (SGA)과 Annealed Noise Correlation (ANC)라는 두 가지 새로운 메커니즘을 통해 low-frequency misalignment와 high-frequency jitter 문제를 성공적으로 해결했습니다.
광범위한 실험을 통해 DynaEdit 은 복잡한 text-based video editing tasks에서 state-of-the-art 결과를 달성했으며, 유일하게 존재하는 trained model인 RunwayML Aleph 와 비교할 만한 성능을 보여주었습니다. 이러한 성과는 training-free 접근 방식을 통해 real-world video의 dynamic 및 interaction을 효과적으로 수정할 수 있음을 입증하며, pretrained text-to-video flow models의 활용 범위를 크게 확장합니다. 이 연구는 학계에서 generative video models와 video editing 분야에 중요한 기여를 하며, 향후 underlying I2V model의 한계와 spatio-temporal modification의 정확성을 개선하는 방향으로 추가 연구의 여지를 남깁니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MultAttnAttrib: Training-Free Multimodal Attribution in Long Document Question Answering
- [논문리뷰] QVal: Cheaply Evaluating Dense Supervision Signals for Long-Horizon LLM Agents
- [논문리뷰] PhotoQuilt: Training-Free Arbitrary-Resolution Photomosaics via Bootstrapped Tiled Denoising
- [논문리뷰] LooseControlVideo: Directorial Video Control using Spatial Blocking
- [논문리뷰] Physics in 2-Steps: Locking Motion Priors Before Visual Refinement Erases Them
Review 의 다른글
- 이전글 [논문리뷰] TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
- 현재글 : [논문리뷰] Versatile Editing of Video Content, Actions, and Dynamics without Training
- 다음글 [논문리뷰] WorldAgents: Can Foundation Image Models be Agents for 3D World Models?
댓글