[논문리뷰] WorldAgents: Can Foundation Image Models be Agents for 3D World Models?
링크: 논문 PDF로 바로 열기
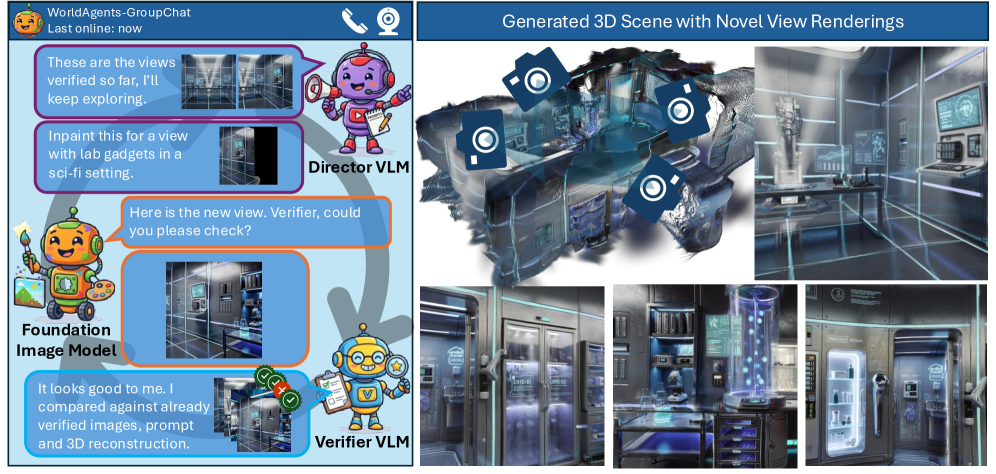
The paper investigates whether 2D foundation image models possess implicit 3D world model capabilities for 3D world synthesis. It proposes a multi-agent architecture:
- Director Agent (VLM-based) : Formulates prompts to guide image synthesis.
- Generator Agent (2D Image Generation Model) : Synthesizes new image views using sequential inpainting.
- 2-Stage Verifier Agent (VLM-backed) : Evaluates generated frames for consistency in both 2D image space and 3D reconstruction space, selectively curating outputs.
The paper demonstrates that this agentic approach provides coherent and robust 3D reconstruction, producing explorative scenes by rendering novel views. It concludes that 2D models do encapsulate a grasp of 3D worlds, and the method successfully synthesizes expansive, realistic, and 3D-consistent worlds by exploiting this understanding.
Now, I will proceed to generate the summary in the requested format, including metadata, four sections, and figure information.
I'll select the following figures for Part 2:
- Figure 1 : Overall architecture.
2603.19708v1/x1.png - Figure 2 : Method overview.
2603.19708v1/x2.png - Figure 5 : Qualitative baseline comparison.
2603.19708v1/x5.png
Let's double-check the figure URLs. They are relative, so I need to prepend https://arxiv.org/html/.
- Figure 1:
https://arxiv.org/html/2603.19708v1/x1.png - Figure 2:
https://arxiv.org/html/2603.19708v1/x2.png - Figure 5:
https://arxiv.org/html/2603.19708v1/x5.png
Okay, all looks good to proceed with the summary generation. 저자: Ziya Erkoç, Angela Dai, Matthias Nießner
1. Key Terms & Definitions (핵심 용어 및 정의)
- 2D Foundation Image Models : 인터넷 규모의 2D 이미지 데이터셋으로 학습되어 높은 Fidelity의 이미지 생성 능력과 깊은 Semantic Understanding을 갖춘 모델 (예: Flux.2, NanoBanana).
- Vision-Language Model (VLM) : 이미지와 텍스트를 동시에 이해하고 추론할 수 있는 모델로, 본 논문에서는 Director 및 Verifier Agent의 핵심 구성 요소로 활용됩니다.
- 3D Gaussian Splatting (3DGS) : 3D 장면을 불투명한 가우시안 포인트 클라우드로 표현하는 기술로, Novel View Synthesis 및 3D Reconstruction에 사용되며, 본 논문에서 최종 3D 장면 표현에 활용됩니다.
- Sequential Inpainting : 기존 이미지의 알려진 영역을 기반으로 새로운, 가려진 또는 확장된 영역을 생성하는 이미지 Inpainting 기법으로, 2D 모델의 3D 공간 이해를 유도하기 위해 사용됩니다.
- Multi-Agent Architecture : 특정 목표를 달성하기 위해 상호 협력하는 여러 전문화된 Agent (Director, Generator, Verifier)로 구성된 시스템입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 2D Foundation Models는 Text-to-Image Diffusion을 통해 탁월한 High-fidelity 이미지 생성 능력과 깊은 Semantic Understanding을 보여주었습니다. 이러한 모델들이 방대한 2D 이미지 데이터셋으로 학습되었기 때문에, 저자들은 이 모델들이 암묵적으로 Underlying 3D Spatial Structures 및 Physical Rules을 학습했을 것이라는 가설을 세웠습니다. 이에 대한 핵심 질문은 "2D Foundation Image Models가 본질적으로 3D World Model 역량을 가지고 있는가?"입니다.
기존 3D Generation Methods는 Diverse하고 High-quality의 3D Training Data 부족 또는 Score Distillation Sampling을 통한 Multi-view Consistency 유지의 높은 Computational Complexity에 의해 제약을 받았습니다. 단일 Pass의 2D 모델 Prompting으로는 Pixel-perfect한 Cross-view Consistency를 보장하기 어렵습니다. 따라서 본 연구는 2D Foundation Models의 잠재적인 암묵적 3D 역량을 활용하여 일관된 3D World Generation을 가능하게 하는 새로운 Agentic Method의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
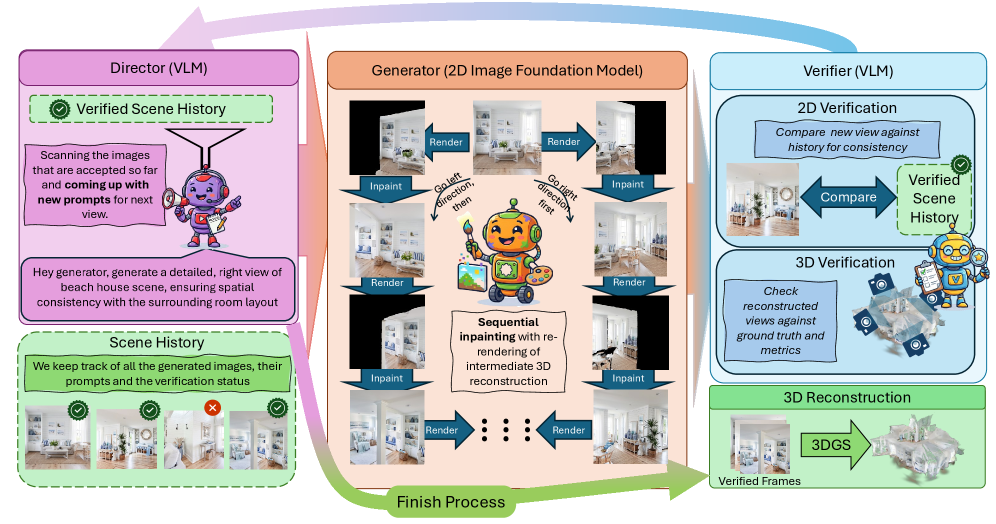
저자들은 3D Scene Generation을 세 가지 전문 Agent로 구성된 Multi-agent Process로 정의하는 WorldAgents 방법을 제안합니다 [Figure 1, Figure 2]. 이 Agent들은 2D Image Generation Models를 활용하여 Coherent한 3D Worlds를 재구성합니다.
- VLM Director Agent (𝒟\mathcal{D}) : High-level Planner 역할을 수행하며, 생성된 World State (𝒲t\mathcal{W}{t})와 Global Text Prompt (y)를 기반으로 다음 Logical Viewpoint를 위한 View-specific Text Prompt (yt+1y{t+1})를 동적으로 생성합니다. 이는 Semantic Drift를 방지하고 Scene의 Semantic Evolution을 유도합니다.
- Image Generator Agent (𝒢\mathcal{G}) : Director가 제공한 Semantic Conditioning (yt+1y_{t+1})과 Geometric Transformation (Pt+1P_{t+1})에 따라 Candidate View (I^t+1\hat{I}{t+1})를 합성합니다. Generator는 Reconstructed 3DGS Scene (Θt\Theta{t})에서 Novel View (Pt+1P_{t+1})로 Re-render된 It+1warpI^{\text{warp}}{t+1}를 2D Foundation Model (𝒢inpaint\mathcal{G}{\text{inpaint}})의 Inpainting Input으로 활용하여 Unobserved Regions을 채웁니다. 이를 통해 기존 Geometry와의 Rigorous Alignment를 유지하면서 새로운 영역을 생성합니다.
- VLM 2-Stage Verifier Agent (𝒱\mathcal{V}) : 생성된 이미지의 품질 관리 메커니즘으로, 2D Semantic Check과 3D Reconstruction-space Check의 두 단계로 Candidate View를 평가합니다.
- Image-Space Verification : VLM (𝒱2D\mathcal{V}_{\text{2D}})을 사용하여 Candidate View의 Semantic Coherence 및 Visual Quality를 평가하고, Artifacts나 Prompt Misalignment를 감지합니다.
- 3D Reconstruction-Space Verification : Candidate View (I^t+1\hat{I}{t+1})를 Provisional 3DGS Model (Θt+1′\Theta^{\prime}{t+1})에 통합한 후, 모든 Historical Camera Poses에서 Re-render하여 PSNR, SSIM, LPIPS와 같은 Novel View Synthesis Metrics를 계산합니다. 이 Metric Scores와 Visual Image Pairs를 Dedicated VLM (𝒱3D\mathcal{V}_{\text{3D}})에 전달하여 Global Geometric Stability를 평가합니다. 최종 수락 결정은 2D 및 3D 검증 단계의 논리적 연결 (v2D∧v3D)입니다.
실험 결과, 제안된 WorldAgents는 기존 State-of-the-art 방법인 Text2Room [hollein2023text2room] 및 WorldExplorer [schneider2025worldexplorer] 대비 우수한 성능을 보여줍니다. 특히, Flux.2 [Pro] + GPT 4.1 조합은 CLIP Score 26.79 , Inception Score 2.26 , CLIP-IQA 0.89 를 달성하며 Baseline 대비 높은 Prompt Alignment 및 Overall Scene Quality를 입증했습니다 [Table 1]. 정성적 비교에서도 본 방법은 더욱 Rich한 Geometric Details와 High Object Density를 가진 Sci-fi Room을 생성하는 반면, Baseline은 Sparse하고 Structural Realism이 부족한 Scene을 생성합니다

Ablation Study를 통해 Director Agent, Verifier Agent, 그리고 Sequential Inpainting의 각 구성 요소가 Scene Completion, Structural Diversity 및 Rigorous 3D Consistency 유지에 중요하게 기여함을 확인했습니다 [Table 2, Figure 6].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 2D Foundation Image Models가 3D World Model 역량을 내재하고 있는지에 대한 근본적인 질문에 답을 제시했습니다. VLM-based Director, Image Generator, 그리고 2단계 Verifier로 구성된 Multi-agent Framework를 도입함으로써, 2D 모델에서 암묵적인 3D 지식을 성공적으로 추출할 수 있음을 입증했습니다.
WorldAgents의 Agentic Approach는 Expansive하고 Robust하며 3D-consistent한 Scene Reconstructions를 가능하게 하여 Novel View Rendering을 지원합니다. 이 연구는 2D Foundation Models가 3D Worlds에 대한 깊은 이해를 내포하고 있음을 명확히 확인했으며, 이는 3D Scene Synthesis 분야에 새로운 패러다임을 제시할 수 있습니다. 향후 연구는 이 Multi-agent Framework를 Video Diffusion Models 또는 Dynamic 4D Scene Generation으로 확장하여 더욱 Interactive한 World Synthesis를 탐구할 수 있습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] STEP3-VL-10B Technical Report
- [논문리뷰] Asking like Socrates: Socrates helps VLMs understand remote sensing images
- [논문리뷰] RAISECity: A Multimodal Agent Framework for Reality-Aligned 3D World Generation at City-Scale
- [논문리뷰] Visual Representation Alignment for Multimodal Large Language Models
- [논문리뷰] Matrix-3D: Omnidirectional Explorable 3D World Generation
Review 의 다른글
- 이전글 [논문리뷰] Versatile Editing of Video Content, Actions, and Dynamics without Training
- 현재글 : [논문리뷰] WorldAgents: Can Foundation Image Models be Agents for 3D World Models?
- 다음글 [논문리뷰] s2n-bignum-bench: A practical benchmark for evaluating low-level code reasoning of LLMs
댓글