[논문리뷰] TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
링크: 논문 PDF로 바로 열기
저자: Yan Shu, Bin Ren, Zhitong Xiong, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Vision-Language Models (VLMs) : 시각적 콘텐츠와 자연어를 모두 이해하여 텍스트 기반 상호작용을 통해 유연한 분석을 가능하게 하는 통합 모델입니다.
- Earth Observation (EO) : 위성 이미지를 통해 지구를 지속적으로 모니터링하여 환경 모니터링, 재난 대응, 자원 관리 등에 활용하는 분야입니다.
- Pixel-Grounded Reasoning : 모델이 태스크 관련 영역을 픽셀 수준의 시각적 증거에 명시적으로 grounding하고 각 추론 단계를 픽셀 단위로 설명하는 방식입니다.
- Chain-of-Thought (CoT) : 모델이 최종 답변에 도달하기까지의 중간 추론 단계를 텍스트로 설명하는 기법이며, 본 논문에서는 시각적 grounding을 interleaved하여 사용합니다.
- Terra-CoT : Pixel-grounded CoT를 위한 대규모 instruction-tuning dataset으로, 추론 체인에 픽셀 수준의 마스크가 포함되어 있습니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Earth Observation (EO) 분야에서 Vision-Language Models (VLMs)의 가능성에도 불구하고, 기존 VLM들은 픽셀 수준의 정밀한 공간 추론 과 다중 센서 및 시간 경과 데이터 통합 에 어려움을 겪고 있습니다. 예를 들어, 이미지 내 특정 land-cover 클래스의 coverage 계산과 같은 기본적인 EO 태스크에서 GPT-4o나 Qwen3-VL과 같은 선도적인 범용 모델들은 정확한 답변을 제공하지 못합니다 [Figure 1(a-1), Figure 1(a-2)]. 이는 자연 이미지의 discrete한 객체와 달리 EO 이미지는 연속적인 공간 분포 를 다루며, 기존 VLM의 coarse-grained grounding (예: bounding box)은 이러한 연속성으로 인해 정확도를 저해하기 때문입니다. 또한, 기존 VLM들은 optical, SAR 등 다양한 modality와 multi-temporal 데이터를 단일 프레임워크 내에서 효과적으로 통합하여 추론하는 데 한계를 보입니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
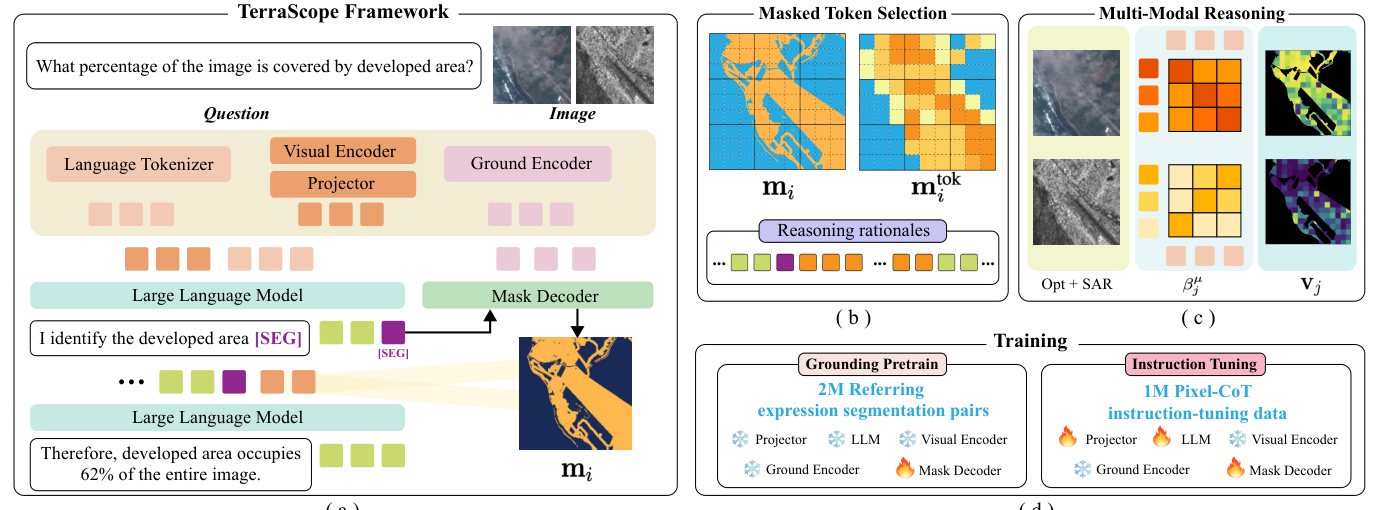
저자들은 이러한 문제를 해결하기 위해 TerraScope 라는 통합 VLM 프레임워크를 제안합니다. TerraScope는 Pixel-Grounded Chain-of-Thought (CoT) 를 핵심으로 하며, [SEG] 토큰을 감지하면 마스크 디코더가 segmentation mask를 생성하고, 해당 영역에서 마스킹된 visual feature를 추출하여 추론 시퀀스에 주입함으로써 픽셀 수준의 시각적 grounding을 동적으로 가능하게 합니다 [Figure 1(a-3), Figure 2(a)].
TerraScope는 두 가지 핵심 기능을 제공합니다:
- Modality-flexible reasoning : optical 및 SAR와 같은 단일 모달리티 입력뿐만 아니라, 두 모달리티를 모두 사용할 수 있을 때 텍스트 기반 cross-attention을 통해 가장 정보성 있는 모달리티를 적응적으로 융합 합니다 [Figure 2(c)]. 이를 통해 클라우드에 가려진 영역에서는 SAR 데이터를, 스펙트럼 정보가 풍부한 영역에서는 optical 데이터를 활용합니다.
- Multi-temporal reasoning : 여러 시점의 관측 데이터를 통합하여 시간적 변화 분석 을 수행합니다. 이를 위해
Image: ti와 같은 명시적인 temporal indicator를 활용합니다.
모델 훈련을 위해 저자들은 픽셀 수준 마스크가 추론 체인에 포함된 1M 규모의 Terra-CoT instruction-tuning dataset 을 구축했습니다. 또한, TerraScope-Bench 라는 새로운 벤치마크를 제안하여 Coverage Percentage Analysis, Absolute Area Quantification, Comparative Area Ranking, Boundary Relationship Detection, Distance Measurement, Building Change Estimation 등 6가지 세부 태스크에 대해 answer accuracy와 mask quality의 듀얼 평가 지표 를 사용하여 모델의 pixel-grounded reasoning 능력을 검증합니다 [Figure 1(c)].
실험 결과, TerraScope 는 다양한 벤치마크에서 기존 VLM들을 크게 능가했습니다
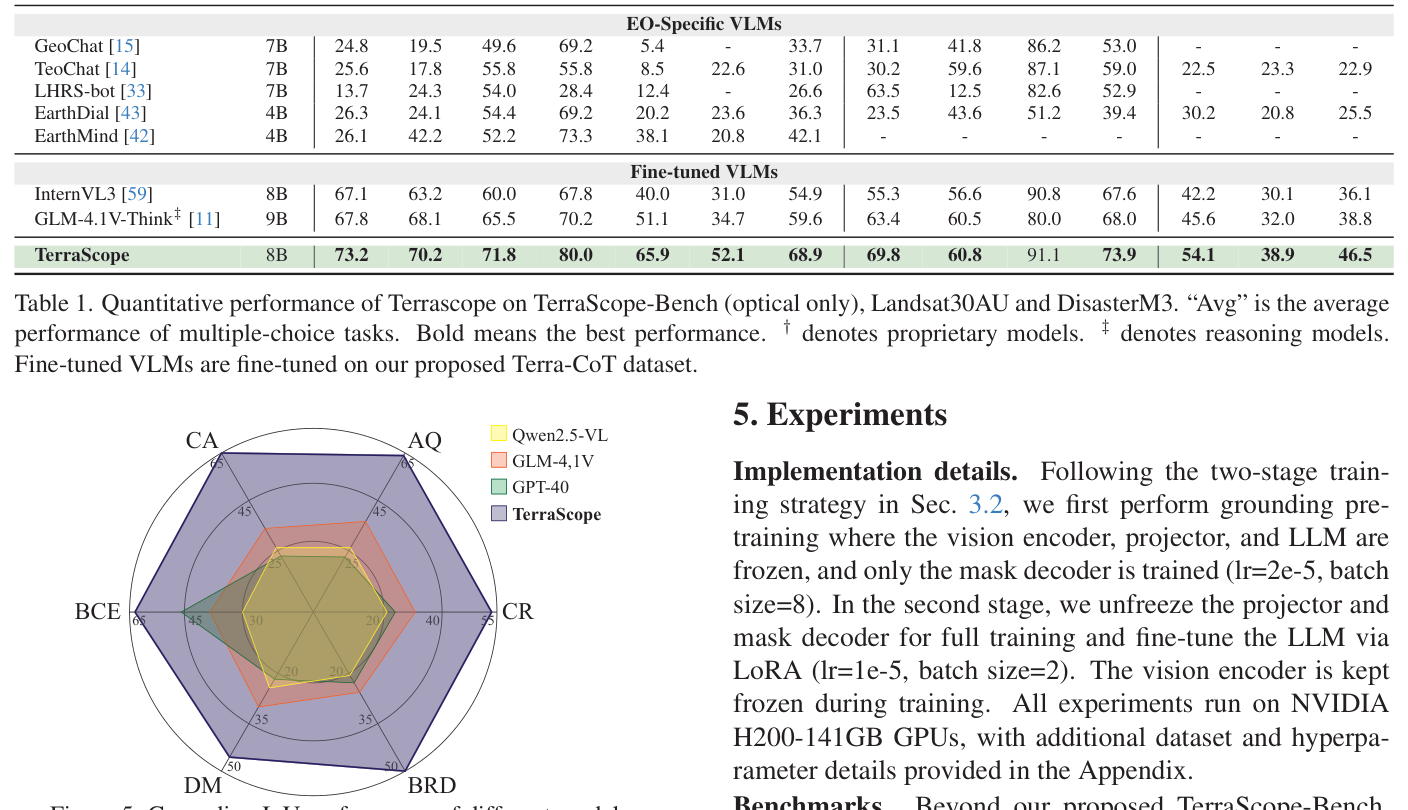
TerraScope-Bench에서 TerraScope는 평균 68.9%의 정확도 를 달성하여, reasoning-enhanced VLM인 GLM-4.1V-Think의 41.4% 및 Qwen3-VL-Think의 43.3% 를 크게 상회했습니다. Landsat30AU 벤치마크에서는 TerraScope가 평균 79.36%의 정확도 로 다른 모든 모델을 앞섰으며, DisasterM3 벤치마크에서도 평균 46.5% 를 기록하여 기존 모델 대비 우수한 성능을 보였습니다. 특히, fine-tuned VLMs(InternVL3, GLM-4.1V-Think)는 Terra-CoT 데이터셋으로 fine-tuning된 후 TerraScope-Bench에서 각각 54.9% , 59.6% 로 성능이 크게 향상되었으나, TerraScope의 68.9% 에는 미치지 못했습니다. 이는 TerraScope의 pixel-grounded reasoning 방식이 EO 데이터의 fine-grained geospatial reasoning에 필수적임을 보여줍니다. Grounding IoU 측면에서도 TerraScope는 다른 모델 대비 확연히 높은 성능을 보이며, 정답 예측과 마스크 품질 간의 강한 Pearson 상관관계를 보여 pixel-accurate visual grounding의 중요성을 입증했습니다.
4. Conclusion & Impact (결론 및 시사점)
TerraScope는 Earth Observation을 위한 pixel-grounded geospatial reasoning 을 제공하는 통합 VLM 프레임워크입니다. 이 연구는 segmentation mask 생성과 추론 trace를 함께 생성함으로써 정밀하고 해석 가능한 공간 분석을 가능하게 합니다. 또한, multi-temporal 변화 분석과 optical 및 SAR 모달리티 전반에 걸친 adaptive reasoning을 지원합니다. Terra-CoT 데이터셋과 TerraScope-Bench 벤치마크는 pixel-grounded geospatial reasoning 분야의 훈련 및 평가를 위한 중요한 자원으로 활용될 것입니다. TerraScope는 기존 VLM들이 EO 데이터의 fine-grained spatial analysis에서 겪는 한계를 극복하며, 해석 가능한 시각적 증거를 제공함으로써 EO 분야의 발전에 크게 기여할 것입니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Revisiting the Necessity of Lengthy Chain-of-Thought in Vision-centric Reasoning Generalization
- [논문리뷰] Chain-of-Visual-Thought: Teaching VLMs to See and Think Better with Continuous Visual Tokens
- [논문리뷰] 4DThinker: Thinking with 4D Imagery for Dynamic Spatial Understanding
- [논문리뷰] Video Streaming Thinking: VideoLLMs Can Watch and Think Simultaneously
- [논문리뷰] HomeSafe-Bench: Evaluating Vision-Language Models on Unsafe Action Detection for Embodied Agents in Household Scenarios
Review 의 다른글
- 이전글 [논문리뷰] TAPESTRY: From Geometry to Appearance via Consistent Turntable Videos
- 현재글 : [논문리뷰] TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
- 다음글 [논문리뷰] Versatile Editing of Video Content, Actions, and Dynamics without Training
댓글