[논문리뷰] TAPESTRY: From Geometry to Appearance via Consistent Turntable Videos
링크: 논문 PDF로 바로 열기
Please note that if the PDF link was browsed, the tool will not return its content. The paper "TAPESTRY: From Geometry to Appearance via Consistent Turntable Videos" introduces a framework for generating high-fidelity, geometrically consistent turntable videos (TTVs) for untextured 3D models and using them for texture synthesis and neural rendering.
Let's extract the necessary information for the summary and JSON.
Authors: Longwen Zhang, Qixuan Zhang, Kaixin Yao, Haoran Jiang, Yan Zeng, Lan Xu, Jingyi Yu Keywords: Video Generation, 3D Texturing, Geometric Consistency, Turntable Video, Diffusion Models, Neural Rendering. (I need to pick 5-8, aiming for 6-7).
Key Terms & Definitions:
- Turntable Video (TTV) : 360-degree rotational videos of an object, providing dynamic views.
- Geometric Consistency : Maintaining strict structural and appearance stability of an object across all views in a video.
- 3D-Aware Inpainting : A process to fill self-occluded regions in a texture map by generating new views conditioned on existing textured parts, ensuring global consistency.
- Diffusion Transformer (DiT) : A type of Diffusion Model that uses a Transformer architecture for denoising, which is the backbone of the TAPESTRY video generation.
- 3D Gaussian Splatting (3DGS) : A real-time radiance field rendering method used for neural rendering, which can be supervised by TAPESTRY's consistent TTVs.
Motivation & Problem Statement:
- Automatically generating photorealistic and self-consistent appearances for untextured 3D models is a significant challenge in digital content creation.
- Traditional methods require manual artistic effort, which is time-consuming, labor-intensive, and not scalable.
- Existing general-purpose video diffusion models struggle with maintaining strict geometric consistency, SKU identity, metric scale, and appearance stability across 360-degree views, leading to outputs unsuitable for high-quality 3D reconstruction.
- Minor inconsistencies (content drift, jitter) in TTVs break the 3D illusion and lead to severe artifacts (seams, ghosting, blurring) in downstream 3D tasks like UV texture mapping or training neural rendering models.
Methodology & Key Results:
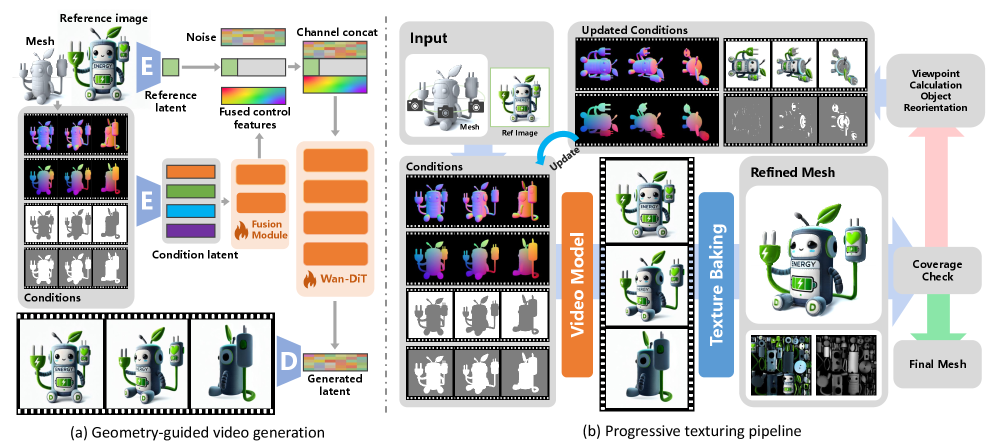
- TAPESTRY redefines 3D appearance generation as a geometry-conditioned video diffusion problem. It takes a 3D mesh as input and renders multi-modal geometric features (Normal Video, Position Map Video) to constrain the video generation with pixel-level precision.
- Geometry-guided Video Generation : The system uses a Diffusion Transformer (DiT) backbone, augmented by concatenating noisy latent with geometric condition latents and a reference frame latent. Text prompts are fed into cross-attention layers. This ensures strict adherence to 3D geometry and desired style.
- High-Fidelity Texturing from Video : To address self-occlusion and achieve complete surface coverage, a progressive texturing pipeline with 3D-Aware Inpainting is introduced. This involves iterative, context-aware generation passes where the object is rotated to expose untextured regions, and new content is generated conditioned on existing textures and an inpainting mask.
- Quantitative Results : TAPESTRY significantly outperforms baselines in both video consistency and final reconstruction quality.
- Video Metrics (Table 1) : For generated Turntable Videos, TAPESTRY achieved:
- PSNR : 25.79 (↑) compared to 23.48 (Wan2.1-Fun Depth) and 23.21 (Diffusion as Shader).
- SSIM : 0.924 (↑) compared to 0.904 (Wan2.1-Fun Depth) and 0.906 (Diffusion as Shader).
- LPIPS : 0.066 (↓) compared to 0.084 (Wan2.1-Fun Depth) and 0.090 (Diffusion as Shader).
- FVD : 189.9 (↓) compared to 277.9 (Wan2.1-Fun Depth) and 295.7 (Diffusion as Shader).
- Texture Metrics (Table 2) : For generated textures, TAPESTRY achieved:
- FID : 26.90 (↓) compared to 43.47 (Paint3D) and 30.68 (MV-Adapter).
- KID : 16.21 (↓) compared to 36.63 (Paint3D) and 25.73 (MV-Adapter).
- CLIP-S : 0.9488 (↑) compared to 0.8880 (Paint3D) and 0.9291 (MV-Adapter).
- Video Metrics (Table 1) : For generated Turntable Videos, TAPESTRY achieved:
- Ablation Studies (Table 3) showed the importance of both Normal and Position maps for optimal performance, achieving the best PSNR, SSIM, LPIPS, and FVD when both are used. Qualitative results also showed "Naive Fusion" suffers from visible seams and color shifts, unlike TAPESTRY's context-aware inpainting.
Conclusion & Impact:
- TAPESTRY effectively solves the critical problem of generating high-fidelity, geometrically consistent appearances for untextured 3D models.
- The framework's ability to produce structurally stable and drift-free TTVs serves as a robust intermediate representation for automated content creation.
- This research significantly advances automated 3D asset creation, offering high-quality dynamic previews and a reliable data source for downstream tasks like UV texturing or training neural representations (e.g., 3D Gaussian Splatting ).
- The method is efficient, trainable on a single DGX Spark supercomputer, making it feasible for low-budget settings and facilitating interactive 3D web visualization.
Important Figures for JSON:
- Figure 1: Teaser image, overall idea.
- Figure 2: Architecture overview. (Crucial for method explanation)
- Figure 3: Qualitative results of TAPESTRY, showing the consistent TTV and textured asset. (Important for results)
- Figure 4: Qualitative comparison (video consistency).
- Figure 5: Qualitative comparison (textured mesh).
- Figure 6: Ablation on inpainting.
- Figure 7: TTVs supervising neural assets (3DGS).
I will choose:
- Figure 2: Architecture overview. (Most important to explain the method).
- Figure 3: Qualitative results of TAPESTRY. (Shows the output effectively).
- Figure 5: Qualitative comparison on textured mesh. (Demonstrates improvement over baselines).
Now, I'll find the image URLs for these figures.
- Figure 1:
2603.17735v1/figures/teaser.png->https://arxiv.org/html/2603.17735v1/figures/teaser.png - Figure 2:
2603.17735v1/x1.png->https://arxiv.org/html/2603.17735v1/x1.png - Figure 3:
2603.17735v1/x2.png->https://arxiv.org/html/2603.17735v1/x2.png - Figure 4:
2603.17735v1/figures/comparison_video.jpg->https://arxiv.org/html/2603.17735v1/figures/comparison_video.jpg - Figure 5:
2603.17735v1/x3.png->https://arxiv.org/html/2603.17735v1/x3.png - Figure 6:
2603.17735v1/figures/ablation_inpaint.png->https://arxiv.org/html/2603.17735v1/figures/ablation_inpaint.png - Figure 7:
2603.17735v1/figures/gaussian.jpg->https://arxiv.org/html/2603.17735v1/figures/gaussian.jpg
My choices are Figure 2, Figure 3, Figure 5.
- Figure 2:
https://arxiv.org/html/2603.17735v1/x1.png, "제안 모델의 전체 아키텍처" - Figure 3:
https://arxiv.org/html/2603.17735v1/x2.png, "TAPESTRY 정성적 결과" - Figure 5:
https://arxiv.org/html/2603.17735v1/x3.png, "질감 메시 정성적 비교"
One correction on Figure 3 in the paper content. Figure 3 is linked to 2603.17735v1/x2.png and Figure 5 to 2603.17735v1/x3.png. Figure 2 is 2603.17735v1/x1.png. This means the x1.png, x2.png, x3.png are the figures I want to refer to.
Let me double check the figure numbers in the paper.
Figure 1: teaser.png
Figure 2: x1.png
Figure 3: x2.png
Figure 4: comparison_video.jpg
Figure 5: x3.png
Figure 6: ablation_inpaint.png
Figure 7: gaussian.jpg
My chosen figures are:
- Figure 2 : Overall architecture (
x1.png). - Figure 3 : Qualitative results of TAPESTRY (
x2.png). - Figure 5 : Qualitative comparison on textured mesh (
x3.png).
All set. I will now write the summary. 저자: Yan Zeng, Haoran Jiang, Kaixin Yao, Qixuan Zhang, Longwen Zhang, Lan Xu, Jingyi Yu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Turntable Video (TTV) : 360도로 회전하는 객체의 영상으로, 다양한 시점에서의 동적 외관을 제공하는 표준 형식입니다.
- Geometric Consistency : 3D 모델의 구조와 외관이 360도 회전하는 전체 영상 시퀀스에 걸쳐 엄격하게 안정적으로 유지되는 특성을 의미합니다.
- 3D-Aware Inpainting : 자체적으로 가려진(self-occluded) 영역의 텍스처를 메우기 위해 기존 텍스처 정보를 컨텍스트로 활용하여 새로운 시점을 생성하는 메커니즘으로, 전역적인(global) 일관성을 보장합니다.
- Diffusion Transformer (DiT) : Diffusion 모델의 한 종류로, Transformer 아키텍처를 사용하여 디노이징(denoising) 과정을 수행하며 TAPESTRY의 핵심 비디오 생성 백본으로 활용됩니다.
- 3D Gaussian Splatting (3DGS) : 실시간 Radiance Field 렌더링을 위한 기술로, TAPESTRY가 생성한 고도로 일관된 TTV를 훈련 신호로 활용할 수 있습니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Untextured 3D 모델에 대해 사진처럼 사실적이고 자체 일관성(self-consistent) 있는 외관을 자동으로 생성하는 것은 디지털 콘텐츠 제작 분야에서 중요한 도전 과제입니다. 기존의 텍스처링 워크플로우는 아티스트의 수동 작업에 크게 의존하여 시간과 노동력이 많이 소요되며, 대규모 자산 라이브러리에는 확장하기 어렵습니다. 대규모 비디오 생성 모델의 발전으로 360도 Turntable Video (TTV)를 직접 합성하는 새로운 가능성이 열렸지만, 기존의 일반적인 비디오 Diffusion 모델은 전체 시점에 걸쳐 엄격한 Geometric Consistency 와 외관 안정성(appearance stability)을 유지하는 데 어려움을 겪습니다. 이러한 모델의 출력은 SKU identity , metric scale 을 유지하지 못하고 multi-head/Janus problem 을 유발하여 고품질 3D 재구성에 적합하지 않은 content drift 또는 jitter 와 같은 사소한 불일치(inconsistency)가 발생합니다. 이는 최종 3D 모델에서 seam, ghosting, blurring과 같은 심각한 아티팩트로 나타나, 3D 환상을 깨고 제품 시각화에 필요한 엄격한 시각적 안정성을 저해합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 untextured 3D mesh에 대한 고품질 외관 생성을 geometry-conditioned video diffusion problem 으로 재정의하고, TAPESTRY 프레임워크를 제안합니다. 이 프레임워크는 명시적인 3D 기하학 정보에 기반하여 고도로 일관된 Turntable Video (TTV) 를 생성하며, 이를 중간 표현(intermediate representation)으로 활용하여 텍스처 합성 및 뉴럴 렌더링을 수행합니다.
TAPESTRY의 핵심 방법론은 다음과 같습니다:
- Geometry-guided Video Generation : 3D mesh가 주어지면, Normal Video와 Position Map Video와 같은 multi-modal geometric features를 렌더링하고 인코딩하여 비디오 생성 프로세스에 픽셀 수준의 정밀한 제약(pixel-level precision)을 가합니다. 이를 통해 강력한 3D 일관성을 지닌 TTV 를 생성합니다. Geometry fusion module은 이 기하학적 잠재 정보(geometric latent)를 효율적으로 융합하며, Diffusion Transformer (DiT) 백본에 채널 단위로 연결(channel-wise concatenation)하여 주입됩니다.
- High-Fidelity Texturing from Video : 생성된 TTV 를 바탕으로, 3D-Aware Inpainting 메커니즘을 포함하는 점진적 텍스처링 파이프라인(progressive texturing pipeline)을 설계합니다. 이는 객체를 회전시키고 이미 생성된 콘텐츠를 컨텍스트로 활용하여 자체 가려진(self-occluded) 영역을 채워 완전한 표면 커버리지(full surface coverage)를 달성합니다. Multi-view Texture Projection과 Multi-Stage Texture Fusion을 통해 각 프레임의 픽셀 정보를 UV 공간에 백-프로젝션하고, 가중치 합산(weighted summation)으로 초기 텍스처 맵을 생성한 후 반복적인 context-aware completion 을 통해 일관된 최종 텍스처 맵을 만듭니다.
실험 결과, TAPESTRY는 기존 SOTA(State-of-the-Art) 접근 방식 대비 비디오 일관성 및 최종 재구성 품질 모두에서 월등한 성능을 보입니다.
- Turntable Video 성능 : 정량적 평가에서 TAPESTRY는 PSNR 25.79 , SSIM 0.924 , LPIPS 0.066 , FVD 189.9 를 달성하여,
Wan2.1-Fun(Depth) 및Diffusion as Shader와 같은 baseline 모델들을 크게 앞섰습니다. 특히, PSNR 과 SSIM 은 높을수록 좋고, LPIPS 와 FVD 는 낮을수록 좋은 지표입니다. - Texture Generation 성능 : 최종 텍스처 맵 품질 평가에서 TAPESTRY는 FID 26.90 , KID 16.21 , CLIP-S 0.9488 을 기록하여
Paint3D,HY3D-2.0,TEXGen,MV-Adapter등 기존 이미지-투-텍스처(image-to-texture) 방법론들을 능가했습니다. - Ablation Study : 기하학적 조건(Normal, Position map)의 영향을 분석한 결과, 두 조건 모두를 사용하는 모델이 모든 지표에서 가장 우수한 성능을 보였습니다. 특히, context-aware inpainting 이 없는 "Naive Fusion" 방식은 명확한 seam과 색상 변화를 보인 반면, TAPESTRY의 파이프라인은 끊김 없이 전역적으로 일관된 결과를 생성했습니다.
4. Conclusion & Impact (결론 및 시사점)
TAPESTRY는 untextured 3D 모델의 고품질 3D 외관 생성을 위한 혁신적인 프레임워크를 제시합니다. 이 방법은 명시적인 3D 기하학 정보로 비디오 Diffusion 모델을 제약하여 구조적으로 안정적이고 content drift 가 없는 고도로 일관된 Turntable Video (TTV) 를 생성합니다. 이 고품질 TTV 는 3D-Aware Inpainting 을 포함하는 점진적 파이프라인을 통해 완전하고 끊김 없는 UV 텍스처를 생성하는 견고한 중간 데이터 소스 역할을 합니다.
TAPESTRY는 기존 SOTA 방법론들보다 일관되고 상세한 3D 자산을 생성하는 데 있어 월등한 성능을 입증하였으며, 이는 자동화된 콘텐츠 제작 분야에 큰 잠재력을 시사합니다. 또한, 이 연구는 NVIDIA DGX Spark 슈퍼컴퓨터에서 훈련될 수 있을 정도로 효율적이며, 높은 일관성 덕분에 3D Gaussian Splatting (3DGS) 과 같은 뉴럴 표현(neural representations)을 직접 구동하여 상호작용 가능한 3D 웹 시각화를 가능하게 합니다. 이는 디지털 콘텐츠 산업에서 3D 모델의 외관 생성 프로세스를 혁신하고, 접근 가능하며 고품질의 3D 자산 제작을 민주화하는 데 기여할 것으로 기대됩니다.


⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] WristWorld: Generating Wrist-Views via 4D World Models for Robotic Manipulation
- [논문리뷰] Avatar V: Scaling Video-Reference Avatar Video Generation
- [논문리뷰] MilliVid: Hierarchical Latents for Long-Range Consistency in Video Generation
- [논문리뷰] Latent Spatial Memory for Video World Models
- [논문리뷰] Physics in 2-Steps: Locking Motion Priors Before Visual Refinement Erases Them
Review 의 다른글
- 이전글 [논문리뷰] ProactiveBench: Benchmarking Proactiveness in Multimodal Large Language Models
- 현재글 : [논문리뷰] TAPESTRY: From Geometry to Appearance via Consistent Turntable Videos
- 다음글 [논문리뷰] TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
댓글