[논문리뷰] Repurposing Geometric Foundation Models for Multi-view Diffusion
링크: 논문 PDF로 바로 열기
저자: Wooseok Jang, Seonghu Jeon, Jisang Han, Jinhyeok Choi, Minkyung Kwon, Seungryong Kim, Saining Xie, Sainan Liu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Geometric Foundation Models : Depth Anything 3 (DA3) 또는 VGGT 와 같이 임의의 포즈가 지정되지 않은 뷰(unposed views)로부터 dense 3D reconstruction을 가능하게 하며, 카메라 파라미터와 depth map을 동시에 예측하는 모델입니다.
- Novel View Synthesis (NVS) : 기본 3D 장면과 일관성을 유지하면서 보이지 않는 시점(unseen viewpoints)을 예측하는 geometry-aware generation task로, 뷰 전반에 걸쳐 일관된 공간 구조와 가려진 영역의 기하학적으로 타당한 완성(geometrically plausible completion)을 요구합니다.
- Geometric Latent Diffusion (GLD) : 제안된 프레임워크로, geometric foundation model의 기하학적으로 일관된 feature space를 multi-view diffusion을 위한 latent space로 재활용합니다.
- Boundary Layer (k) : geometric foundation model의 multi-level hierarchy에서 명시적인 합성(explicit synthesis)을 수행하는 최적의 feature level을 의미하며, 이보다 깊은 feature들은 propagation을 통해, 얕은 feature들은 cascaded scheme을 통해 파생됩니다.
- Representation Autoencoder (RAE) : latent diffusion에서 기존 VAE 를 사전 학습된(pretrained), 고정된(frozen) vision encoder와 학습 가능한(trainable) decoder로 대체하여, encoder의 feature space를 diffusion latent space로 직접 사용하는 프레임워크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 latent space의 발전이 single-image generation에서 상당한 진전을 이끌었지만, Novel View Synthesis (NVS) 를 위한 최적의 latent space는 대부분 미탐색 상태로 남아있습니다. 특히, NVS 는 시점(viewpoint) 전반에 걸쳐 기하학적으로 일관된 생성(geometrically consistent generation)을 요구하지만, 기존 접근 방식들은 주로 view-independent VAE latent space에서 동작합니다. 이러한 기존 diffusion-based NVS 방법들은 외부 geometry conditioning(예: depth-based warping)을 활용하지만, 여전히 single-image synthesis 모델을 위해 설계된 latent space에 의존하여 기하학적으로 불일치한 결과(geometrically inconsistent outputs)를 초래할 수 있습니다. 본 연구의 핵심 문제는 외부에서 geometry를 주입하거나 감독하는 대신, 기하학적 구조가 이미 인코딩된 latent space를 어떻게 활용할 수 있는지에 대한 것입니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 geometric foundation model의 feature space를 multi-view diffusion의 latent space로 재활용하는 Geometric Latent Diffusion (GLD) 프레임워크를 제안합니다. 특히 Depth Anything 3 (DA3) 를 주요 backbone으로 채택하며, GLD 는 세 가지 단계로 구성됩니다
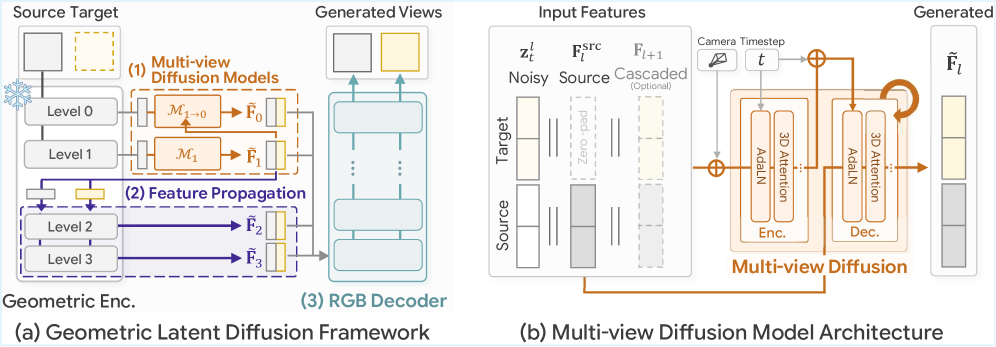
: (1) multi-view diffusion model은 cascaded generation을 통해 boundary layer k=1 까지 feature를 합성하고, (2) feature propagation을 통해 frozen DA3 encoder를 거쳐 더 깊은 feature들을 유도하며, (3) RGB decoder 가 완전한 multi-level features를 target views로 매핑합니다. 이 방법론은 DA3 feature space가 높은 충실도로(high-fidelity) 이미지 재구성(image reconstruction)을 지원하고 강력한 cross-view geometric correspondence를 인코딩한다는 것을 검증하는 것에서 시작합니다. 실제로, ViT-based decoder 를 훈련하여 DA3 의 multi-level features로부터 RGB 이미지를 재구성했을 때, PSNR 35.41 , SSIM 0.960 , LPIPS 0.019 의 우수한 성능을 보이며 고품질 재구성 능력을 입증했습니다 [Figure 3, Table 1].
가장 효율적인 boundary layer k 를 결정하기 위해, 저자들은 각 feature level을 합성하는 독립적인 diffusion model들을 훈련하고, 합성 경계(synthesis boundary)를 변경하면서 NVS 성능을 평가했습니다. 그 결과 k=1 (level 1까지 명시적 합성)이 RGB quality와 geometric accuracy 측면에서 가장 우수한 성능을 제공하며, PSNR 13.61 , SSIM 0.366 , LPIPS 0.555 , AbsRel 0.191 , RMSE 0.311 , δ<1.25 0.744 를 달성했습니다 [Table 2]. 또한, level 0 feature는 생성된 level 1 latent에 condition되어 합성되는 cascaded feature generation scheme을 사용하여 cross-level alignment를 보장합니다. 이 cascaded 접근 방식은 independent generation 대비 모든 2D 및 3D metric에서 일관된 성능 향상을 보였습니다 [Table 8].
GLD 는 RealEstate10K 및 DL3DV와 같은 in-domain 벤치마크와 Mip-NeRF 360과 같은 out-of-domain 벤치마크 전반에 걸쳐 2D image quality (PSNR, SSIM, LPIPS) 및 3D consistency metrics (ATE, RPE_r_, RPE_t_, Reproj, MEt3R) 모두에서 VAE 및 DINO baseline을 일관되게 능가합니다 [Table 3]. 특히, VAE latent space 대비 훈련 수렴 속도를 4.4배 이상 가속화하며, pose accuracy에서 baseline 대비 최대 2.8배 낮은 ATE 와 2.6배 낮은 RPE 를 달성합니다. [Table 3] 또한, 대규모 text-to-image pretraining 없이 small dataset에서 scratch부터 훈련되었음에도 불구하고, GLD 는 최첨단 NVS 방법들과 경쟁력 있는 성능을 유지합니다

GLD 는 또한 생성된 latent로부터 zero-shot depth 및 3D point cloud decoding을 가능하게 하며, Matrix3D 대비 더 정확한 depth estimation ( AbsRel 0.160 , SqRel 0.410 , δ1 0.800 )을 보여줍니다 [Table 9, Figure 7].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 geometric foundation model의 feature space를 Novel View Synthesis (NVS) 를 위한 latent space로 재활용하는 Geometric Latent Diffusion (GLD) 프레임워크를 제안합니다. 체계적인 분석을 통해 기하학적 correspondence와 photometric fidelity 사이의 균형을 이루는 최적의 feature level을 식별했습니다. 이 geometry-informed latent space에서 diffusion model을 훈련함으로써, GLD 는 표준 VAE 및 DINOv2 latent space 대비 2D image quality와 3D consistency 모두에서 일관된 성능 향상을 달성했습니다. GLD 는 대규모 text-to-image pretraining을 활용하는 최첨단 방법론들과 비교하여, scratch부터 훈련되었음에도 불구하고 경쟁력 있는 성능을 보여주며, zero-shot depth 및 3D reconstruction을 생성 프로세스의 자연스러운 부산물로 제공합니다. 이 연구는 geometry-aware generation을 위한 task-specific latent space design의 중요성을 강조하며, 해당 분야의 추가 연구를 장려할 것으로 기대됩니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LagerNVS: Latent Geometry for Fully Neural Real-time Novel View Synthesis
- [논문리뷰] TAPESTRY: From Geometry to Appearance via Consistent Turntable Videos
- [논문리뷰] SyncMV4D: Synchronized Multi-view Joint Diffusion of Appearance and Motion for Hand-Object Interaction Synthesis
- [논문리뷰] WristWorld: Generating Wrist-Views via 4D World Models for Robotic Manipulation
- [논문리뷰] VoxHammer: Training-Free Precise and Coherent 3D Editing in Native 3D Space
Review 의 다른글
- 이전글 [논문리뷰] REVERE: Reflective Evolving Research Engineer for Scientific Workflows
- 현재글 : [논문리뷰] Repurposing Geometric Foundation Models for Multi-view Diffusion
- 다음글 [논문리뷰] RoboAlign: Learning Test-Time Reasoning for Language-Action Alignment in Vision-Language-Action Models
댓글