[논문리뷰] REVERE: Reflective Evolving Research Engineer for Scientific Workflows
링크: 논문 PDF로 바로 열기
저자: Balaji Dinesh Gangireddi, Aniketh Garikaparthi, Manasi Patwardhan, et al.
1. Key Terms & Definitions
- REVERE (Reflective Evolving Research Engineer) :
Scientific Workflows에서Self-Adapting Agents를 구축하기 위한 프레임워크로,Global Training Context를 활용하여Execution Trajectories에서 반복되는Failure Modes를 학습하고Reusable Heuristics로 distillation하여Targeted Edits를 수행합니다. - Global Training Context (GTC) : REVERE 프레임워크의 핵심 요소로,
Cumulative Cheatsheet,Reflection History,Auxiliary Context세 가지 상호 보완적인Signal을 통합하여Training Iterations전반에 걸쳐Experience를Aggregate하고Local Feedback을 넘어선Adaptation을 가능하게 합니다. - Configurable Fields (𝐹) : 에이전트의 동작을 제어하는 세 가지 편집 가능한 컨텍스트 필드입니다:
System Prompt (𝐹_s),Task Prompt (𝐹_x), 그리고Cumulative Cheatsheet (𝐹_c). REVERE는 이 필드들을Optimizing하여Agent Behavior를 개선합니다. - Code-Based Field Update :
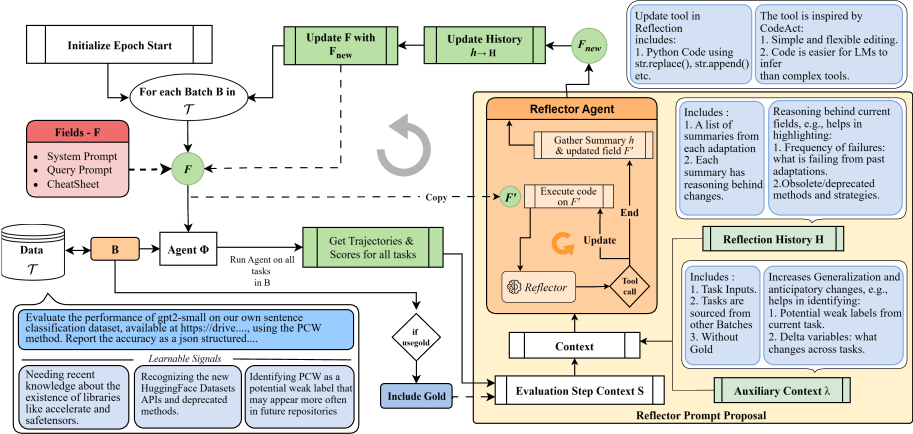
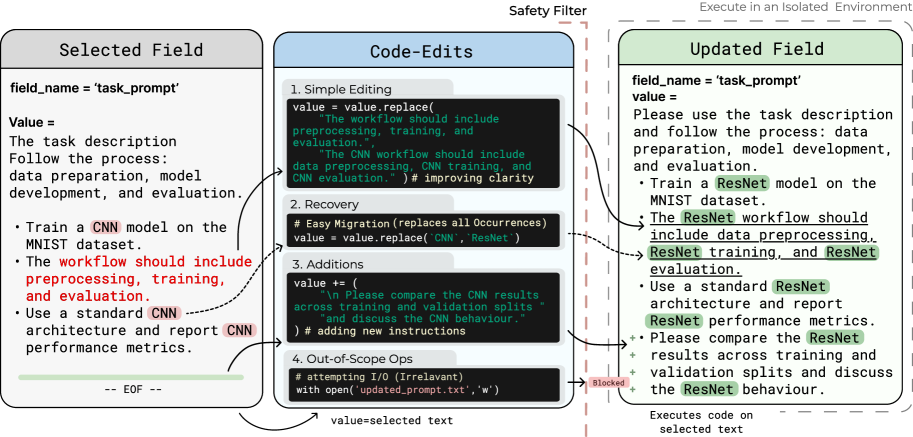
Reflector가Context Field의 특정 부분을 수정하기 위해 짧은Python Program을 생성하고 실행하는Mechanism입니다. 이는Semantic Drift와Knowledge Loss없이Targeted,Non-Destructive Update를 가능하게 합니다 [cite: 1, Figure 2]. - Research-Coding Workflows :
Long-Horizon,Heterogeneous Repositories,Underspecified Environments,Weak Feedback등의 특성을 가지며, 공개Codebases에서Results를Reproducing하는 것이 중요한Evaluation Regime인 복잡한Coding Tasks를 지칭합니다.
2. Motivation & Problem Statement
기존의 Prompt-Optimization Techniques는 주로 Local Signals에 의존하여 Behavior를 업데이트하며, 이로 인해 Generalization이 저하되고 Full-Prompt Rewrites나 Unstructured Merges 과정에서 Knowledge Loss가 발생합니다. 이러한 한계점은 Research-Coding Workflows에서 더욱 두드러집니다. Research-Coding Workflows는 Heterogeneous Repositories, Underspecified Environments, 그리고 Weak하고 Delayed Feedback을 특징으로 하며, Long-Horizon Tasks를 Coordinating하고 Tacit Assumptions를 Inferring하며 Heterogeneous Research Frameworks 전반에 걸쳐 Procedural Knowledge를 Accumulating해야 하는 Agent에 대한 근본적으로 다른 요구사항을 가집니다.
기존 Agentic Systems는 대개 Static Prompts에 의존하거나, Multi-Agent Workflows를 통해 High-Level Tasks를 Decompose하더라도 Fixed Contexts 및 Predefined Strategies 내에서 작동합니다. 결과적으로 이 시스템들은 Evolving Conventions 및 Diverse Open-Ended Nature를 가진 Research Coding Tasks에 Adapt하는 데 어려움을 겪습니다. Self-Refinement Methods는 Iterative Feedback을 통해 Reasoning을 개선하지만, Instance-Specific하게 남아 Generalizable Patterns를 학습하기보다 Recent Outcomes에 Overfit하는 경향이 있습니다. 또한, 대부분의 Prompt-Adaptation Frameworks는 Full Prompt Regeneration을 통해 Behavior를 업데이트하여 Semantic Drift 및 Knowledge Loss의 위험을 증가시킵니다. 이러한 Gaps를 해결하기 위해 Persistent Global Context 내에서 Recurring Failure Modes를 식별하고 Reusable Heuristics로 Distill하며 Targeted, Non-Destructive Updates를 적용할 수 있는 새로운 Agent의 필요성이 제기됩니다.
3. Method & Key Results
저자들은 Research-Coding Workflows에 특화된 Self-Adapting Agents를 구축하기 위한 프레임워크인 REVERE 를 제안합니다. REVERE는 Iterative Adaptation Loop를 통해 Coding Agent의 성능을 개선하며, Execution Feedback에 기반하여 세 가지 Configurable Fields(System Prompt, Task Prompt, Cumulative Cheatsheet)를 점진적으로 Editing합니다 [cite: 1, Figure 1]. 이 루프의 핵심 구성요소는 Global Training Context (GTC)인데, 이는 Cumulative Cheatsheet, Reflection History, Auxiliary Context로 구성되어 Training Iterations 전반에 걸쳐 Signals을 Aggregate하고 Local Feedback을 넘어선 Adaptation을 가능하게 합니다. Reflector Module은 Evaluation Step Context와 Global Training Context를 활용하여 Errors를 진단하고 Surgical Python-based Edits를 수행합니다. 특히, REVERE는 Full Prompt Regeneration 대신 Code-Based Field Update Mechanism을 도입하여 Reflector가 Python Program을 생성하여 필드의 관련 부분만 수정하도록 합니다. 이는 Semantic Drift를 방지하고 Targeted, Low-Overhead Updates를 가능하게 합니다 [cite: 1, Figure 2].
REVERE는 세 가지 Challenging Research-Coding Benchmarks(SUPER, ResearchCodeBench, ScienceAgentBench)에서 State-of-the-Art 성능을 달성했습니다.
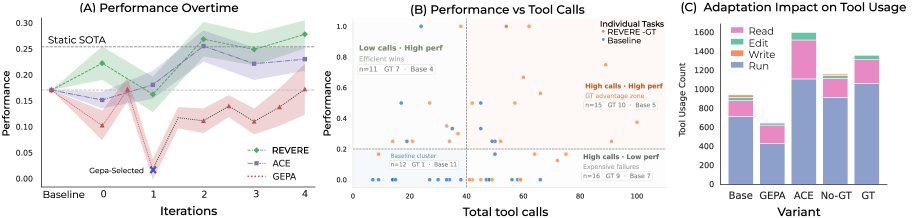
Offline Adaptation설정에서, REVERE는Ground Truth Hints유무와 관계없이Baseline대비Agent Performance를 향상시켰습니다 [cite: 1, Table 1]. 특히,SUPER벤치마크에서는Overall성능을Static SOTA대비 4.50% 증가한 29.8% 를 기록했습니다 [cite: 1, Table 1].ResearchCodeBench에서는Accuracy가Static SOTA대비 3.51% 증가한 33.2% 를 달성했으며 [cite: 1, Table 1],ScienceAgentBench에서는Success Rate가Static SOTA대비 4.89% 증가한 28.39% 를 기록했습니다 [cite: 1, Table 1].Online Adaptation설정에서도 REVERE는Minimal Feedback에도 불구하고Baseline대비 모든 벤치마크 및Metrics에서 일관된 성능 향상을 보여주었습니다 [cite: 1, Table 2]. 예를 들어,SUPER벤치마크의Overall성능은Baseline대비 8.10% 상승했습니다 [cite: 1, Table 2].Ablation Studies결과, REVERE의 모든Core Components, 특히Global Training Context가Effectiveness에 필수적임이 입증되었습니다 [cite: 1, Table 3]. 또한, REVERE는Controlled Prompt Growth를 유지하며 다른 대안적인Approaches대비 최대 10배 더Cost-Effective한Adaptation을 제공했습니다 [cite: 1, Figure 4C].
4. Conclusion & Impact
REVERE는 Multi-Step, Long-Horizon, Heterogeneous Research Coding Tasks를 다루는 LLM Agents를 위한 Lightweight, Unsupervised Adaptation Framework를 제시합니다. 이 연구는 Global Training Context를 통해 Reflection History, Auxiliary Context, Cumulative Cheatsheet를 Aggregate하고, Prompts에 Code-Level Edits를 발행하는 Update Mechanism을 지원하는 Agent Setup을 제안합니다. 이러한 디자인은 Context Myopia를 완화하고 기존 Agents에 쉽게 Integrate될 수 있는 Interpretable한 Adaptation을 가능하게 합니다.
REVERE는 SUPER, ResearchCodeBench, ScienceAgentBench 세 가지 Challenging Benchmarks에서 Baseline 및 기존 Prompt Adaptation Frameworks 대비 일관된 성능 향상을 보여주었으며, Static SOTA 대비 최대 4.89% 의 개선을 달성했습니다. 특히, REVERE는 다른 대안적인 솔루션에 비해 최대 10배 더 Cost-Effective한 Adaptation을 제공하여 LLM Agents의 Scalable Continual Self-Adaptation을 위한 실용적인 경로를 입증합니다 [cite: 1, Figure 4C]. 이 연구는 학계 및 산업계에 LLM Agents가 복잡한 Research-Coding Environments에서 장기적으로 Evolve하고 Adapt할 수 있는 잠재력을 보여주며, Continual Learning 및 Global Memory Consolidation Mechanism을 갖춘 Agents가 시간이 지남에 따라 Capabilities를 의미 있게 Evolve할 수 있음을 시사합니다. 향후 연구는 Domain-Heavy Benchmarks에서 Context Length Growth 관리와 Task-Specific Adaptation 방안을 탐색하는 데 집중될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Deep Tabular Research via Continual Experience-Driven Execution
- [논문리뷰] Memento-Skills: Let Agents Design Agents
- [논문리뷰] SCOPE: Prompt Evolution for Enhancing Agent Effectiveness
- [논문리뷰] Taming Modality Entanglement in Continual Audio-Visual Segmentation
- [논문리뷰] ACON: Optimizing Context Compression for Long-horizon LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] PivotRL: High Accuracy Agentic Post-Training at Low Compute Cost
- 현재글 : [논문리뷰] REVERE: Reflective Evolving Research Engineer for Scientific Workflows
- 다음글 [논문리뷰] Repurposing Geometric Foundation Models for Multi-view Diffusion
댓글