[논문리뷰] Memento-Skills: Let Agents Design Agents
링크: 논문 PDF로 바로 열기
저자: Huichi Zhou, Siyuan Guo, Anjie Liu, Jun Wang, et al.
1. Key Terms & Definitions
- Memento-Skills : LLM parameter 를 업데이트하지 않고도 deployment experience 를 통해 task-specific agent 를 자율적으로 구축, 적응, 개선하는 generalist , continually-learnable LLM agent system 입니다.
- Skill Memory ($M_t$) : 재사용 가능한 skill artefact 들의 유한하고 성장하는 컬렉션으로, 각 artefact 는 선언적 specification , prompt , 실행 가능한 code 를 포함하며, 에이전트의 영구적이고 진화하는 지식 기반 역할을 합니다.
- Read-Write Reflective Learning (RWRL) : 에이전트가 먼저 관련 skill 을 검색하고( Read phase ), execution feedback 을 기반으로 skill library 를 업데이트 및 확장하는( Write phase ) closed-loop learning mechanism 입니다. 이를 통해 LLM parameter 업데이트 없이 continual learning 이 가능합니다.
- Stateful Reflective Decision Process (SRDP) : 표준 MDP 를 확장하여 에이전트의 state 에 episodic memory $M_t$를 추가한 개념으로, 에이전트가 자신의 deployment experience 로부터 학습하고 skill library 가 진화함에 따라 Markov property 를 유지할 수 있도록 합니다.
- InfoNCE Routing : semantic similarity 가 아닌 execution success 에 최적화된 behavioral similarity 기반의 skill retrieval 을 위해 single-step offline RL 로 훈련된 behavior-aligned skill router 메커니즘입니다.
2. Motivation & Problem Statement
현대의 Large Language Models (LLMs) 은 few-shot learning , supervised fine-tuning , post-training 을 통해 다양한 시나리오에서 탁월한 성능을 보이지만, 실제 활용을 위해서는 막대한 데이터와 컴퓨팅 자원을 요구하는 parameter optimization 이 필수적입니다. 이로 인해 대부분의 LLM Agent 는 배포 시 frozen model 로 운영되며, 새로운 task 에 직면했을 때 pre-training 을 통해 학습된 지식과 제한된 context window 내 정보에만 의존하게 됩니다. 이러한 한계는 LLM parameter 를 업데이트하지 않고 deployment experience 로부터 지속적으로 학습하고 진화하는 continual adaptation 을 방해합니다. 저자들은 기존 연구들이 주로 human-designed agents 에 의존하여 task-specific agent 를 구성하는 반면, Memento-Skills 는 generalist agent 가 end-to-end 로 새로운 task 를 위한 agent 를 스스로 설계하고 개선할 필요성을 강조하며 이러한 문제에 대한 해답을 제시합니다.
3. Method & Key Results
Memento-Skills는 Read-Write Reflective Learning (RWRL) 루프를 핵심으로 하는 self-evolving agent 시스템을 제안합니다
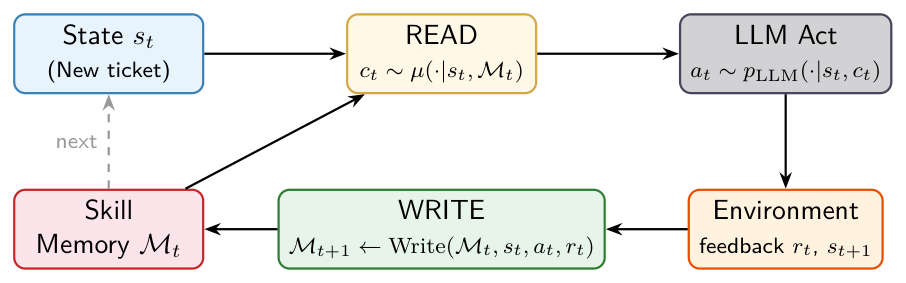
이 시스템은 executable skill 을 외부 memory unit 으로 간주하며, LLM parameter 를 frozen 상태로 유지하면서 deployment-time learning 을 통해 skill library ($M$) 를 지속적으로 진화시킵니다 [Figure 2]. Read phase 에서는 behavior-trainable skill router 가 현재 stateful prompt 에 맞춰 가장 관련성 높은 skill 을 선택합니다. 특히, InfoNCE routing [Figure 8] 메커니즘은 semantic similarity 가 아닌 execution success 를 최적화하는 behavioral similarity 기반의 skill retrieval 을 수행하여, 에이전트의 행동이 실제 task 해결에 더 효과적으로 부합하도록 합니다. Write phase 에서는 execution feedback 을 기반으로 skill 을 업데이트하고 확장합니다. 실패 사례 발생 시 LLM-based failure attribution selector 가 오류의 원인이 되는 skill 을 식별하고, skill rewriter 가 guardrail 또는 대체 전략을 추가하여 skill 의 generality 를 유지하면서 특정 실패 모드를 해결합니다. skill 의 utility 가 임계값 아래로 떨어지면, 시스템은 skill discovery 를 통해 기존 skill folder 를 재구성하거나 완전히 새로운 skill 을 생성하여 task space 의 새로운 영역을 커버합니다. 모든 mutation 은 automatic unit-test gate 를 통해 regression 을 방지하고 유효성을 검사합니다.
실험은 General AI Assistants (GAIA) 와 Humanity's Last Exam (HLE) 두 가지 벤치마크에서 이루어졌습니다. GAIA 벤치마크에서 Memento-Skills는 Read-Write ablation baseline 대비 13.7 percentage points 의 test accuracy 향상을 보이며 총 66.0% 의 정확도를 달성했습니다 [Figure 10]. HLE 벤치마크에서는 Read-Write baseline 의 17.9% 대비 38.7% 의 overall accuracy 를 기록하며 116.2% 의 relative improvement 를 달성했습니다
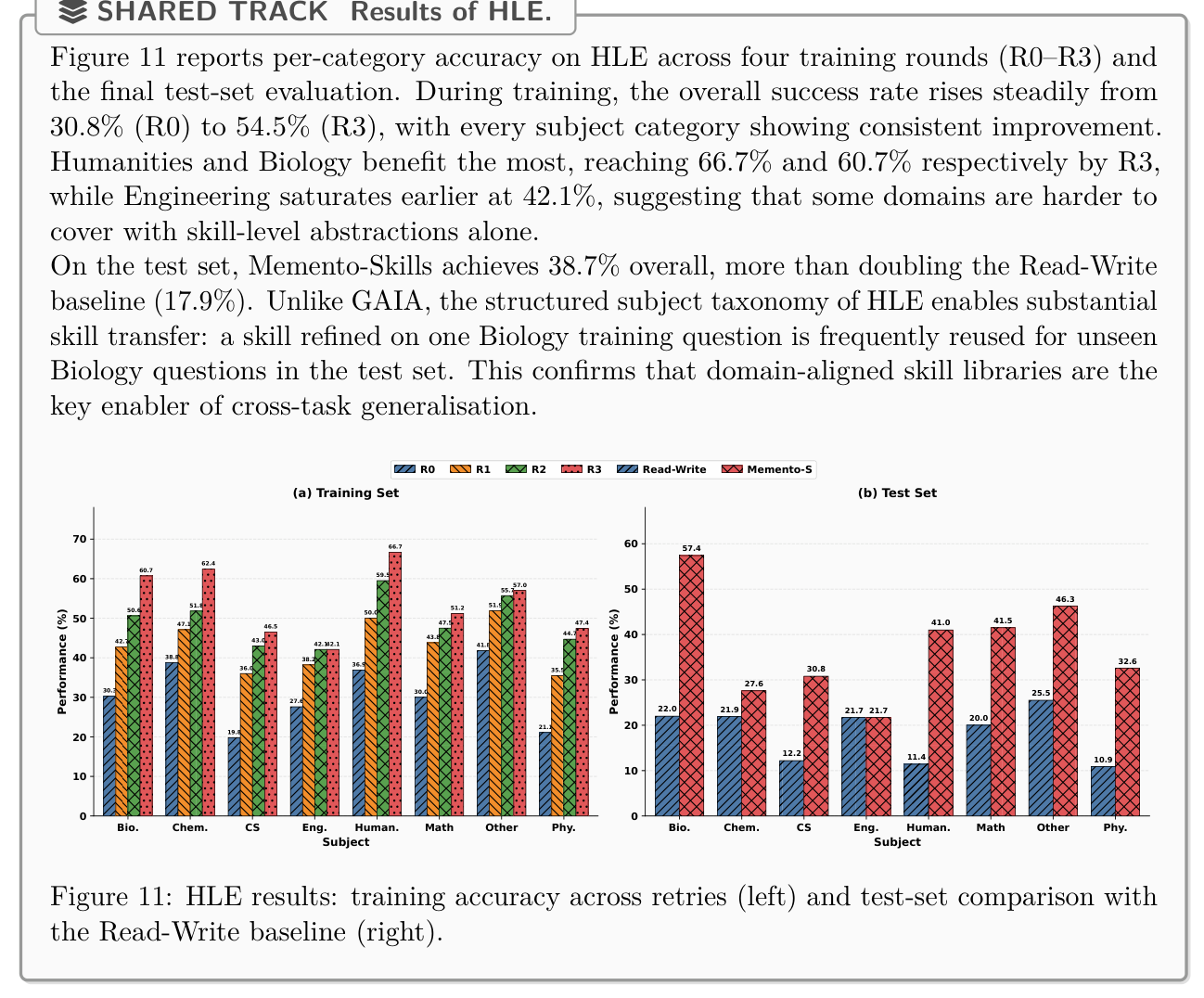
이는 structured subject taxonomy 가 cross-task transfer 에 중요한 역할을 함을 보여주며, domain-aligned skill libraries 가 cross-task generalization 의 핵심임을 입증합니다. skill memory 는 GAIA 학습 후 41 skills 로, HLE 학습 후 235 skills 로 확장되었으며 [Figure 1], t-SNE projection 결과는 학습된 skill 들이 semantically coherent clusters 를 형성하며 embedding space 를 밀도 높게 커버함을 보여주었습니다 [Figure 12].
4. Conclusion & Impact
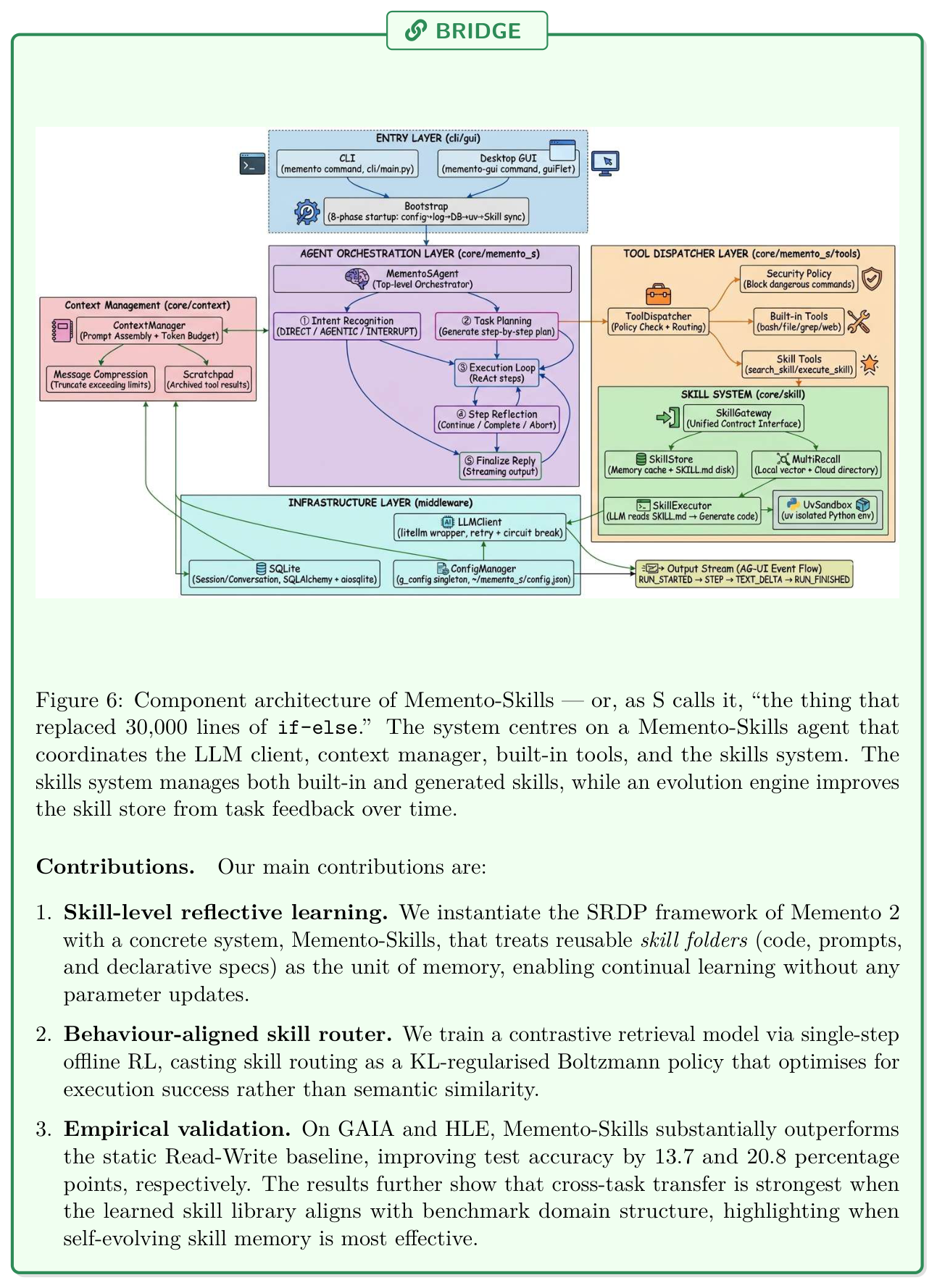
Memento-Skills는 memory-based learning 과 skill-based learning 을 결합하여 LLM Agent 가 autonomous 하게 skill 을 설계하고 개선할 수 있는 혁신적인 시스템을 제안합니다. 이 연구는 executable skill 을 external memory 의 단위로 취급함으로써, Stateful Reflective Decision Process 의 이론적 보장을 구체적인 deployable artefact 로 전환했습니다. Read-Write Reflective Learning 루프를 통해 LLM parameter 를 업데이트하지 않고도 continual learning 을 달성하며, behavior-aligned contrastive router 는 surface-level similarity 대신 execution success 에 최적화된 skill retrieval 을 보장합니다. GAIA 와 HLE 벤치마크에서의 실험 결과는 skill-as-memory 접근 방식이 정적인 static-library ablation 보다 월등한 성능을 보이며, structured domain categories 에 따라 cross-task transfer 가 가장 강력하게 일어남을 확인시켜주었습니다. 궁극적으로 Memento-Skills는 continual learning 이 model weights 에만 국한되지 않고, 지속적으로 성장하고 스스로 개선하는 skill library 가 frozen LLM 의 역량을 확장하는 persistent, non-parametric intelligence layer 로 기능할 수 있다는 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] UI-MOPD: Multi-Platform On-Policy Distillation for Continual GUI Agent Learning
- [논문리뷰] QVal: Cheaply Evaluating Dense Supervision Signals for Long-Horizon LLM Agents
- [논문리뷰] Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
- [논문리뷰] Meta-Cognitive Memory Policy Optimization for Long-Horizon LLM Agents
- [논문리뷰] MemTrain: Self-Supervised Context Memory Training
Review 의 다른글
- 이전글 [논문리뷰] Matryoshka Gaussian Splatting
- 현재글 : [논문리뷰] Memento-Skills: Let Agents Design Agents
- 다음글 [논문리뷰] MonoArt: Progressive Structural Reasoning for Monocular Articulated 3D Reconstruction
댓글