[논문리뷰] Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xiyang Wu, Zongxia Li, Guangyao Shi, Alexander Duffy, Tyler Marques, Matthew Lyle Olson, Tianyi Zhou, Dinesh Manocha, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- COS-PLAY: LLM 기반 Decision Agent와 Agentic Skill Bank Agent가 상호작용하며 학습하는 Co-Evolution 프레임워크입니다.
- Skill Bank: 에이전트가 환경과의 상호작용을 통해 발견한 재사용 가능한 행동 프로토콜(Summary, Pre-condition, Plan, Contract, Success/Abort Criteria)을 저장하는 구조화된 라이브러리입니다.
- GRPO (Group Relative Policy Optimization): 본 논문에서 Decision Agent와 Skill Bank Agent를 최적화하기 위해 사용하는 알고리즘으로, 정책의 안정적인 개선을 돕습니다.
- Contract Learning: 기술(Skill)이 실행될 때 발생하는 상태 변화(state change)를 학습하여, 해당 기술의 유효성과 적용 가능성을 검증하는 과정입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 LLM 기반 에이전트가 복잡하고 긴 호라이즌(Long-Horizon)을 가진 환경에서 일관된 의사결정을 수행하지 못하는 문제를 해결하고자 합니다. 기존 LLM 에이전트는 경험을 체계적으로 발견, 보유, 재사용할 수 있는 메커니즘이 부족하여 새로운 작업마다 매번 처음부터 다시 추론해야 하는 한계가 있습니다. 특히, 복잡한 게임 환경에서는 지연된 보상(delayed rewards)과 부분적 관측 가능성(partial observability)으로 인해 성능이 저하되는 경향이 있습니다. 따라서 저자들은 의사결정 에이전트와 기술 라이브러리(Skill Bank)가 서로를 보완하며 진화하는 Co-Evolution 접근 방식을 제안합니다. 이는 [Figure 1]에 묘사된 바와 같이, 환경과의 상호작용을 통해 지속적으로 개선되는 폐쇄형 루프를 형성합니다.
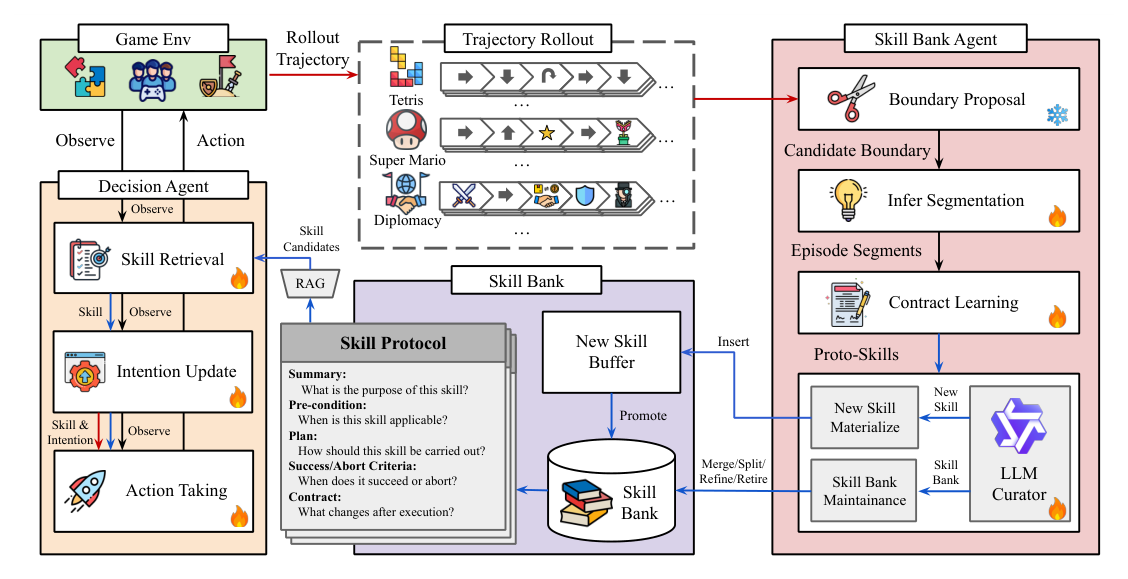
Figure 1 — COS-PLAY 프레임워크의 전체적인 Co-Evolution 아키텍처를 보여주는 핵심 다이어그램입니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 LLM 기반의 Decision Agent가 Skill Bank로부터 적절한 기술을 인출(Retrieval)하고 실행하며, Skill Bank Agent는 비지도 방식으로 궤적(trajectory)을 분할하여 새로운 기술을 발견하고 기존 기술을 정제하는 COS-PLAY 프레임워크를 제안합니다. 이 과정에서 기술의 효율적인 학습을 위해 LoRA 어댑터를 사용하며, GRPO 알고리즘을 통해 에이전트의 행동 선택과 기술 생성 능력을 동시 최적화합니다. 실험 결과, COS-PLAY는 8B 파라미터의 QWEN3-8B 모델을 사용함에도 불구하고, 6개의 게임 환경에서 기존 프런티어 모델들 대비 월등한 성능을 보였습니다. 정량적으로는 싱글 플레이 게임에서 GPT-5.4 베이스라인 대비 평균 25.1%의 보상 향상을 달성했습니다. 또한, [Table 1]에 나타난 바와 같이, 다중 플레이어 환경인 Diplomacy에서도 GEMINI-3.1-PRO 대비 8.8% 높은 성능을 기록하며 뛰어난 전략적 reasoning 능력을 입증했습니다.
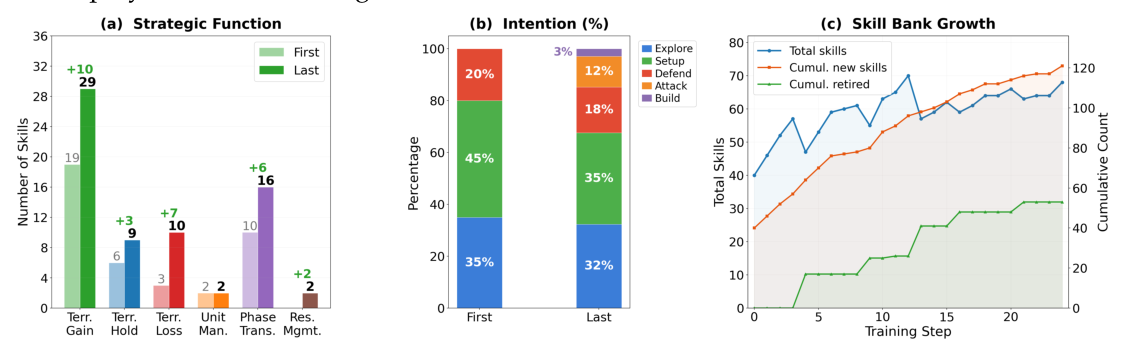
Table 1 — COS-PLAY가 다양한 환경에서 기존 LLM 베이스라인 모델들과 비교하여 얼마나 성능적 우위를 점하는지 보여주는 핵심 결과 테이블입니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 LLM 에이전트의 장기적인 의사결정 능력을 향상하기 위해 의사결정 정책과 기술 라이브러리가 함께 진화하는 체계적인 Co-Evolution 루프를 제시합니다. 제안된 프레임워크는 명시적인 인적 지도 없이도 환경으로부터 구조화된 기술을 스스로 추출하고 정제함으로써, 데이터 효율적인 학습과 높은 수준의 재사용성을 구현했습니다. 이는 향후 복잡한 상호작용이 요구되는 도메인에서 에이전트의 자율적 개선과 일반화 가능성을 크게 확장할 수 있는 토대를 마련했습니다. 특히, 소규모 모델로도 거대 모델과 경쟁 가능한 성능을 확보함으로써, 효율적인 에이전트 설계 방향성을 제시했다는 점에서 학계 및 산업계에 큰 시사점을 줍니다.
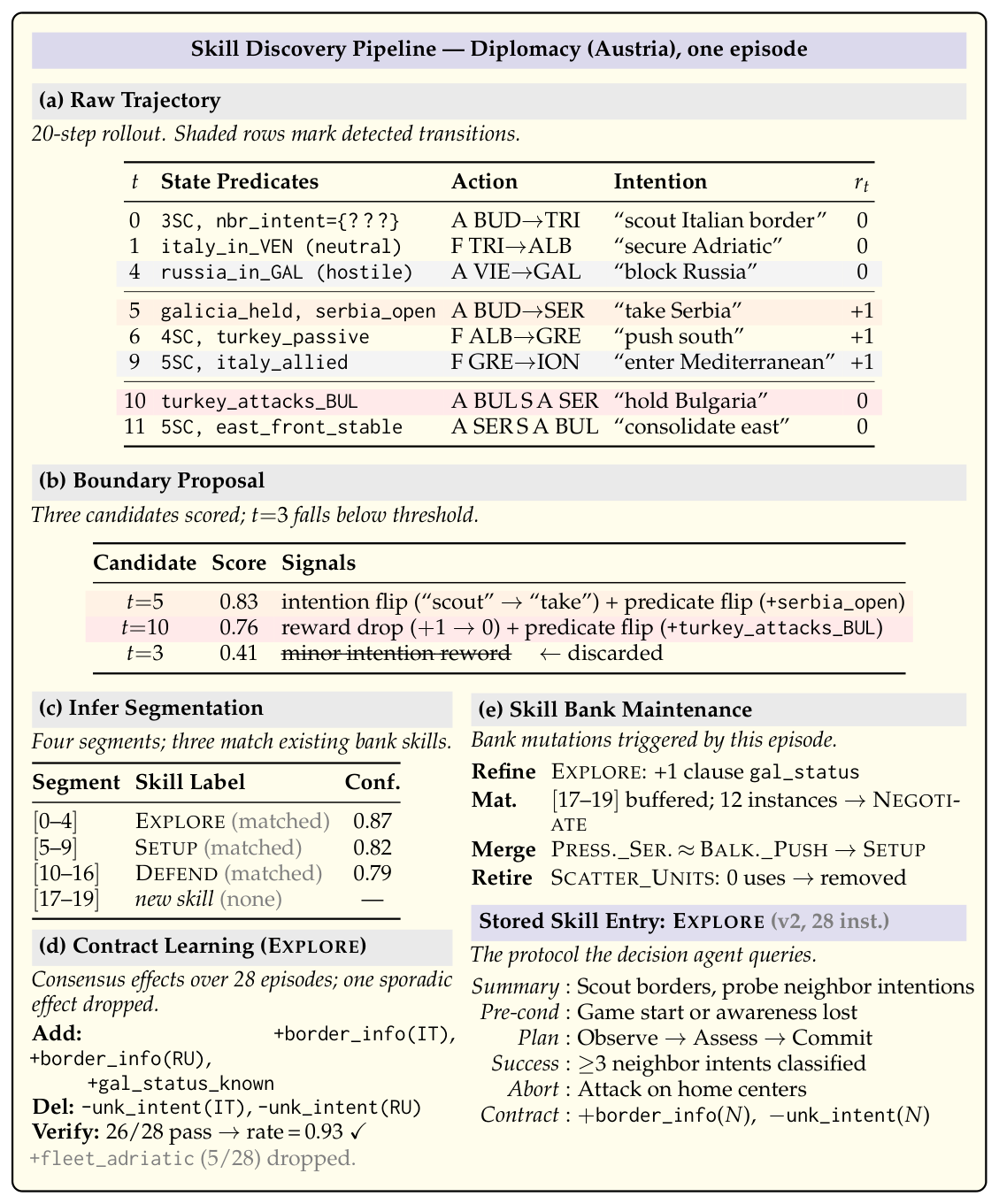
Figure 2 — Skill Bank Agent가 어떻게 궤적을 세그먼트화하고 기술을 관리하는지 구체적인 프로세스를 설명합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Hindsight Credit Assignment for Long-Horizon LLM Agents
- [논문리뷰] Memex(RL): Scaling Long-Horizon LLM Agents via Indexed Experience Memory
- [논문리뷰] SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
- [논문리뷰] Spark: Strategic Policy-Aware Exploration via Dynamic Branching for Long-Horizon Agentic Learning
- [논문리뷰] A Goal Without a Plan Is Just a Wish: Efficient and Effective Global Planner Training for Long-Horizon Agent Tasks
Review 의 다른글
- 이전글 [논문리뷰] WavAlign: Enhancing Intelligence and Expressiveness in Spoken Dialogue Models via Adaptive Hybrid Post-Training
- 현재글 : [논문리뷰] Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
- 다음글 [논문리뷰] Context Unrolling in Omni Models
댓글