[논문리뷰] XSkill: Continual Learning from Experience and Skills in Multimodal Agents
링크: 논문 PDF로 바로 열기
저자: Guanyu Jiang, Zhaochen Su, Xiaoye Qu, Yi R. (May) Fung
1. Key Terms & Definitions (핵심 용어 및 정의)
- Multimodal Large Language Models (MLLMs) : 시각적 인지, 코드 실행, 정보 검색 등 다양한 툴을 활용하여 복잡한 추론 작업을 수행하는 대규모 언어 모델 기반 에이전트.
- Experience : 툴 선택 및 의사 결정에 대한 간결한 action-level guidance를 제공하며, 특정 실행 context 및 실패 패턴에 대한 통찰력을 포착하는 비매개변수 전술적 프롬프트.
- Skill : 계획 및 툴 orchestration을 위한 구조화된 task-level guidance를 제공하며, 특정 문제 클래스에 대한 재사용 가능한 workflow와 툴 템플릿을 포함하는 문서.
- Dual-Stream Framework : XSKILL 의 핵심으로, experience와 skill이라는 두 가지 상호 보완적인 지식 스트림을 활용하여 continual learning을 수행하는 아키텍처.
- Visually-Grounded Summarization : 텍스트 trajectory log에만 의존하지 않고 시각적 관찰을 기반으로 지식을 추출하고 요약하는 프로세스.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Multimodal 에이전트는 복잡한 시각적 추론 task와 다양한 툴을 처리할 수 있게 되었지만, 여전히 비효율적인 툴 사용과 open-ended 환경에서의 유연하지 않은 orchestration이라는 두 가지 근본적인 병목 현상에 직면해 있습니다. 기존 에이전트들은 종종 간단한 문제에 과도한 단계를 소비하고 복잡한 쿼리에는 충분히 깊은 multi-turn 탐색을 수행하지 못하며, 이는 구조화된 skill로 해결할 수 있는 문제입니다. 또한 대부분의 시스템은 단일 경로 실행에 국한되어 task 전반에 걸쳐 일반화되는 방식으로 툴을 구성하는 능력이 제한적입니다. 이는 context-sensitive experience를 통해 적응형 툴 선택을 위한 전술적 지식을 포착함으로써 극복할 수 있습니다.
이러한 한계점들을 극복하기 위해, 본 연구는 Multimodal 에이전트가 과거 trajectory로부터 training-free learning 을 통해 툴 사용 효율성과 툴 composition 유연성을 지속적으로 향상시킬 수 있는 방법을 모색합니다. 기존 접근 방식들은 주로 텍스트 기반 trajectory log에 의존하지만, 이는 시각적 관찰에 의존하는 Multimodal 환경에서 결정 신호를 grounding하기에 부적절합니다. [Figure 1]은 기존 에이전트가 시각-의미론적 간극으로 인해 이미지 문제를 해결하지 못하는 반면, XSKILL 이 경험과 skill을 통해 성공적으로 문제를 해결하는 모습을 보여줍니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Multimodal 에이전트의 experience 및 skill로부터의 continual learning을 위한 dual-stream framework 인 XSKILL 을 제안합니다. `
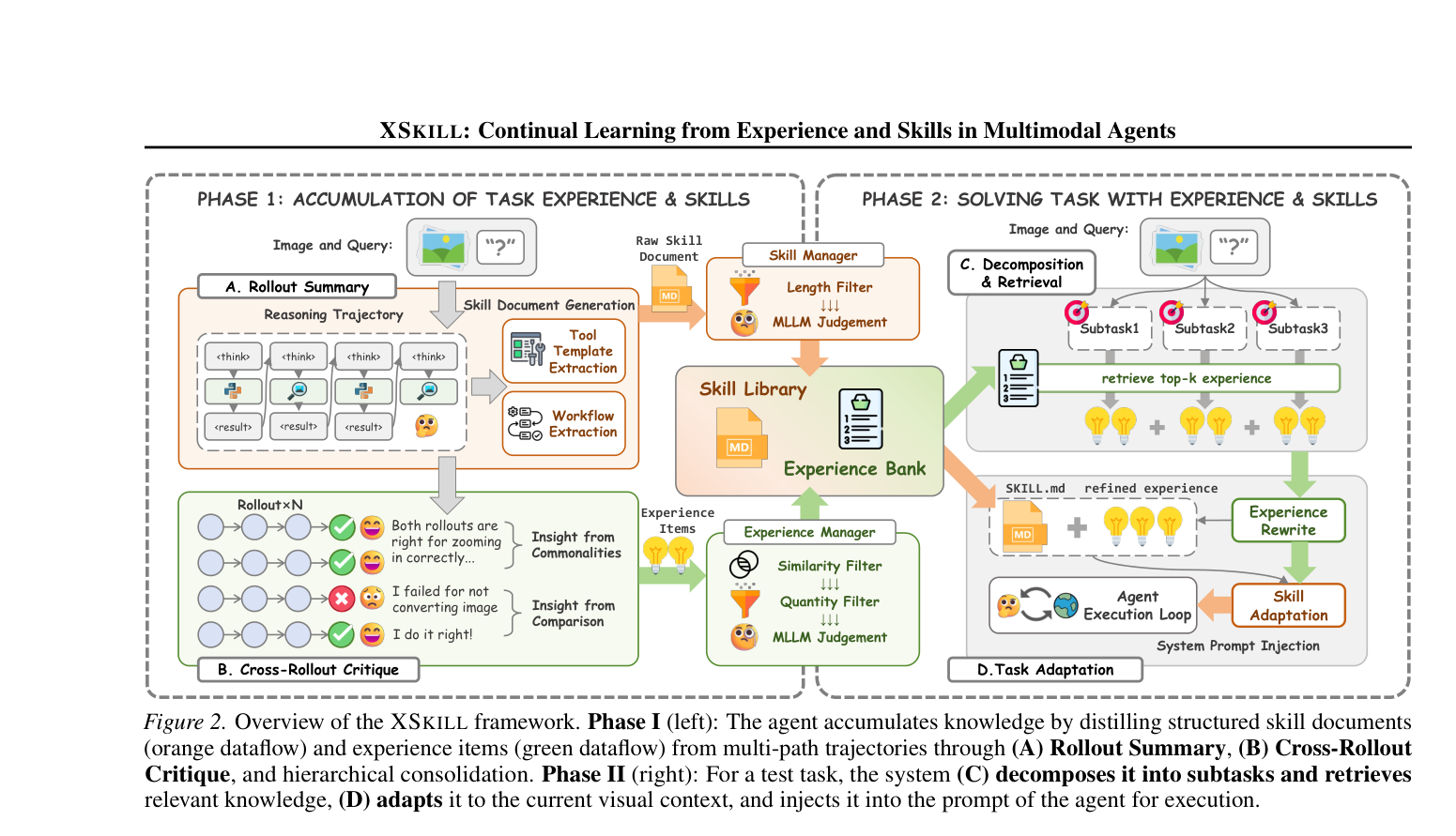 Figure 2: Overview of the XSKILL framework. Phase I (left): The agent accumulates knowledge by distilling structured skill documents (orange dataflow) and experience items (green dataflow) from multi-path trajectories through (A) Rollout Summary, (B) Cross-Rollout Critique, and hierarchical consolidation. Phase II (right): For a test task, the system (C) decomposes it into subtasks and retrieves relevant knowledge, (D) adapts it to the current visual context, and injects it into the prompt of the agent for execution.
Figure 2: Overview of the XSKILL framework. Phase I (left): The agent accumulates knowledge by distilling structured skill documents (orange dataflow) and experience items (green dataflow) from multi-path trajectories through (A) Rollout Summary, (B) Cross-Rollout Critique, and hierarchical consolidation. Phase II (right): For a test task, the system (C) decomposes it into subtasks and retrieves relevant knowledge, (D) adapts it to the current visual context, and injects it into the prompt of the agent for execution.
`에 제시된 XSKILL 은 structured skill document인 Skill Library K 와 JSON 기반 Experience Bank E 라는 두 가지 상호 보완적인 지식 형태를 유지합니다. XSKILL 의 아키텍처는 두 단계로 구성됩니다. Phase I (accumulation) 에서는 training dataset Dtrain 으로부터 multi-path rollout을 수행하고, 시각적으로 grounding된 summarization 및 cross-rollout critique를 통해 skill과 experience를 추출합니다. Phase II (inference) 에서는 테스트 task Ttest 에 대해 시스템이 쿼리를 subtask로 분해하고, semantic similarity를 통해 관련 지식을 검색하며, image-aware rewriting을 통해 현재 시각적 context에 맞게 지식을 adapt한 후 시스템 프롬프트에 주입합니다. 이 과정은 continual learning loop를 형성하여 지식 베이스를 지속적으로 개선합니다.
XSKILL 은 시각적 에이전틱 툴 사용, Multimodal search, 포괄적인 Multimodal reasoning을 포괄하는 다양한 벤치마크에서 평가되었으며, 4개의 backbone 모델( Gemini-2.5-Pro , Gemini-3-Flash , GPT-5-mini , o4-mini ) 전반에 걸쳐 강력한 성능 향상을 보였습니다. `
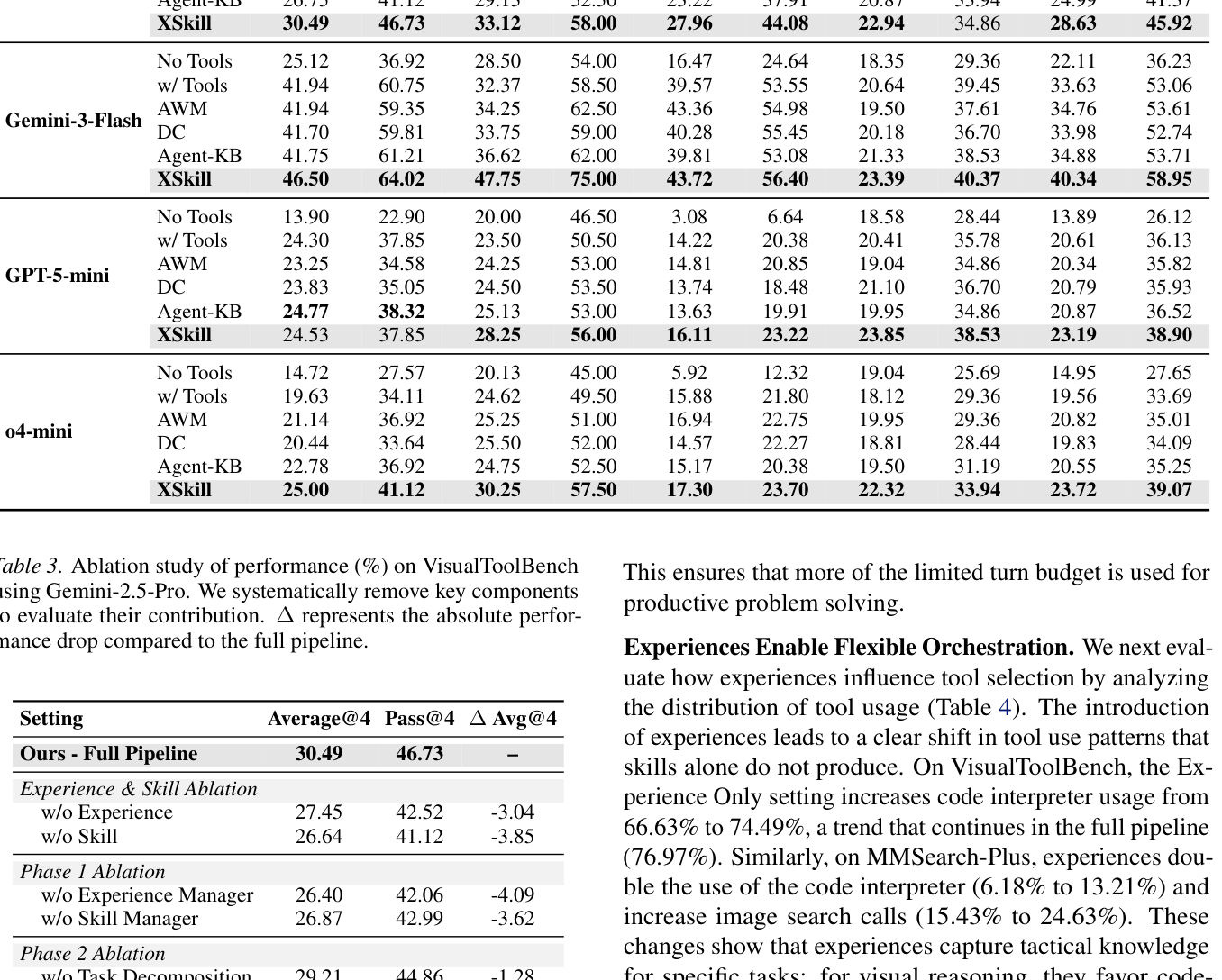 Table 2: Main results of performance comparison (%) between XSKILL and baselines. We report the Average@4 and Pass@4 over 4 independent rollouts. Bold indicates the best performance.
Table 2: Main results of performance comparison (%) between XSKILL and baselines. We report the Average@4 and Pass@4 over 4 independent rollouts. Bold indicates the best performance.
`에 따르면, XSKILL 은 tool-only baseline 대비 Average@4 에서 평균 2.58~6.71 점의 상당한 성능 향상을 달성했습니다. 특히, Gemini-3-Flash 기반 TIR-Bench 에서는 47.75% Average@4 를 기록하여 가장 강력한 baseline인 Agent-KB 보다 11.13 점 높은 점수를 보였습니다. 이는 dual-stream 설계가 task 해결에 도움이 되는 지식을 효과적으로 포착함을 입증합니다.
`
 Table 3: Ablation study of performance (%) on VisualToolBench using Gemini-2.5-Pro. We systematically remove key components to evaluate their contribution. Δ represents the absolute performance drop compared to the full pipeline.
Table 3: Ablation study of performance (%) on VisualToolBench using Gemini-2.5-Pro. We systematically remove key components to evaluate their contribution. Δ represents the absolute performance drop compared to the full pipeline.
의 ablation study 결과, experience 또는 skill 중 어느 하나라도 제거하면 성능이 각각 **3.04** 점 및 **3.85** 점 하락하여, 두 지식 스트림이 모두 필수적임을 확인했습니다. Skill은 구조적 오류를 크게 줄여 툴 사용 효율성을 높이는 반면, experience는 코드 interpreter 사용 빈도를 증가시키고 이미지 검색 호출을 늘리는 등 툴 선택을 더 targeted strategy로 유도하여 유연한 orchestration을 가능하게 합니다. [Table 4]`는 experience 도입 시 code interpreter 사용이 VisualToolBench 에서 66.63% 에서 74.49% 로 증가하고 MMSearch-Plus 에서 6.18% 에서 13.21% 로 증가했음을 보여줍니다. Cross-task transferability 실험에서도 XSKILL 은 모든 baseline을 일관되게 능가하며, 평균 2~3 점의 개선을 보여 strong zero-shot cross-task transfer 능력을 입증했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Multimodal 에이전트의 지식 활용 메커니즘 부족이라는 근본적인 한계점을 해결합니다. XSKILL 은 시각적으로 grounding된 추출 및 계층적 통합을 통해 task-level skill과 action-level experience를 통합하는 프레임워크를 제공합니다. 이를 통해 축적된 지식과 task별 요구사항 간의 간극을 줄이고, 동적인 retrieval 및 adaptation이 가능하게 됩니다. XSKILL 의 empirical validation은 다양한 벤치마크에서 일관된 성능 향상을 보여주며, skill은 툴 실행의 robustness를 보장하고 experience는 task-specific context를 기반으로 전략적 선택을 안내하는 등 두 지식 스트림이 상호 보완적인 역할을 함을 시사합니다.
XSKILL 은 매개변수 재훈련 없이 Multimodal 에이전트가 지식을 축적하고 활용할 수 있도록 하여, 실제 환경에서 자율 시스템을 발전시키는 실용적이고 확장 가능한 경로를 제공합니다. 외부화된 지식 구조는 에이전트 의사 결정의 투명성과 해석 가능성을 높이며, 인간 운영자가 축적된 지식의 특정 부분을 audit, edit, remove할 수 있도록 합니다. 그러나 더욱 강력한 에이전트는 민감한 시각적 데이터를 포함한 악의적인 자동화에 오용될 수 있거나, 이전 trajectory에 존재하는 편향을 상속 및 증폭시킬 수 있다는 점은 주의해야 합니다. 이러한 우려를 완화하기 위해 저자들은 축적된 지식 베이스에 대한 인간 감독, skill 문서 및 experience bank에 대한 주기적인 bias auditing, 그리고 cross-model 지식 전송을 관리하는 접근 제어 정책을 권장합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] AgentVista: Evaluating Multimodal Agents in Ultra-Challenging Realistic Visual Scenarios
- [논문리뷰] Rethinking Continual Experience Internalization for Self-Evolving LLM Agents
- [논문리뷰] Memento-Skills: Let Agents Design Agents
- [논문리뷰] AdaReasoner: Dynamic Tool Orchestration for Iterative Visual Reasoning
- [논문리뷰] Distilling Feedback into Memory-as-a-Tool
Review 의 다른글
- 이전글 [논문리뷰] WeEdit: A Dataset, Benchmark and Glyph-Guided Framework for Text-centric Image Editing
- 현재글 : [논문리뷰] XSkill: Continual Learning from Experience and Skills in Multimodal Agents
- 다음글 [논문리뷰] Can Vision-Language Models Solve the Shell Game?
댓글