[논문리뷰] Can Vision-Language Models Solve the Shell Game?
링크: 논문 PDF로 바로 열기
저자: Tiedong Liu, Wee Sun Lee
1. Key Terms & Definitions (핵심 용어 및 정의)
- Visual Entity Tracking : 비디오 프레임 전체에 걸쳐 특정 시각적 개체(object)의 정체성을 유지하며 움직임을 추적하는 능력.
- VET-Bench : 시각적 Shortcut을 제거하고 움직임의 연속성을 통한 Spatiotemporal perception에 전적으로 의존하도록 설계된 합성(synthetic) 진단 Testbed.
- NC¹-complete : 특정 계산 문제를 풀기 위해 필요한 최소 Circuit Depth를 나타내는 계산 복잡도 클래스. 이 논문에서는 고정 Depth Transformer 기반 모델의 표현력 한계를 의미한다.
- Spatiotemporal Grounded Chain-of-Thought (SGCoT) : VLM이 개체의 Trajectory를 명시적인 중간 상태(intermediate states)로 생성하여 Spatiotemporal reasoning을 수행하는 제안된 방법론.
- Shell Game : 시각적으로 동일한 여러 용기 중 하나에 숨겨진 개체의 위치가 섞인 후 최종 위치를 추적하는 작업.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Vision-Language Models (VLMs)는 전반적인 비디오 이해 및 추론에서 뛰어난 성능을 보였지만, 시간 경과에 따른 개체 추적(Visual Entity Tracking)과 같은 저수준 인식 능력에서는 중요한 병목 현상을 겪고 있습니다. 기존 비디오 벤치마크, 예를 들어 Perception Test의 cups-game 하위 집합은 시각적 Shortcut(예: 구별 가능한 컵, 투명한 컵)을 포함하여 모델이 실제 시공간 추적 대신 정적 프레임 수준 Feature에 의존하게 만들었습니다. 이러한 Shortcut을 제거하고 순수한 추적 작업으로 제한했을 때, Gemini-3-Pro 와 같은 최신 VLM의 성능은 80% 에서 36.45% 로 급격히 하락하며, 심지어 30.77% 로 무작위 추측 수준(random guessing)까지 떨어집니다. 이는 현재 VLM이 시간 경과에 따른 일관된 개체 표현을 유지하는 데 실패하고, 시각적 Feature에 과도하게 의존하는 근본적인 한계를 가지고 있음을 시사합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 Visual Entity Tracking의 한계를 체계적으로 분석하기 위해 시각적으로 동일한 개체를 사용하여 모델이 오직 움직임 연속성을 통해서만 개체를 추적하도록 강제하는 합성 진단 Testbed인 VET-Bench 를 도입했습니다
 Figure 1: Overview of VET-Bench.
Figure 1: Overview of VET-Bench.
. 실험 결과는 Gemini-3-Pro 를 포함한 모든 최신 VLM이 VET-Bench 에서 무작위 추측 수준(거의 33% 미만)에 가깝게 성능을 보였음을 드러냈습니다
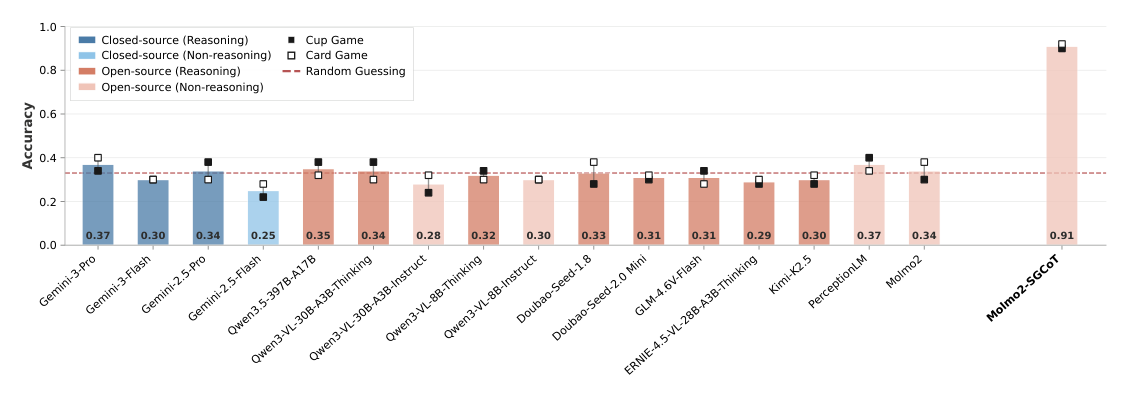 Figure 2: Performance on VET-Bench, consisting of 50 cups-game and 50 cards-game videos featuring 3 objects and 5 swaps (~12 seconds). Existing VLMs all perform near random chance. Molmo2-SGCoT is a fine-tuned model based on Molmo2 that leverages Spatiotemporal Grounded Chain-of-Thought (SGCoT) to solve the shell game (Section 5).
Figure 2: Performance on VET-Bench, consisting of 50 cups-game and 50 cards-game videos featuring 3 objects and 5 swaps (~12 seconds). Existing VLMs all perform near random chance. Molmo2-SGCoT is a fine-tuned model based on Molmo2 that leverages Spatiotemporal Grounded Chain-of-Thought (SGCoT) to solve the shell game (Section 5).
. 이는 모델이 진정한 개체 추적 대신 정적 Appearance Feature에 크게 의존하고 있음을 나타냅니다.
이론적 분석을 통해 k ≥ 5 개의 시각적으로 구별 불가능한 개체를 추적하는 Visual Entity Tracking (TRACKk) 문제가 NC¹-complete 임을 증명했습니다. 이는 고정 Depth Transformer 기반 VLM이 표현력 제약으로 인해 중간 계산(intermediate computation) 없이 이러한 문제를 해결하는 데 근본적으로 한계가 있음을 의미합니다. 또한, 직접 정답(direct-answer) 방식의 학습만으로는 VLM이 Shell Game을 학습하는 데 실패함을 경험적으로 확인했습니다 [Figure 4].
이러한 한계를 극복하기 위해 본 연구는 Spatiotemporal Grounded Chain-of-Thought (SGCoT) 를 제안했습니다. 이는 Molmo2 의 Object Tracking 능력을 활용하여 개체 Trajectory를 명시적인 중간 상태로 생성하는 접근 방식입니다. 합성 텍스트 전용 데이터로 Molmo2 를 Fine-tuning하여 SGCoT Reasoning을 유도한 결과, VET-Bench 에서 90% 를 초과하는 State-of-the-Art 정확도를 달성했습니다 [Figure 2]. 이는 VLM이 외부 도구 없이도 비디오 Shell Game 작업을 End-to-End로 안정적으로 해결할 수 있음을 보여줍니다. Swap 및 Object Count 변화에 따른 성능 분석 또한 기존 VLM이 진정한 Entity Tracking을 수행하지 못함을 뒷받침합니다
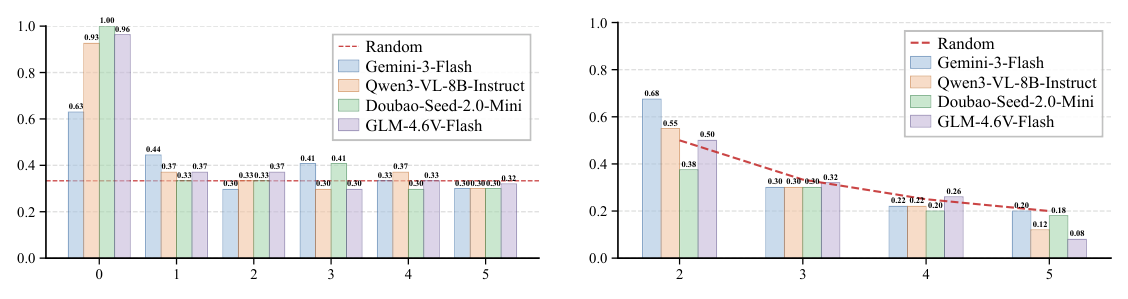 Figure 3: Performance of VLMs under different swap and object counts.
Figure 3: Performance of VLMs under different swap and object counts.
.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Visual Entity Tracking이 현재 VLM의 핵심 병목 지점임을 명확히 확인했습니다. 시각적 Shortcut이 제거된 VET-Bench 벤치마크를 통해 최신 VLM들이 사실상 무작위 추측 수준의 성능을 보임을 입증했습니다. 이론적으로 k ≥ 5 개체의 Visual Entity Tracking이 NC¹-complete 라는 점을 밝힘으로써, 고정 Depth Transformer 기반 VLM이 CoT(Chain-of-Thought)와 같은 중간 계산 없이는 이러한 작업을 해결하는 데 내재적인 한계가 있음을 제시했습니다.
제안된 Spatiotemporal Grounded Chain-of-Thought (SGCoT) 방법론은 Molmo2 의 Tracking 능력을 활용하여 명시적인 Spatiotemporal Trajectory를 생성함으로써 이 문제를 성공적으로 해결했습니다. SGCoT 는 VET-Bench 에서 90% 이상의 높은 정확도를 달성하며, VLM이 Shell Game과 같은 복잡한 추적 작업을 End-to-End로 수행할 수 있음을 입증했습니다. 이 연구는 미래 VLM이 더 광범위한 비디오 인식 및 추론에서 SGCoT 를 활용하여 진정한 인간 수준의 시각적 인식을 달성할 수 있는 길을 열어줄 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
- [논문리뷰] HomeSafe-Bench: Evaluating Vision-Language Models on Unsafe Action Detection for Embodied Agents in Household Scenarios
- [논문리뷰] Holi-Spatial: Evolving Video Streams into Holistic 3D Spatial Intelligence
- [논문리뷰] AI Gamestore: Scalable, Open-Ended Evaluation of Machine General Intelligence with Human Games
- [논문리뷰] NarraScore: Bridging Visual Narrative and Musical Dynamics via Hierarchical Affective Control
Review 의 다른글
- 이전글 [논문리뷰] XSkill: Continual Learning from Experience and Skills in Multimodal Agents
- 현재글 : [논문리뷰] Can Vision-Language Models Solve the Shell Game?
- 다음글 [논문리뷰] Cheers: Decoupling Patch Details from Semantic Representations Enables Unified Multimodal Comprehension and Generation
댓글