[논문리뷰] Cheers: Decoupling Patch Details from Semantic Representations Enables Unified Multimodal Comprehension and Generation
링크: 논문 PDF로 바로 열기
Part 1: 요약 본문
저자: Yichen Zhang, Da Peng, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- UMMs (Unified Multimodal Models) : 시각적 이해(comprehension)와 이미지 생성(generation)을 단일 모델 프레임워크 내에서 통합하여 수행하는 모델을 지칭합니다.
- Cascaded Flow Matching Head : 이미지 생성 과정을 두 단계로 명시적으로 분리하는 CHEERS의 핵심 디코딩 컴포넌트입니다. 낮은 해상도에서 시각적 semantics를 먼저 합성한 후, vision tokenizer로부터 semantically gated detail residuals를 주입하여 고주파(high-frequency) 콘텐츠를 정교하게 생성합니다.
- High-Frequency Injection (HFI) : CHEERS의 cascaded flow matching head에서 세부 정보를 주입하는 메커니즘으로, semantically gated detail residuals를 활용하여 이미지의 질감(texture fidelity)과 구조적 선명도(structural sharpness)를 향상시킵니다.
- Pixel-Unshuffle : CHEERS의 unified vision tokenizer에서 semantic token의 공간 해상도를 줄이고 채널 차원을 투영하여 4배 의 token compression을 달성하는 모듈입니다.
- SigLIP2-ViT : VAE latents 위에 적용되어 고수준의 semantic visual features를 추출하는 CHEERS의 semantic encoder로, 특히 OCR-centric understanding 에서 미세한 시각적 디테일 보존에 중요한 역할을 합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 멀티모달 모델링 분야에서 시각적 이해와 생성을 단일 모델 내에서 통합하는 연구는 인간과 유사한 멀티모달 인텔리전스를 향한 중요한 진전으로 평가받습니다. 그러나 이러한 통합은 두 가지 근본적인 문제에 직면합니다. 첫째, 이해(comprehension)와 생성(generation) 작업이 서로 다른 디코딩 메커니즘(decoding regimes)과 시각적 표현(visual representations)을 요구하기 때문에 단일 Feature space 내에서 공동 최적화(jointly optimize)하기 어렵습니다. 기존의 이산형(discrete) 시각적 표현은 양자화 오류(quantization errors)와 차원 제약(dimensional constraints)으로 인해 시각적 정보 손실을 겪으며, 이는 특히 세밀한 디테일이 요구되는 작업에서 성능 저하로 이어집니다. 둘째, 시각적 이해는 의미론적으로 풍부한(semantic-rich) Feature를 필요로 하는 반면, 고품질 이미지 생성은 디테일을 보존하는 latents에 의존하여 단일 표현으로는 두 가지 요구 사항을 동시에 충족하기 어렵습니다. 이러한 한계는 기존 UMMs 아키텍처에서 시각적 Feature 모델링의 최적화 충돌을 야기했습니다
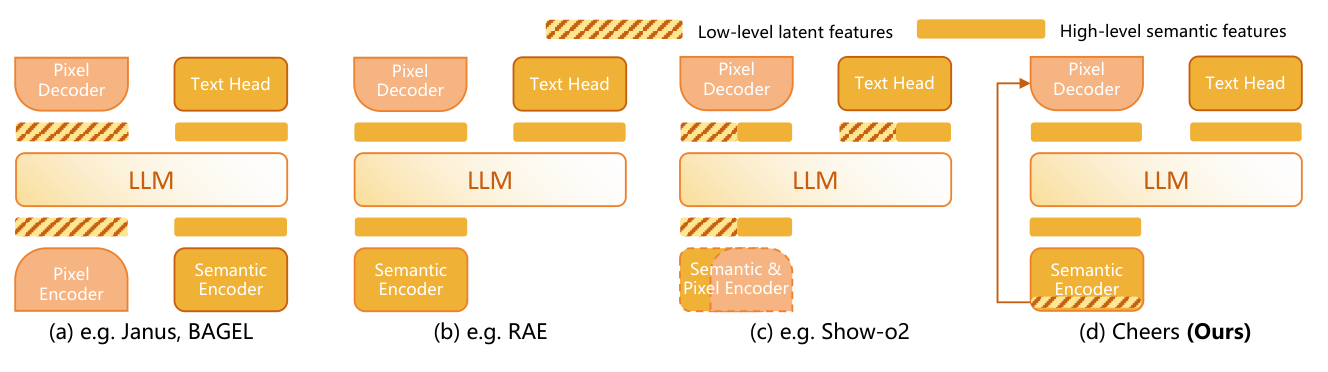 Figure 2: Architectural comparison between prior UMMs and CHEERS.
Figure 2: Architectural comparison between prior UMMs and CHEERS.
.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 문제를 해결하기 위해 CHEERS 를 제안합니다. CHEERS 는 패치 수준의 디테일(patch-level details)과 semantic representations를 분리하여 멀티모달 이해를 위한 semantics를 안정화하고, gated detail residuals 주입을 통해 이미지 생성의 Fidelity를 향상시킵니다. CHEERS 는 세 가지 핵심 컴포넌트로 구성됩니다: (i) Unified Vision Tokenizer 는 VAE decoder 와 SigLIP2-ViT semantic encoder를 활용하여 이미지 latent states를 semantic token으로 인코딩 및 압축하며, 효율적인 LLM conditioning을 위해 Pixel-Unshuffle 을 통해 4배 의 token compression을 달성합니다. 특히, VAE latents를 픽셀 공간으로 재구성한 후 SigLIP2-ViT 로 인코딩하는 방식은 OCR-centric understanding 능력을 크게 향상시켜 미세한 시각적 디테일을 보존합니다 [Table 6]. (ii) LLM-based Transformer ( Qwen2.5-1.5B-Instruct 백본)는 텍스트 생성에는 Autoregressive decoding을, 이미지 생성에는 Diffusion decoding을 통합합니다. (iii) Cascaded Flow Matching Head 는 이미지 생성을 두 단계로 분리합니다. 1단계에서는 LLM의 contextualized hidden states를 입력으로 받아 저해상도 semantic generation을 수행하고, PixelShuffle 로 Feature 맵을 업샘플링합니다. 2단계에서는 vision tokenizer에서 얻은 semantically gated high-frequency residuals를 Gating network를 통해 주입하여 고주파 콘텐츠를 정교화합니다.
실험 결과, CHEERS 는 시각적 이해 및 생성 모두에서 State-of-the-Art UMMs 와 동등하거나 능가하는 성능을 보였습니다. 특히, GenEval 및 MMBench 벤치마크에서 Tar-1.5B 모델을 능가하면서도 20% 의 훈련 비용만 필요로 하여 효과적이고 효율적인 멀티모달 모델링을 입증했습니다. 예를 들어, MMBench 에서 70.4점 을 기록한 Tar 대비 75.7점 을 달성했으며, GenEval 에서 Tar 의 0.76점 대비 0.78점 으로 더 높은 성능을 보였습니다
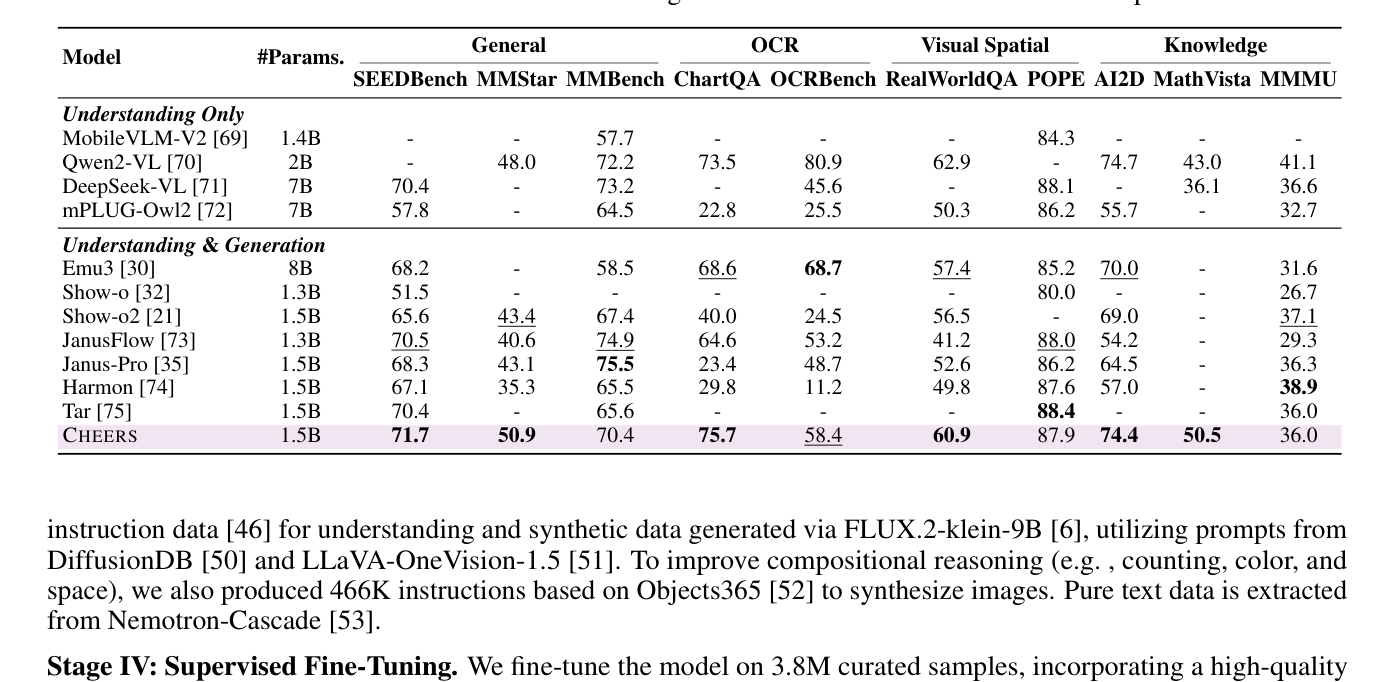 Table 2: Evaluation on multimodal understanding benchmarks. #Params.: LLM backbone parameters.
Table 2: Evaluation on multimodal understanding benchmarks. #Params.: LLM backbone parameters.
. Ablation 연구를 통해 High-Frequency Injection (HFI) 이 멀티모달 이해 성능에는 미미한 영향을 미치지만, 생성 품질을 상당히(substantial) 향상시킨다는 것이 검증되었습니다
 Table 5: Ablation results. The first row corresponds to a model fine-tuned using understanding data only. The second and third rows report jointly trained models optimized for both understanding and generation, without and with HFI, respectively.
Table 5: Ablation results. The first row corresponds to a model fine-tuned using understanding data only. The second and third rows report jointly trained models optimized for both understanding and generation, without and with HFI, respectively.
. 또한, 이해와 생성 작업을 공동으로 훈련하는 것이 멀티모달 이해 성능을 저해하지 않음을 확인했습니다.
4. Conclusion & Impact (결론 및 시사점)
CHEERS 는 패치 수준의 디테일과 semantic representations를 효과적으로 분리하여 시각적 이해와 고품질 이미지 생성을 단일 프레임워크 내에서 성공적으로 조화시킨 새로운 멀티모달 모델입니다. 이 접근 방식은 멀티모달 모델링에서 고질적인 최적화 충돌을 해결하고, 4배 의 token compression 을 통해 고해상도 이미지 이해 및 생성의 효율성을 높였습니다. 본 연구는 unified vision tokenizer와 cascaded flow matching head를 통해 견고한 이해력과 정확한 이미지 합성을 모두 보장합니다. CHEERS 는 83M 이라는 비교적 적은 데이터셋으로 훈련되었음에도 불구하고 경쟁력 있는 성능을 달성했으며, zero-shot 이미지 편집 능력과 같은 Emergent abilities 를 보여주어 해당 분야에 중요한 시사점을 제공합니다. 이러한 결과는 global semantic layout에서 localized detail refinement로 이어지는 계층적(hierarchical) 진행이 unified multimodal modeling에 효과적인 패러다임임을 검증합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Can Vision-Language Models Solve the Shell Game?
- 현재글 : [논문리뷰] Cheers: Decoupling Patch Details from Semantic Representations Enables Unified Multimodal Comprehension and Generation
- 다음글 [논문리뷰] CreativeBench: Benchmarking and Enhancing Machine Creativity via Self-Evolving Challenges
댓글