[논문리뷰] WeEdit: A Dataset, Benchmark and Glyph-Guided Framework for Text-centric Image Editing
링크: 논문 PDF로 바로 열기
저자: Hui Zhang, Juntao Liu, Zongkai Liu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Text-centric Image Editing : 이미지 내에 포함된 텍스트 요소를 수정, 번역, 재배치하는 작업으로, 전통적인 object- 및 style-centric manipulation과 구별되는 분야입니다.
- Glyph-Guided Supervised Fine-Tuning (SFT) : 타겟 텍스트의 approximate position 및 scale을 예측한 후, glyph layout을 explicit spatial prior로 렌더링하여 diffusion process를 condition하는 fine-tuning 접근 방식입니다.
- Multi-Objective Reinforcement Learning (RL) : instruction adherence, text readability, background preservation 등 human-centric quality goals에 맞춰 diffusion model의 generation을 최적화하는 학습 단계입니다.
- Instruction Adherence (IA) : 편집된 이미지가 사용자 지시사항을 얼마나 충실히 이행했는지를 측정하는 핵심 Metric입니다.
- Text Clarity (TC) : 렌더링된 텍스트의 legibility 및 typographic quality를 평가하는 Metric입니다.
- Background Preservation (BP) : 편집되지 않은 이미지 영역의 visual integrity를 정량화하는 Metric입니다.
- HTML-based Data Construction Pipeline : 웹 페이지 screenshot과 같은 structured data를 source image에서 HTML로 변환한 후, VLM을 이용해 텍스트 content를 추출 및 편집하고 headless browser로 source 및 target image를 pixel-perfect하게 렌더링하는 데이터 생성 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
저자들은 instruction-based image editing 분야에서 text-centric image editing 이 중요한 응용 잠재력에도 불구하고 아직 충분히 탐구되지 않은 영역임을 지적합니다. 현재 leading 모델들은 복잡한 텍스트 편집 지시를 정확하게 수행하는 데 어려움을 겪으며, 종종 blurry하거나 hallucinated characters를 생성하고, 특히 Arabic, Thai, Hindi와 같은 non-Latin scripts 처리 시 성능 저하를 겪는 한계가 있습니다. 이러한 실패의 주요 원인으로 text-centric editing 에 특화된 훈련 Paradigm, 대규모 데이터셋의 부족, 그리고 표준화된 Benchmark의 부재를 꼽습니다. 기존 데이터셋과 Benchmark는 주로 general-purpose editing scenarios에 맞춰져 있어 operation diversity, language coverage, evaluation granularity 측면에서 text-centric image editing 의 요구사항을 충족시키지 못하고 있습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 한계점을 해결하기 위해 WeEdit 라는 체계적인 solution을 제안합니다. 이 solution은 scalable data construction pipeline , 두 가지 Benchmark, 그리고 맞춤형 two-stage training strategy 를 포함합니다. 첫 번째 단계인 Glyph-Guided Supervised Fine-Tuning (SFT) 에서는 Qwen3-VL-235B-A22B-Instruct VLM을 활용하여 target text의 approximate position 및 scale을 예측하고 glyph layout을 explicit spatial prior로 렌더링하여 diffusion process를 condition함으로써 precise text placement와 character-level fidelity를 향상시킵니다
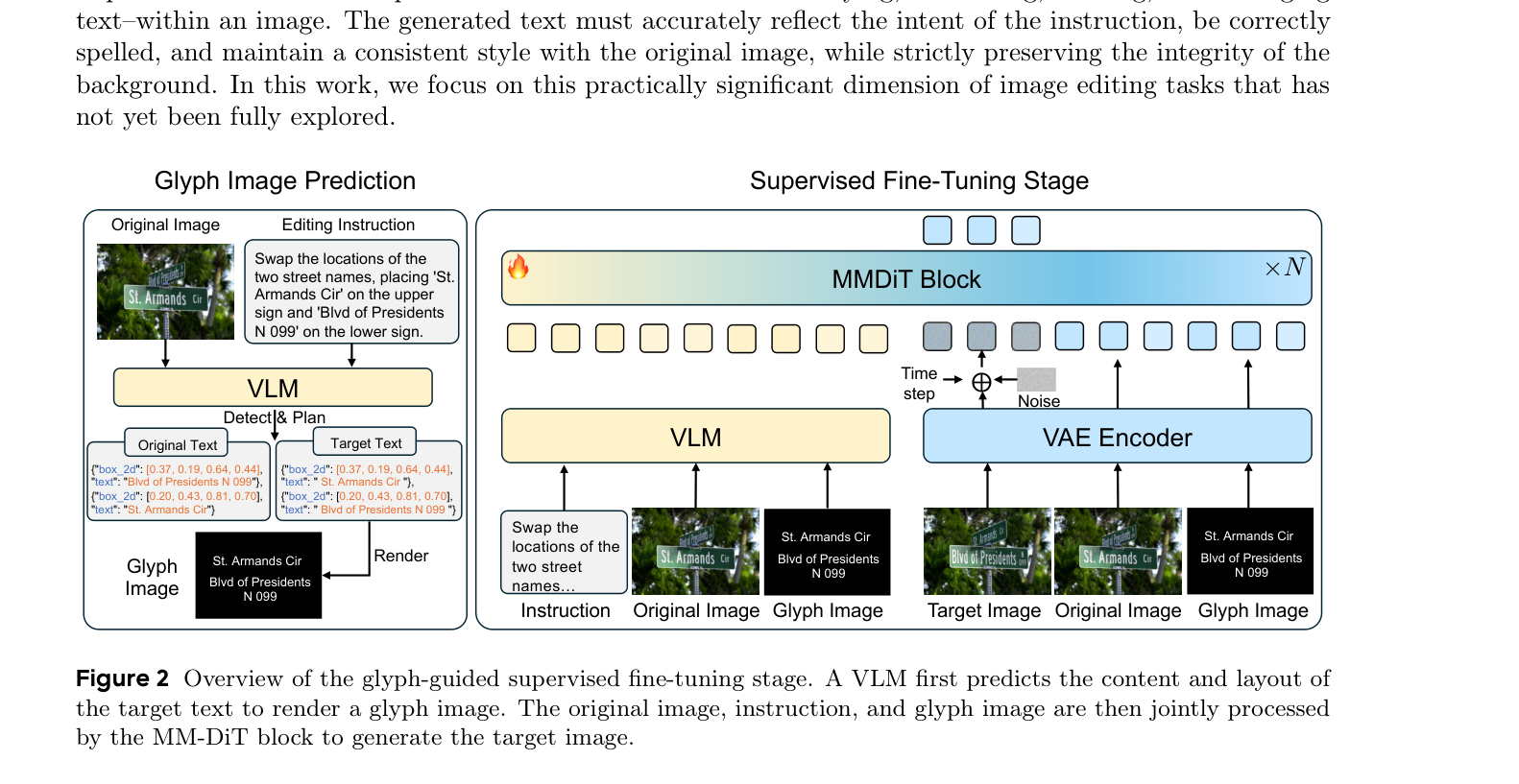 Figure 2: Overview of the glyph-guided supervised fine-tuning stage.
Figure 2: Overview of the glyph-guided supervised fine-tuning stage.
. 두 번째 단계인 Multi-Objective Reinforcement Learning (RL) 에서는 instruction adherence, text readability, background preservation 등 human-centric quality goals에 맞춰 generation을 최적화하기 위해 네 가지 reward model로 구성된 reward function이 사용됩니다
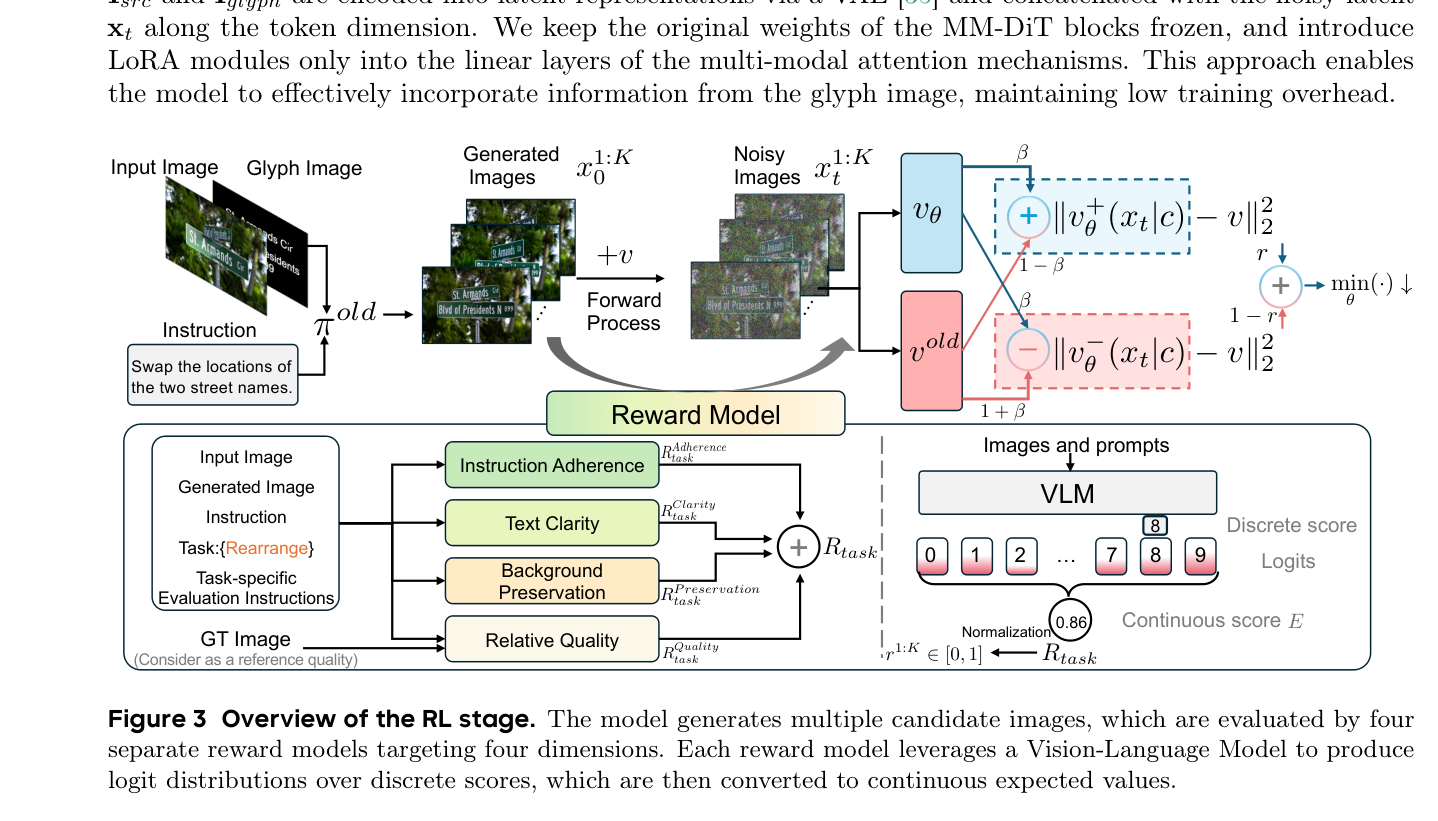 Figure 3: Overview of the RL stage.
Figure 3: Overview of the RL stage.
. 데이터 부족 문제를 해결하기 위해, novel HTML-based automatic editing pipeline 을 통해 diverse editing operations과 15개 언어 를 포함하는 330K 개의 training pairs를 생성했습니다.
WeEdit 는 광범위한 실험을 통해 기존 open-source 모델 및 대부분의 proprietary 모델들을 크게 상회하는 SOTA (State-Of-The-Art) 성능을 달성했습니다. Bilingual Benchmark에서 WeEdit-RL 은 overall IA 7.47 , TC 8.19 , BP 9.01 을 기록하며, 기존 best open-source 모델 대비 IA +3.98 , TC +2.35 , BP +2.21 이라는 상당한 개선을 보였습니다
 Table 1: Quantitative Results on the Bilingual Benchmark.
Table 1: Quantitative Results on the Bilingual Benchmark.
. Multilingual Benchmark에서도 WeEdit-RL 은 overall IA 6.70 , TC 7.10 , BP 8.49 를 달성하며, non-Latin scripts에서도 강건한 성능을 입증했습니다. Ablation study 결과, SFT 와 Glyph guidance 의 조합이 성능 향상에 결정적인 역할을 하며, RL 단계가 IA와 TC를 각각 6.99 에서 7.47 , 7.33 에서 8.19 로 끌어올리며 pixel-level supervision을 넘어선 높은 editing quality를 제공함을 확인했습니다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 text-centric image editing 분야의 주요 Challenges (model capability, data scarcity, evaluation standardization)를 체계적으로 해결하는 WeEdit framework를 제시합니다. Glyph-guided SFT 및 multi-objective RL 을 통해 precise text placement와 character-level fidelity를 가능하게 하고, scalable HTML-based data construction pipeline 으로 대규모 multilingual training data를 확보했습니다. 또한, diverse editing operations과 15개 언어 를 포괄하는 종합적인 Benchmark를 구축하여 systematic model comparison의 기반을 마련했습니다. 이 연구는 text-centric image editing 분야의 SOTA 를 확립하고, 기존 open-source 및 대부분의 proprietary 모델을 능가하는 성능을 보여줌으로써, 이미지 내 텍스트 조작의 정확성과 범용성을 크게 향상시켰다는 점에서 학계와 산업계에 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Geo-Align: Video Generation Alignment via Metric Geometry Reward
- [논문리뷰] Stitched Value Model for Diffusion Alignment
- [논문리뷰] Video Models Can Reason with Verifiable Rewards
- [논문리뷰] Unlocking Complex Visual Generation via Closed-Loop Verified Reasoning
- [논문리뷰] RAVEN: Real-time Autoregressive Video Extrapolation with Consistency-model GRPO
Review 의 다른글
- 이전글 [논문리뷰] Video-Based Reward Modeling for Computer-Use Agents
- 현재글 : [논문리뷰] WeEdit: A Dataset, Benchmark and Glyph-Guided Framework for Text-centric Image Editing
- 다음글 [논문리뷰] XSkill: Continual Learning from Experience and Skills in Multimodal Agents
댓글