[논문리뷰] Video-Based Reward Modeling for Computer-Use Agents
링크: 논문 PDF로 바로 열기
저자: Linxin Song, Jieyu Zhang, Huanxin Sheng, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Computer-Use Agents (CUAs) : 데스크톱, 브라우저, 모바일 앱 등 실제 인터페이스에서 복잡한 다단계 작업을 수행할 수 있는 AI 에이전트.
- Execution Video Reward Model (ExeVRM) : 사용자 지침과 에이전트의 실행 비디오 시퀀스를 입력으로 받아, 에이전트 trajectory가 의도된 목표를 달성했는지 여부를 판단하는 reward model.
- Execution Video Reward 53k (ExeVR-53k) : ExeVRM 훈련을 위해 AgentNet, ScaleCUA, OSWorld 등 다양한 소스에서 큐레이션된 53,000개의 고품질 비디오-태스크-리워드 triplets으로 구성된 대규모 데이터셋.
- Adversarial Instruction Translation : 성공적인 trajectory와 의미상 불일치하는(semantically mismatched) 지침을 합성하여, step-level mismatch signal을 포함하는 hard negative sample을 생성하는 기법.
- Spatiotemporal Token Pruning (STP + TTP) : GUI 실행 비디오의 시공간적 token redundancy를 줄여 효율적인 학습을 가능하게 하는 전략. Spatial Token Pruning (STP) 은 프레임 내 시각적으로 균질한 영역을 제거하고, Temporal Token Pruning (TTP) 은 연속 프레임 간 거의 변하지 않는 token을 억제한다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Computer-use agents ( CUAs )는 일반적인 컴퓨터 자동화 분야에서 유망한 패러다임으로 부상하고 있지만, 에이전트 trajectory가 사용자 지침을 진정으로 이행하는지 여부를 평가하는 것은 여전히 어려운 과제로 남아 있습니다. 기존 벤치마크는 주로 수작업 스크립트나 태스크별 규칙에 의존하여 확장성과 새로운 환경으로의 전이가 제한적입니다. Reward model은 user instruction과 execution trajectory만으로 목표 달성 여부를 판단하는 유연한 대안이지만, CUA trajectory는 높은 redundancy (예: 툴바, 배경)와 성공 여부를 결정하는 미묘하고 국소적인 UI 변화라는 두 가지 주요 도전을 제시합니다. 또한, 공개 CUA 데이터셋은 주로 성공적인 trajectory에 초점을 맞추고 있어, reward modeling을 위한 균형 잡힌 정보성 negative sample이 부족합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 이러한 문제를 해결하기 위해 Execution Video Reward 53k (ExeVR-53k) 데이터셋을 구축하고, 장기간 고해상도 execution video 학습을 위한 Spatiotemporal Token Pruning (STP + TTP) 전략을 제안합니다. ExeVR-53k 는 AgentNet, ScaleCUA, OSWorld 등 여러 데이터셋의 상호작용 기록을 통합하여 통일된 step-level video representation으로 변환합니다. Negative supervision의 부족을 극복하기 위해, Adversarial Instruction Translation 기법을 도입하여 시각적으로 유사하지만 의미론적으로 불일치하는 instruction-trajectory 쌍을 합성합니다.
제안된 ExeVRM 은 Qwen3-VL 모델을 fine-tune하여 사용자 instruction과 video-execution sequence만으로 task success를 예측합니다. ExeVRM 8B 모델은 ExeVR-Bench에서 84.7% accuracy 와 87.7% recall 을 달성하며, GPT-5.2 (75.0% accuracy, 66.5% recall) 및 Seed-2.0 Pro (80.3% accuracy, 74.7% recall)와 같은 강력한 proprietary baseline을 능가합니다
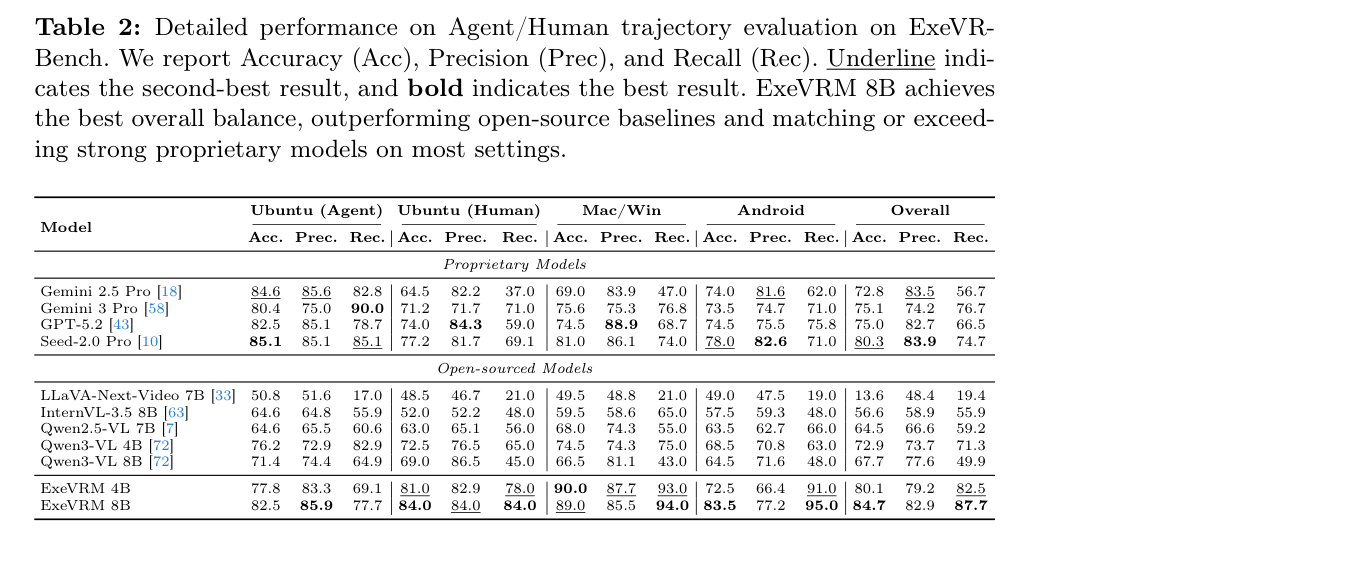 Table 2: Detailed performance on Agent/Human trajectory evaluation on ExeVR-Bench. We report Accuracy (Acc), Precision (Prec), and Recall (Rec). Underline indicates the second-best result, and bold indicates the best result. ExeVRM 8B achieves the best overall balance, outperforming open-source baselines and matching or exceeding strong proprietary models on most settings.
Table 2: Detailed performance on Agent/Human trajectory evaluation on ExeVR-Bench. We report Accuracy (Acc), Precision (Prec), and Recall (Rec). Underline indicates the second-best result, and bold indicates the best result. ExeVRM 8B achieves the best overall balance, outperforming open-source baselines and matching or exceeding strong proprietary models on most settings.
. 특히, Mac/Win 에서 89.0% accuracy와 94.0% recall, Android 에서 83.5% accuracy와 95.0% recall을 기록하며 모든 환경에서 일관된 성능 향상을 보였습니다. 또한, ExeVRM 은 결정적인 오류 구간을 localizing하는 데 있어 더 정확한 temporal attribution ( tIoU )을 보였으며, 모든 baseline보다 일관되게 높은 tIoU 를 달성했습니다
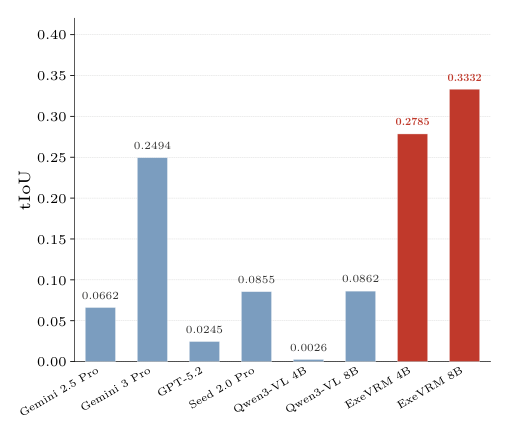 Figure 3: Comparison of temporal IoU (tIoU) scores across models on ExeVR-Bench.
Figure 3: Comparison of temporal IoU (tIoU) scores across models on ExeVR-Bench.
. STP+TTP 를 적용한 720p 입력은 360p 대비 completion judgment (특히 recall)을 크게 향상시키면서도 메모리-latency trade-off를 통해 장기간 학습을 가능하게 합니다 [Table 4]. STP와 TTP를 함께 적용했을 때 peak GPU memory와 per-step training time이 크게 감소하여, 더 긴 trajectory에서도 효율적인 학습이 가능함을 입증했습니다 [Figure 4].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Computer-Use Agents (CUAs) 의 reward modeling을 위한 비디오-실행 패러다임을 제시하며, ExeVR-53k 데이터셋과 Adversarial Instruction Translation 을 통해 고품질의 instruction-video-reward triplets을 제공합니다. 또한, 장기간 고해상도 실행 비디오의 효율적인 처리를 위한 Spatiotemporal Token Pruning (STP+TTP) 전략을 개발하여 redundant한 spatial 및 temporal token을 줄이면서도 결정적인 UI evidence를 보존합니다.
실험 결과, ExeVRM 8B 가 Ubuntu, macOS, Windows, Android를 포함한 다양한 플랫폼에서 뛰어난 성능을 보이며 기존 proprietary 및 open-weight baseline을 뛰어넘는 84.7% accuracy 와 87.7% recall 을 달성했습니다. 이는 비디오 기반 reward modeling이 CUA 를 위한 확장 가능하고 model-agnostic한 평가 도구로 활용될 수 있음을 시사합니다. 이 연구는 CUA 의 개발 및 평가 프로세스를 가속화하고, 에이전트가 실제 사용자 목표를 더 정확하게 이해하고 수행하는 데 기여할 중요한 발판을 마련했습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Omni-Reward: Towards Generalist Omni-Modal Reward Modeling with Free-Form Preferences
- [논문리뷰] JAMER: Project-Level Code Framework Dataset and Benchmark on Professional Game Engines
- [논문리뷰] MyPCBench: A Benchmark for Personally Intelligent Computer-Use Agents
- [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
- [논문리뷰] Skill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
Review 의 다른글
- 이전글 [논문리뷰] Understanding by Reconstruction: Reversing the Software Development Process for LLM Pretraining
- 현재글 : [논문리뷰] Video-Based Reward Modeling for Computer-Use Agents
- 다음글 [논문리뷰] WeEdit: A Dataset, Benchmark and Glyph-Guided Framework for Text-centric Image Editing
댓글