[논문리뷰] MonoArt: Progressive Structural Reasoning for Monocular Articulated 3D Reconstruction
링크: 논문 PDF로 바로 열기
The paper "MonoArt: Progressive Structural Reasoning for Monocular Articulated 3D Reconstruction" by Haitian Li, Haozhe Xie, Junxiang Xu, Beichen Wen, Fangzhou Hong, and Ziwei Liu from S-Lab, Nanyang Technological University, Singapore, presents a unified framework for monocular articulated 3D reconstruction.
I have extracted the authors and will now identify keywords and proceed with summarizing the paper according to the specified structure and constraints. I'll also identify the important figures for Part 2.
Authors : Haitian Li, Haozhe Xie, Junxiang Xu, Beichen Wen, Fangzhou Hong, Ziwei Liu. Keywords : Monocular 3D Reconstruction, Articulated Objects, Progressive Structural Reasoning, Kinematic Estimation, PartNet-Mobility, Deep Learning.
I'll go through each section of the paper to populate the summary.
Figures to consider for Part 2 :
- Figure 1 : Qualitative results and F-score vs. inference time comparison. This shows overall performance and efficiency.
- Figure 2 : Overview of MonoArt. This is the main architecture diagram.
- Figure 3 : Qualitative results on the test set of PartNet-Mobility. Shows reconstruction quality.
- Table 1 : Quantitative comparison on PartNet-Mobility. This contains key numerical results.
- Figure 5 : Robot manipulation application. Shows real-world applicability.
- Figure 6 : Articulated scene reconstruction application. Shows another application.
Given the criteria (architecture, key results/comparison, methodology explanation), Figure 2 (architecture), Figure 1 (overall performance comparison), and Figure 3 (qualitative results on benchmark) seem to be the most critical. Or perhaps Table 1 for quantitative results, instead of Figure 1's F-score graph. Let's prioritize Figure 2 (architecture), Table 1 (quantitative results), and Figure 3 (qualitative results). If Table 1 cannot be represented as an image URL, I will pick Figure 1. I need to check if Table 1 has an <img> tag or is just an HTML table. From the browsed content, it appears Table 1 is not an image but an HTML table. So, I will go with Figure 2 (architecture), Figure 1 (overall performance/efficiency), and Figure 3 (qualitative results).
I need to make sure the image URLs are absolute.
Figure 1: 2603.19231v1/x1.png -> https://arxiv.org/html/2603.19231v1/x1.png
Figure 2: 2603.19231v1/x2.png -> https://arxiv.org/html/2603.19231v1/x2.png
Figure 3: 2603.19231v1/x3.png -> https://arxiv.org/html/2603.19231v1/x3.png
Now, I will proceed with drafting the summary. 저자: Haitian Li, Haozhe Xie, Junxiang Xu, Beichen Wen, Fangzhou Hong, Ziwei Liu et al.
Part 1: 요약 본문
1. Key Terms & Definitions (핵심 용어 및 정의)
- Articulated 3D Reconstruction : 단일 이미지와 같은 시각적 관측에서 관절형(움직일 수 있는 부분으로 구성된) 3D 객체의 기하학적 구조, 부분(Part) 구성 및 운동학적 관계를 추론하는 과정.
- Progressive Structural Reasoning : 객체의 시각적 관측을 정규 기하학(Canonical Geometry), 구조화된 Part 표현, 그리고 motion-aware embedding으로 점진적으로 변환하여 안정적이고 해석 가능한 관절 추론을 가능하게 하는 방법론.
- TRELLIS-based 3D Generator : 입력 이미지로부터 정규 3D 형상과 geometry-aligned latent feature를 생성하는 모듈로, 하위 Part 추론 및 관절 추론을 위한 안정적인 기하학적 기반을 제공한다.
- Dual-Query Motion Decoder : Part의 semantic representation과 geometric localization을 두 가지 상보적인 query (content query와 position query)를 통해 분리하여 관절형 추론을 수행하는 모듈.
- Kinematic Estimator : Dual-Query Motion Decoder에서 refine된 query들을 기반으로 Part-level articulation parameter (joint type, axis, origin, limits)와 kinematic tree 구조를 예측하는 모듈.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
단일 이미지로부터 관절형 3D 객체를 재구성하는 것은 객체의 기하학적 구조, Part 구조 및 motion parameter를 제한된 시각적 증거로부터 함께 추론해야 하므로 여전히 근본적인 도전 과제이다. 특히, motion cues와 객체 구조 간의 얽힘(entanglement)으로 인해 직접적인 articulation parameter regression이 불안정하다는 핵심적인 어려움이 존재한다. 기존 방법론들은 이러한 문제를 해결하기 위해 multi-view supervision, retrieval-based assembly, 또는 auxiliary video generation과 같은 접근 방식을 사용했지만, 종종 확장성(scalability)이나 효율성(efficiency)을 희생해야 했다. 예를 들어, multi-view 방식은 여러 motion state의 이미지가 필요하며, retrieval-based 방식은 texture misalignment와 geometric inaccuracy를 초래할 수 있다. 또한, auxiliary video generation은 복잡하고 계산 비용이 많이 들며, vision-language model이나 handcrafted prior에 의존하는 방식은 일반화(generalization)를 제한하는 한계가 있었다. 이러한 한계점을 극복하기 위해, 저자들은 외부 모션 템플릿이나 다단계 파이프라인 없이도 안정적이고 해석 가능한 articulation inference를 가능하게 하는 새로운 접근 방식의 필요성을 제기한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 단일 이미지 기반의 관절형 3D 재구성을 위한 End-to-End 프레임워크인 MonoArt 를 제안한다. MonoArt는 시각적 관측을 canonical geometry, structured Part representation, 그리고 motion-aware embedding으로 점진적으로 변환하는 progressive structural reasoning에 기반한다. 이 프레임워크는 크게 네 가지 주요 구성 요소로 이루어진다: TRELLIS-based 3D Generator , Part-Aware Semantic Reasoner , Dual-Query Motion Decoder , 그리고 Kinematic Estimator
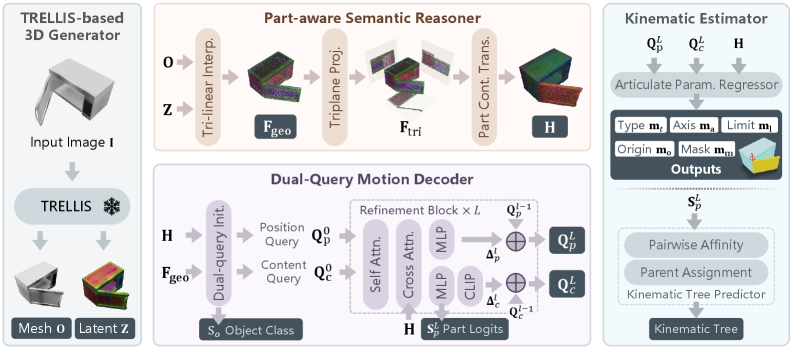
먼저, TRELLIS-based 3D Generator 는 입력 RGB 이미지 𝐈로부터 frozen TRELLIS 백본을 사용하여 canonical 3D 객체 형상 𝐎와 geometry-aligned latent feature 𝐙를 재구성한다. 이 𝐙는 sparse voxel latent representation으로, 하위 Part 추론 및 관절 추론을 위한 안정적인 기하학적 기반을 제공한다.
다음으로, Part-Aware Semantic Reasoner 는 𝐎와 𝐙로부터 Part-aware point feature 𝐇를 도출한다. 이는 Tri-linear Interpolation을 통해 표면점(surface point)에 feature를 정렬하고, Triplane Projection을 통해 전역 공간적 맥락을 통합하며, Part Contrast Transformer를 통해 Part-level embedding을 refine한다. 이 과정은 3D 구조적 annotation에 의해 지도(supervised)되며, triplet loss를 사용하여 discriminative motion-aware Part embedding을 학습한다.
이어서, Dual-Query Motion Decoder 는 Part의 semantic representation과 geometric localization을 분리하기 위해 content query (𝐐c)와 position query (𝐐p)라는 두 가지 상보적인 query를 사용한다. 이 dual query들은 전역 객체 맥락(global object context)으로부터 초기화되고, iterative refinement block을 통해 Part localization과 motion semantics를 공동으로 추론하여 motion-aware representation으로 refine된다. Dual-query Initialization은 전역 객체 컨텍스트에서 초기 𝐐c0 및 𝐐p0를 생성하며, Refinement Block은 Self-Attention과 Cross-Attention을 통해 𝐐p와 𝐐c를 잔여 방식(residual scheme)으로 업데이트한다. Query Confidence Estimation은 각 query의 Part 가설 신뢰도를 예측하여 유효한 Part를 선별한다.
마지막으로, Kinematic Estimator 는 refine된 dual query (𝐐pL, 𝐐cL)와 point embedding 𝐇를 사용하여 Part-level articulation parameter (Part mask, motion type, motion origin, motion axis, motion limits)를 예측하고 kinematic hierarchy (kinematic tree)를 추론한다. Part mask는 query-point matching을 통해 얻어지며, joint parameter는 MLP head를 통해 예측된다. Kinematic Tree Predictor는 Part category distribution과 학습 가능한 호환성 행렬을 사용하여 Part 간의 pairwise affinity를 계산하고, 단일 root, cycle-free 제약을 강제하여 유효한 kinematic hierarchy를 구축한다.
실험 결과, PartNet-Mobility 벤치마크에서 MonoArt는 기존 최신 방법론 대비 뛰어난 성능을 달성했다. 7개 클래스 부분 평가에서 CD 0.77 (↓), F-Score 0.728 (↑), Type Acc. 88.26% (↑), Axis Err. 0.209 (↓), Pivot Err. 0.085 (↓)를 기록하며 압도적인 성능을 보였다. 특히, SINGAPO 대비 F-Score 는 0.572 에서 0.728 로, Type Acc. 는 77.12% 에서 88.26% 로 크게 향상되었다 [Table 1]. 전체 46개 클래스 평가에서도 CD 1.25 (↓), F-Score 0.670 (↑), Type Acc. 67.47% (↑), Axis Err. 0.423 (↓), Pivot Err. 0.108 (↓)를 달성하여 일관되게 우수한 재구성 충실도와 높은 관절 유형 정확도를 보여주었다. 특히 Pivot Error 는 PhysXAny 대비 40% 이상 감소시켰다 [Table 1]. 또한, MonoArt는 기존 방법론보다 훨씬 낮은 추론 시간(inference time) 을 달성하여 효율성 측면에서도 강점을 보였다 (예: MonoArt 20.5초/instance vs. Articulate-Anything 229.9초/instance, SINGAPO 19.6초/instance)

정성적 결과는 MonoArt가 더 충실한 기하학적 구조와 더 정확한 관절 예측을 생성하여 더 그럴듯한 관절 모션을 제공함을 보여준다

4. Conclusion & Impact (결론 및 시사점)
저자들은 MonoArt를 통해 단일 이미지 기반 관절형 3D 재구성 분야에서 Progressive Structural Reasoning의 효과를 입증하였다. 이 프레임워크는 multi-view supervision, retrieval libraries 또는 auxiliary video synthesis에 의존하지 않고도, 기하학, Part 구조 및 motion을 통합된 방식으로 명시적으로 모델링함으로써 정확하고 효율적인 articulation inference를 가능하게 한다. PartNet-Mobility 데이터셋에 대한 광범위한 실험을 통해 MonoArt는 재구성 정확도와 추론 속도 모두에서 State-of-the-Art 성능을 달성했음을 보여주었다. 이 연구의 중요한 시사점은 명시적인 3D 구조적 prior를 embedding하는 것이 보다 정확할 뿐만 아니라 효율적인 관절형 재구성을 가능하게 한다는 점이다. 또한, MonoArt는 로봇 조작(robot manipulation) [Figure 5] 및 관절형 장면 재구성(articulated scene reconstruction) [Figure 6]과 같은 다운스트림 응용 분야에서도 효과적으로 일반화됨을 입증하여, 학계 및 산업계 전반에 걸쳐 그 실용적인 적용 가능성을 강조한다. 이는 단일 이미지로부터 물리적으로 그럴듯한(physically plausible) 관절형 모델을 생성하는 실용적인 real-to-sim 파이프라인을 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Xiaomi-GUI-0 Technical Report
- [논문리뷰] GEAR: Guided End-to-End AutoRegression for Image Synthesis
- [논문리뷰] Wan-Streamer v0.1: End-to-end Real-time Interactive Foundation Models
- [논문리뷰] Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models
- [논문리뷰] SceneCode: Executable World Programs for Editable Indoor Scenes with Articulated Objects
Review 의 다른글
- 이전글 [논문리뷰] Memento-Skills: Let Agents Design Agents
- 현재글 : [논문리뷰] MonoArt: Progressive Structural Reasoning for Monocular Articulated 3D Reconstruction
- 다음글 [논문리뷰] Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation
댓글