[논문리뷰] Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation
링크: 논문 PDF로 바로 열기
저자: Zhuolin Yang, Zihan Liu, Yang Chen, Wenliang Dai, Boxin Wang, Sheng-Chieh Lin, Chankyu Lee, Yangyi Chen, Dongfu Jiang, Jiafan He, Renjie Pi, Grace Lam, Nayeon Lee, Alexander Bukharin, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping
1. Key Terms & Definitions (핵심 용어 및 정의)
- Nemotron-Cascade 2 : NVIDIA에서 개발한 오픈 소스 30B MoE (Mixture-of-Experts) 모델로, 3B의 활성화된(activated) 파라미터를 사용하며, Reasoning 및 Agentic Capabilities에서 Best-in-Class 성능을 제공한다.
- Cascade RL (Cascaded Reinforcement Learning) : Nemotron-Cascade 1에서 도입된 프레임워크로, Specialized Task Domain에 걸쳐 Sequential, Domain-wise RL Training을 조율하여 다중 도메인 RL의 Engineering Complexity를 단순화한다.
- Multi-domain On-Policy Distillation (MOPD) : Cascade RL 프로세스 전반에 걸쳐 각 도메인에서 Best-Performing Intermediate Teacher Model로부터 Knowledge를 Distill하여 Benchmark Regressions를 효율적으로 회복하고, 강력한 성능 향상을 유지하는 메커니즘이다.
- Instruction-Following Reinforcement Learning (IF-RL) : Nemotron-Cascade 2의 Cascade RL 초기 단계로, 모델의 Foundational Instruction Adherence를 확립하는 데 중점을 둔다.
- MoE (Mixture-of-Experts) : 모델의 전체 파라미터 중 일부 Expert만 활성화하여 Inference Efficiency를 높이는 LLM 아키텍처이다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Reinforcement Learning (RL)은 LLM Post-Training의 핵심으로 부상하며 Reasoning, Agentic Capabilities, Real-World Problem-Solving 발전에 기여하고 있습니다. 그러나 모델이 점점 더 정교한 요구 사항을 처리함에 따라, 광범위한 RL Environment와 매우 다양한 Reasoning 및 Agentic Tasks를 Training Process를 불안정하게 만들지 않고 성공적으로 통합하는 것이 주된 과제였습니다. 기존 Nemotron-Cascade 1 은 Cascade RL 프레임워크를 통해 이러한 복잡성을 줄이고 Catastrophic Forgetting에 대한 강건성을 보였지만, 더 복잡한 RL Environment에서 Training 시 발생할 수 있는 Capability Drift 및 Benchmark Regressions 문제는 여전히 존재했습니다. 본 연구는 이러한 한계점을 극복하고, 특히 수학 및 코딩 Reasoning과 Agentic Tasks에서 Frontier Open Model에 필적하는 성능을 달성하기 위해 Multi-Domain On-Policy Distillation (MOPD) 을 Cascade RL에 통합한 새로운 접근 방식의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Nemotron-Cascade 2 를 제안하며, 이는 Supervised Fine-Tuning (SFT) 을 통해 수학, 코딩, 과학, 툴 사용, Agentic Tasks, 일반 채팅, Instruction Following, 안전, 대화형 에이전트, 소프트웨어 엔지니어링 에이전트, 터미널 에이전트 등 광범위한 도메인에서 Foundational Capabilities를 구축합니다. 이 SFT 단계는 Nemotron-Cascade-2-SFT-Data 컬렉션을 활용합니다.
이후 Cascade RL 파이프라인을 적용하며
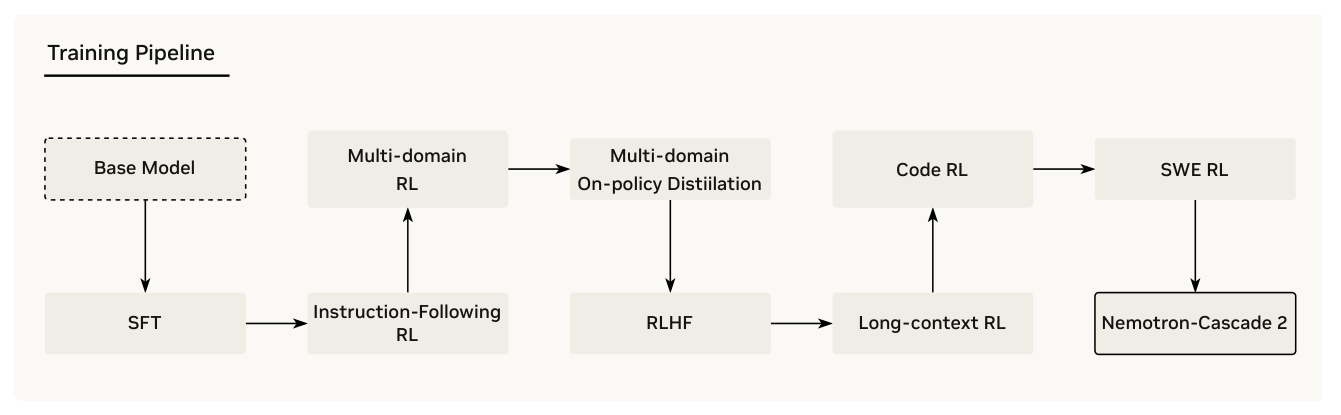
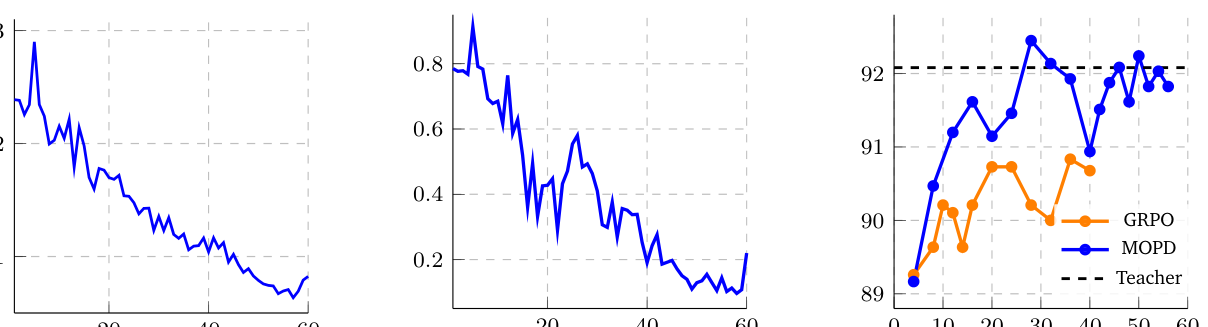
에 명시된 바와 같이 sequential, domain-wise Training을 진행합니다. 초기 Instruction-Following RL (IF-RL) 로 Instruction Adherence를 확립하고, 이어지는 Multi-domain RL 단계에서 STEM 도메인의 MCQA, Agentic Tool Calling, Structured Output 기능을 강화합니다. 이 과정에서 MOPD 가 핵심적인 안정화 단계로 도입됩니다. MOPD 는 Cascade RL Training 과정 중 Best-Performing Intermediate Teacher Model에서 Knowledge를 Distill하여 Benchmark Regressions를 회복하고 성능 향상을 유지합니다. MOPD 는 Token-Level Distillation Advantage를 제공하여 Sparse Sequence-Level Outcome Reward에 의존하는 GRPO 대비 더 적은 Optimization Step으로 더 강력한 성능을 달성함을 [Figure 3(c)]에서 보여줍니다. 예를 들어, AIME25 벤치마크에서 MOPD 는 30 스텝 만에 92.0 %에 도달한 반면, GRPO 는 25 스텝 후 91.0 %에 머물렀습니다.
핵심 결과는 다음과 같습니다:
- Nemotron-Cascade-2-30B-A3B 는 2025 International Mathematical Olympiad (IMO) , International Olympiad in Informatics (IOI) , 그리고 ICPC World Finals 에서 Gold Medal-Level 성능을 달성했습니다 [Table 1], [Table 2]. 이는 DeepSeek-V3.2-Speciale-671B-A37B 대비 20배 적은 파라미터로 높은 Intelligence Density를 보여줍니다.
- 수학 Reasoning 벤치마크에서 IMO AnswerBench 79.3 , AIME 2025 92.4% (TIR 98.6% ), HMMT Feb25 94.6% 를 기록하여 Nemotron-3-Super-120B-A12B 와 Qwen3.5-35B-A3B 를 뛰어넘는 성능을 보였습니다
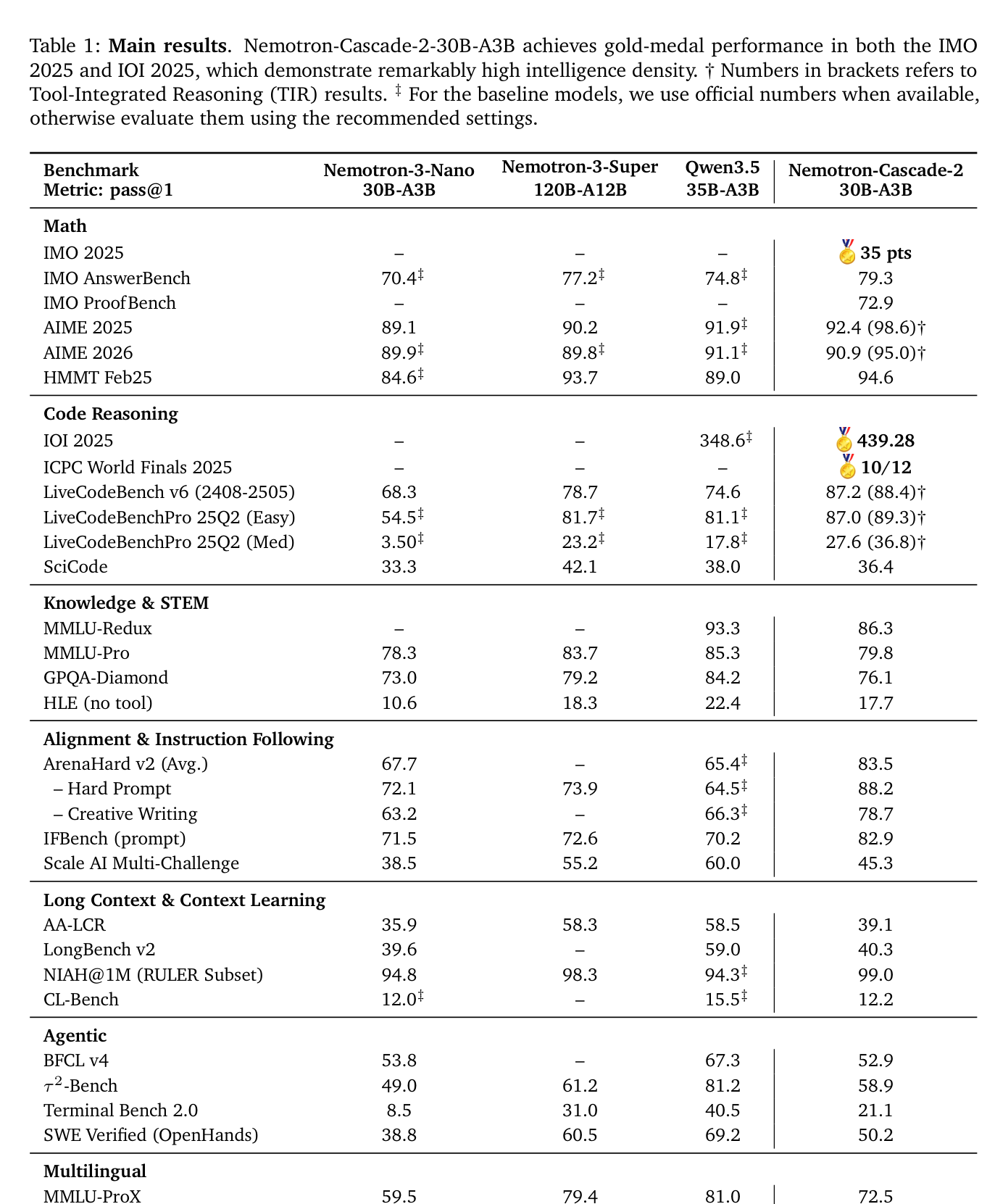
- 코딩 Reasoning 벤치마크에서 IOI 2025 439.28 , ICPC World Finals 2025 10/12 , LiveCodeBench v6 87.2% (TIR 88.4% )를 달성하여 강력한 Agentic Capabilities를 입증했습니다 [Table 1].
- MOPD 는 ArenaHard v2.0 벤치마크에서 Hard Prompt 점수를 52 스텝 만에 85.5% 로 향상시켰으며, 이는 160 스텝에서 80.7% 를 기록한 RLHF 보다 훨씬 빠른 수렴 속도와 높은 성능을 보여주었습니다 [Table 3].
- SWE (Software Engineering) RL 을 통한 Agentless RL Training은 OpenHands 스캐폴드에서 Pass@4 65.0% 를 달성하며 Agentic SWE Tasks의 성능 향상에 기여했습니다 [Table 4].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Nemotron-Cascade 2 가 30B MoE 라는 Compact Size에도 불구하고 최첨단 Reasoning 및 Agentic Capabilities를 제공하며, 특히 국제 수학 및 코딩 올림피아드에서 Gold Medal-Level 성능을 달성했음을 보여줍니다. Cascade RL 프레임워크와 Multi-Domain On-Policy Distillation (MOPD) 의 통합은 복잡한 RL 환경에서 Training을 안정화하고 성능을 최적화하는 데 매우 효과적임을 입증했습니다. 이는 작은 모델에서도 높은 Intelligence Density를 달성할 수 있음을 시사하며, 오픈 소스 LLM의 성능 한계를 확장하는 중요한 이정표가 됩니다. 모델 가중치, Training Data, 방법론적 세부 사항의 오픈 소싱은 연구 커뮤니티가 RL 기반 LLM Post-Training 패러다임을 재현, 분석 및 확장하는 데 기여하여 Reasoning, Agentic Capabilities 및 Long-Context Understanding 분야의 발전을 가속화할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
- [논문리뷰] Gemma 4 Technical Report
- [논문리뷰] dOPSD: On-Policy Self-Distillation for Diffusion Language Models
Review 의 다른글
- 이전글 [논문리뷰] MonoArt: Progressive Structural Reasoning for Monocular Articulated 3D Reconstruction
- 현재글 : [논문리뷰] Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation
- 다음글 [논문리뷰] OSM-based Domain Adaptation for Remote Sensing VLMs
댓글