[논문리뷰] OSM-based Domain Adaptation for Remote Sensing VLMs
링크: 논문 PDF로 바로 열기
Now I have the content of the paper. I will proceed with extracting the requested information and structuring the output.
**Part 1: Summary**
**Authors:** Stefan Maria Ailuro, Mario Markov, Mohammad Mahdi, Delyan Boychev, Luc Van Gool, Danda Pani Paudel
**Keywords:** `Remote Sensing`, `Vision-Language Models`, `Domain Adaptation`, `OpenStreetMap`, `Pseudo-labeling`, `Geographic Supervision`, `Instruction Tuning`, `Self-contained`
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- **Vision-Language Models (VLMs)** : 위성 및 항공 이미지와 같은 시각적 데이터를 자연어 텍스트와 연결하여 이해하고 생성하는 AI 모델.
- **Domain Adaptation** : 특정 도메인(예: 일반 이미지)에서 학습된 모델을 다른 도메인(예: 원격 감지 이미지)에 효과적으로 적용하는 과정.
- **OpenStreetMap (OSM)** : 전 세계적으로 crowd-sourced된 지리 정보 데이터베이스로, 도로 네트워크, 토지 이용, 관심 지점 등 다양한 지리 데이터를 포함.
- **Pseudo-labeling** : 비용이 많이 드는 수동 주석(manual annotation) 없이 대규모 데이터를 자동으로 레이블링하여 훈련 데이터를 생성하는 기술.
- **OSMDA-Captions** : OSMDA 프레임워크를 통해 생성된, OpenStreetMap 데이터가 풍부하게 반영된 20만 개 이상의 이미지-캡션 쌍으로 구성된 고품질 데이터셋.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
원격 감지(Remote Sensing) 분야의 Vision-Language Models (VLMs)는 위성 및 항공 이미지의 풍부함에도 불구하고, 고품질의 도메인 특화 이미지-텍스트 주석(annotation)이 **희소하고 생성 비용이 높다** 는 문제에 직면해 있습니다. 기존의 pseudo-labeling 파이프라인은 주로 GPT-4V와 같은 강력한 frontier 모델로부터 지식(knowledge)을 distillation하는 방식에 의존했습니다. 그러나 이러한 접근 방식은 대규모 teacher 모델에 대한 의존성으로 인해 **비용이 많이 들고(costly), 확장성(scalability)이 제한되며, teacher 모델의 성능 한계에 묶이는(caps achievable performance at the ceiling of the teacher)** 근본적인 제약이 있었습니다. 또한, teacher 모델의 오류나 hallucination이 student 모델에 그대로 흡수될 수 있다는 단점도 있습니다. 이러한 한계점은 보다 저렴하고 확장 가능한(cheap, scalable) 도메인 적응 방법론의 필요성을 제기합니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 기존의 teacher 모델 의존성을 제거한 **self-contained domain adaptation framework인 OSMDA** 를 제안합니다. 핵심 아이디어는 강력한 base VLM이 OpenStreetMap (OSM) 타일과 aerial 이미지를 pairing하여 자체적인 annotation engine 역할을 할 수 있다는 것입니다. VLM의 **Optical Character Recognition (OCR)** 및 **chart comprehension** 능력을 활용하여 OSM의 방대한 auxiliary metadata로 enriched된 caption을 생성합니다. 이후 이 corpus를 사용하여 satellite 이미지만으로 모델을 fine-tuning하여 **OSMDA-VLM** 을 생성합니다 [cite: 1, Figure 2]. 이 전체 파이프라인은 API access, proprietary data, 또는 expert-level human label 없이도 자율적으로 작동합니다.
OSMDA 방법론은 세 단계로 구성됩니다: (1) **Data Curation** : SkyScript 데이터셋을 기반으로 OSM object filtering, semantic labelling, distribution balancing을 통해 200,514개의 고품질 위성 이미지를 선별합니다. (2) **Map Rendering** : Mapnik 라이브러리와 openstreetmap-carto 스타일시트를 사용하여 OSM 데이터를 VLM이 읽을 수 있는 semantically rich map tile로 렌더링합니다. 이때 OSM object의 toponyms와 address lines는 LLM이 생성한 2-3단어 semantic label로 대체되어 VLM의 OCR pathway에 최적화됩니다. (3) **Caption Generation** : Satellite 이미지와 렌더링된 map을 base VLM에 입력하여 상세한 지리적 캡션을 생성하는 **OSMDA-Captions** 데이터셋을 구축합니다. 이 과정에서 모델은 map을 참조하지 않고도 지리적으로 grounded된 설명을 생성하도록 학습됩니다.
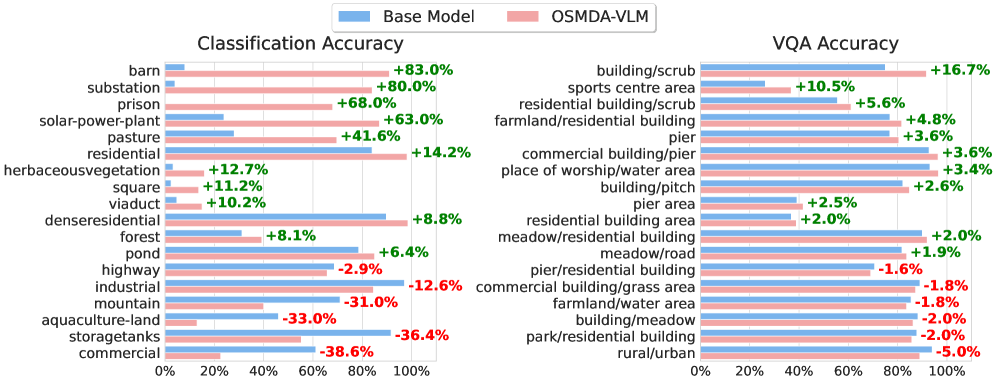
실험 결과, **OSMDA-VLM** 은 10개 벤치마크(captioning, counting, multiple-choice, VQA, classification 포함) 전반에 걸쳐 경쟁 모델 대비 **state-of-the-art (SOTA)** 성능을 달성했습니다. 특히, **OSMDA-VLM** 은 10개 벤치마크 중 6개에서 가장 높은 성능을 기록했으며, 9개 벤치마크에서는 top-3 안에 들었습니다 [cite: 1, Table 2]. zero-shot setting인 generalization-split에서는 **XLRS-Bench** 와 **Million-AID** 에서 모든 baseline을 **큰 마진으로 능가** 했습니다 [cite: 1, Table 2]. 정량적 지표로는 **G-Eval** 및 **F1 score** 가 사용되었으며. 예를 들어, **VRSBench (caption)** 에서 OSMDA-VLM은 **0.429 G-Eval** 을 기록하여 base-fine-tuned 모델의 **0.434 G-Eval** 과 유사한 높은 성능을 보였고, **XLRS-Bench (vqa)** 에서는 **0.216 F1 score** 로 다른 모델들을 크게 앞섰습니다 [cite: 1, Table 2]. Figure 4는 OSMDA 방법론이 base model의 generalization을 가장 크게 향상시켰음을 보여줍니다 [cite: 1, Figure 4]. OSMDA-Captions로 먼저 학습한 후 fine-tuning하는 것이 base model을 직접 fine-tuning하는 것보다 더 나은 downstream task 성능을 가져왔습니다 [cite: 1, Figure 4]. 또한, 더 큰 teacher 모델(gemma-3-27b-it)로 생성된 caption으로 학습하는 것보다 OSMDA 방식이 훨씬 우수한 성능을 보였습니다.
## 4. Conclusion & Impact (결론 및 시사점)
본 연구는 원격 감지 VLM을 위한 **OSMDA (OpenStreetMap-based Domain Adaptation)** 라는 완전히 self-contained된 도메인 적응 프레임워크를 성공적으로 제시했습니다. 이 방법론은 값비싼 teacher-dependent pseudo-labeling을 OpenStreetMap에서 직접 추출한 supervision으로 대체함으로써, manual annotation, proprietary API, 또는 더 강력한 외부 모델 없이도 대규모의 상세하고 지리적으로 grounded된 캡션 데이터셋인 **OSMDA-Captions** 를 생성할 수 있게 합니다. 광범위한 통합 평가를 통해 OSMDA 방법이 downstream task에 대한 fine-tuned performance와 zero-shot generalization 모두를 향상시킨다는 것을 입증했습니다. 특히, **OSMDA-Captions** 와 표준 벤치마크 훈련 데이터를 혼합하여 학습한 **OSMDA-VLM** 은 기존의 frontier-teacher distillation 파이프라인보다 훨씬 저렴하고 확장 가능하면서도 **state-of-the-art 성능** 을 달성했습니다.
이 연구는 기존 RS-VLM에서 흔히 발견되는 **instruction brittleness** 문제를 해결하고, self-generated, map-grounded supervision이 generalization을 개선하면서 **instruction-following robustness** 를 유지할 수 있음을 보여줍니다. 이는 강력한 foundation VLM과 crowd-sourced geographic data를 결합하는 것이 확장 가능한 원격 감지 적응을 위한 실용적인 경로임을 시사하며, 비용이 많이 드는 human label과 불안정한 teacher 모델을 대체할 수 있는 지속 가능한 대안을 제공합니다.
> ⚠️ **알림:** 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation
- 현재글 : [논문리뷰] OSM-based Domain Adaptation for Remote Sensing VLMs
- 다음글 [논문리뷰] ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents
댓글