[논문리뷰] Deep Tabular Research via Continual Experience-Driven Execution
링크: 논문 PDF로 바로 열기
저자: Junnan Dong, Chuang Zhou, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Deep Tabular Research (DTR) : 계층적이고 양방향 헤더, 병합된 셀, 비정규화된 레이아웃 등을 특징으로 하는 unstructured table에서 발생하는 long-horizon의 복잡한 tabular reasoning task를 해결하기 위한 프레임워크입니다.
- Meta Graph : 불규칙한 table format에서 추출된 metadata를 기반으로 header 및 content element를 node로, 포함 또는 계층적 관계를 edge로 구성하여 table의 semantic structure를 포착하는 그래프 표현입니다.
- Expectation-Aware Selection Policy : DTR 프레임워크 내에서 불확실성 하에 유망한 execution trajectory를 식별하기 위해 path의 anticipated utility를 평가하는 정책으로, exploration과 exploitation의 균형을 맞춥니다.
- Siamese Structured Memory : DTR 시스템이 과거 execution outcome과 failure를 기록하고 합성하여 planning strategy를 지속적으로 refine할 수 있도록 하는 memory 모듈로, parameterized update와 abstracted textual experience를 통해 구성됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Large language models (LLMs)는 구조화된 데이터에 대한 reasoning에서 상당한 능력을 보여주었지만, hierarchical 및 bidirectional header , merged cell , non-canonical layout 을 포함하는 unstructured table에 대한 complex long-horizon analytical task 에서는 어려움을 겪습니다. 기존 TableQA pipelines은 일반적으로 clean schema , flat header , single-pass reasoning 에 의존하여 실제 시나리오에서의 적용 가능성이 제한적입니다 [Figure 1]. 이러한 테이블은 implicit semantic relations 을 포함하며, 단일 query가 여러 table region에 걸친 factual check , numerical computation , aggregation 을 요구하는 multi-hop reasoning 이 필요합니다. 이러한 한계를 극복하기 위해, 저자들은 programmatic execution approach를 제안하며, 이는 방대한 execution path search space 와 복잡한 long execution 중 오류 전파 라는 두 가지 주요 challenge를 야기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 tabular reasoning을 continual decision process 로 처리하는 Deep Tabular Research (DTR) 프레임워크를 제안합니다
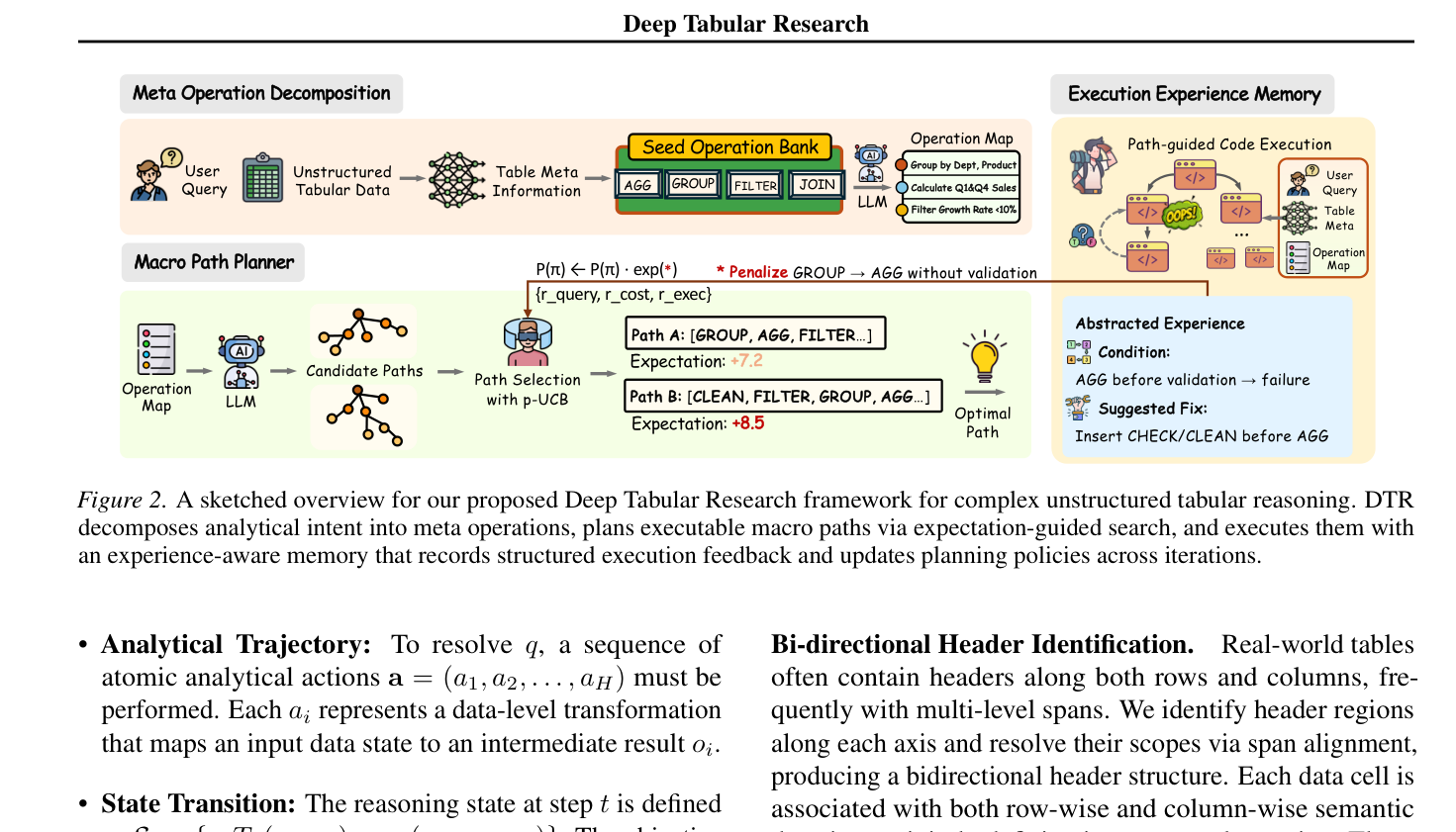
DTR은 high-level strategic planning과 low-level execution을 명확히 분리하여, accumulated feedback 을 통해 reasoning을 지속적으로 refine합니다. 구체적으로, (i) Meta Graph Construction 을 통해 bidirectional semantics를 포착하고, natural language query를 operation-level search space로 mapping합니다. (ii) Expectation-Aware Selection Policy 는 high-utility execution path를 우선순위로 지정하여 space를 navigation합니다. (iii) Siamese Structured Memory 는 historical execution outcome을 합성하여 지속적인 refinement를 가능하게 합니다.
실험 결과, DTR-Bench와 RealHitBench 두 벤치마크에서 DTR은 기존 baseline을 일관적으로 능가 하는 성능을 보였습니다. DTR-Bench에서 DTR (DS-v3)는 Accuracy Win Rate 에서 1.93 을 기록하며 DeepSeek-V3의 1.28 대비 높은 성능 을 보여주었고, Analysis Depth Score Rate 에서도 30.23 으로 DeepSeek-V3의 25.22 보다 우수 했습니다
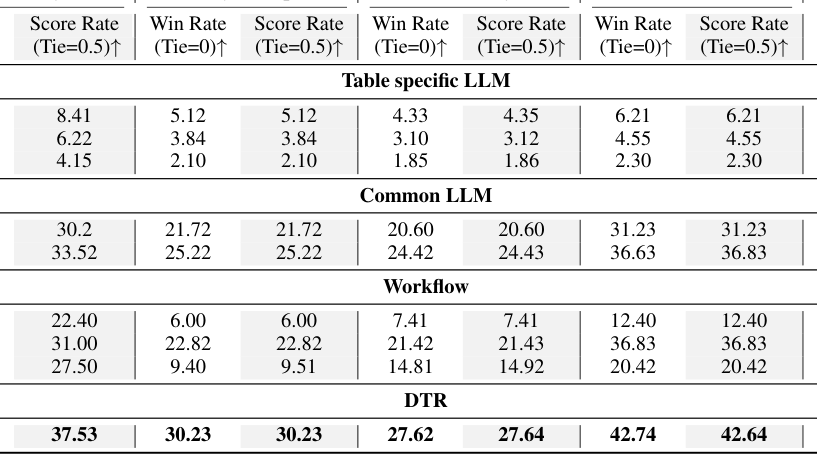
또한, Total Output LLM Tokens 및 Avg. LLM Calls 측면에서 효율성을 유지하며 낮은 오류율 을 달성했습니다. RealHitBench에서는 DTR (DeepSeek-v3)가 Fact Checking EM↑ 에서 58.22 , Numerical Reasoning EM↑ 에서 55.51 를 기록하여, Code Loop (DeepSeek-v3)의 48.19 및 42.93 대비 상당히 높은 성능 을 보였습니다
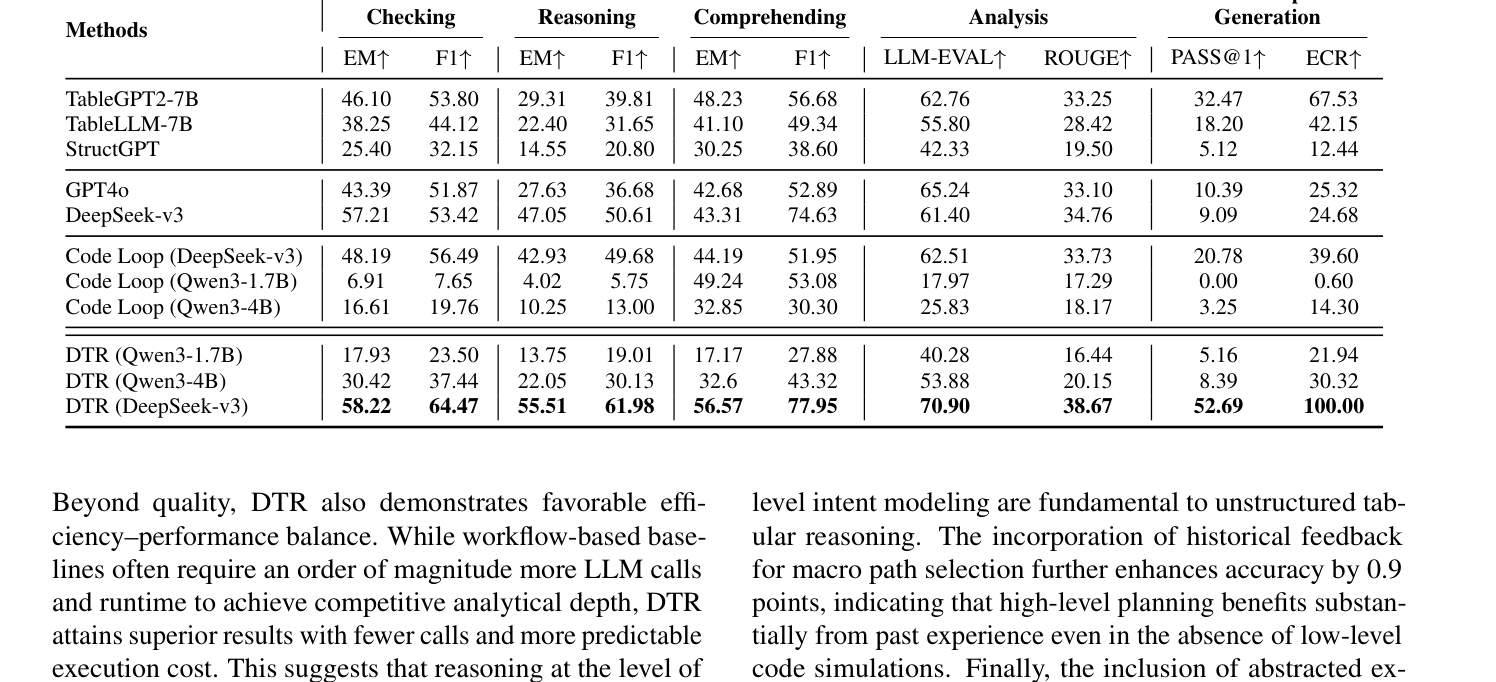
특히, Chart/Report Generation ECR↑ 에서는 100.00 을 달성하여 모든 baseline을 압도했습니다. 이는 DTR이 복잡한 실세계 데이터 layout을 처리하는 데 효과적이고 효율적임을 입증합니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Deep Tabular Research (DTR)를 unstructured table에 대한 long-horizon analytical reasoning task 의 새로운 패러다임으로 정립합니다. DTR은 tabular reasoning을 executable operation 에 기반한 closed-loop decision-making process 로 처리하는 principled agentic framework를 제안합니다. 이 프레임워크는 query-aware operator abstraction , expectation-driven path selection , experience-based memory refinement 를 통해 structural ambiguity 및 execution uncertainty 하에서도 견고한 reasoning을 가능하게 합니다. DTR의 성공적인 결과는 high-level planning과 low-level execution을 분리하고, continual experience-driven execution 을 통해 deep tabular research 의 강력한 기반을 마련하는 것의 중요성을 강조합니다. 이 연구는 데이터 분석 워크플로우에서 수동 작업과 오류를 줄이는 데 기여하며, 과학 분석, 비즈니스 인텔리전스, 공공 데이터 보고 등 데이터 기반 도메인 의 의사결정 지원을 향상시킬 수 있는 잠재력을 가집니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PersonalAI 2.0: Enhancing knowledge graph traversal/retrieval with planning mechanism for Personalized LLM Agents
- [논문리뷰] REVERE: Reflective Evolving Research Engineer for Scientific Workflows
- [논문리뷰] Memento-Skills: Let Agents Design Agents
- [논문리뷰] Automating the Design of Embodied Agent Architectures
- [논문리뷰] When Classic Cache Policies Fail: Learning-Augmented Replacement for Semantic Retrieval Buffers
Review 의 다른글
- 이전글 [논문리뷰] CurveStream: Boosting Streaming Video Understanding in MLLMs via Curvature-Aware Hierarchical Visual Memory Management
- 현재글 : [논문리뷰] Deep Tabular Research via Continual Experience-Driven Execution
- 다음글 [논문리뷰] EgoForge: Goal-Directed Egocentric World Simulator
댓글