[논문리뷰] EgoForge: Goal-Directed Egocentric World Simulator
링크: 논문 PDF로 바로 열기
저자: Yifan Shen, Jiateng Liu, Xinzhuo Li, et al.
키워: Egocentric World Simulator, Video Generation, Diffusion Models, Goal-Directed Control, Geometry Weak Supervision, Reward-Guided Refinement, X-Ego Benchmark
1. Key Terms & Definitions (핵심 용어 및 정의)
- EgoForge : 단일 egocentric image, high-level instruction, 그리고 선택적인 auxiliary exocentric view로부터 coherent하고 goal-directed egocentric video rollouts를 생성하는 egocentric world simulator.
- VideoDiffusionNFT : goal completion, temporal causality, scene stability, perceptual fidelity를 최적화하여 diffusion sampling을 steer하는 trajectory-level reward-guided refinement 메커니즘.
- X-Ego Benchmark : 복잡한 scene에서 fine-grained conditioning signals을 사용하여 egocentric world models의 성능을 평가하기 위해 새로 curation된 large-scale benchmark.
- Geometry Weak Supervision : diffusion backbone에 3D reasoning을 주입하여 spatially stable rollouts를 장려하고 spatial 및 physical coherence를 보장하는 메커니즘.
- Egocentric Video Rollouts : 사용자 intent를 따르고 scene structure를 유지하는 first-person video sequence.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Generative world models는 dynamic environment를 simulate하고 reason하는 데 중요한 발전을 보였지만, egocentric vision에서는 rapid viewpoint changes, frequent hand-object interactions, 그리고 latent human intent에 의존하는 complex goal-directed behavior로 인해 어려움을 겪습니다. 기존 egocentric video generation 접근 방식은 세 가지 근본적인 한계에 직면해 있습니다. 첫째, camera trajectories, long video prefixes, synchronized multi-view capture와 같은 Dense supervision requirements 가 필요하여 비용이 많이 들고 inference 시 신뢰하기 어렵습니다. 둘째, short textual prompts나 predefined low-level actions에만 condition하여 multi-step behavior에 대한 Limited goal-directed control 을 제공합니다. 셋째, visual realism에만 최적화되어 spatial coherence가 부족한 Weak physical grounding 으로 인해 embodied egocentric motion이나 object interaction에 대한 consistent reasoning이 어렵습니다. 이러한 문제들은 immersive하고 interactive한 XR platform의 요구사항을 충족시키기 어렵게 만듭니다.

은 EgoForge가 real-world smart-glasses 실험에서 생성한 egocentric video rollout의 예시를 보여주며, 기존 방법론의 한계를 극복하고자 하는 연구의 동기를 명확히 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 challenge를 해결하기 위해 EgoForge 를 제안합니다.
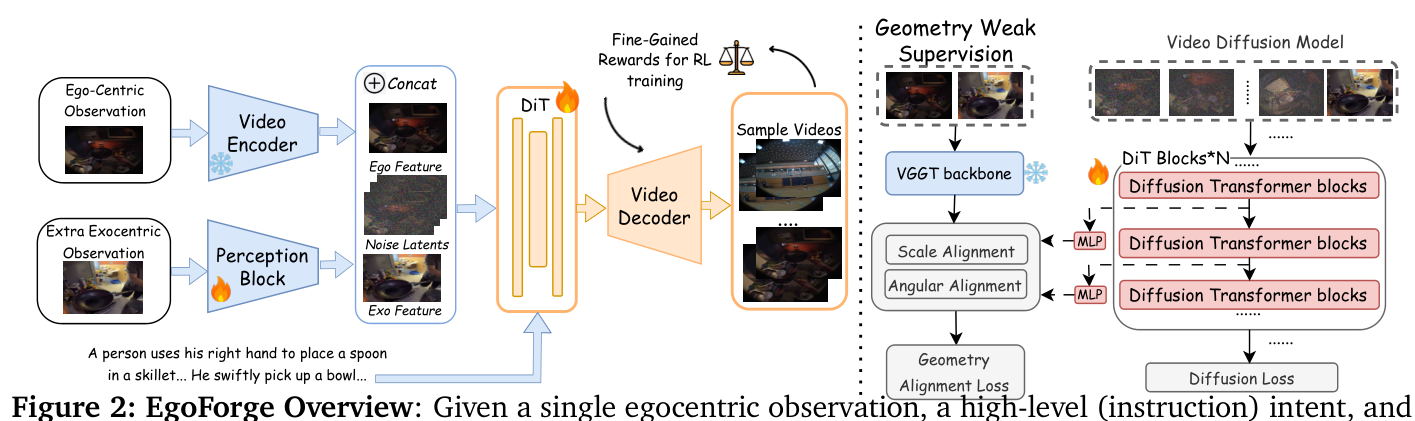
는 EgoForge의 전체 architecture를 보여줍니다. EgoForge는 pretrained video autoencoder의 latent space에서 video generation을 수행하는 diffusion-transformer backbone을 기반으로 합니다. 이 방법론은 크게 두 가지 핵심 구성 요소로 나뉩니다. 첫째, Geometry Weak Supervision 은 pretrained VGGT backbone에서 추출된 geometry features와 diffusion backbone의 intermediate representations를 alignment하여 3D reasoning을 diffusion process에 주입합니다. 이를 위해 angular alignment loss (L_ang)와 scale alignment loss (L_sca)를 사용하여 spatial 및 physical coherence를 강화합니다. 둘째, VideoDiffusionNFT 는 trajectory-level reward-guided refinement 메커니즘으로, goal completion ( R_goal ), scene consistency ( R_env ), temporal causality ( R_temp ), 그리고 perceptual fidelity ( R_per )를 최적화하여 diffusion sampling이 coherent하고 goal-consistent한 rollouts를 생성하도록 guide합니다. 이 reward-guided refinement는 negative-aware finetuning을 통해 모델이 suboptimal sample로부터 멀어지도록 학습시킵니다.
X-Ego Benchmark 에 대한 광범위한 실험에서 EgoForge 는 모든 metrics에서 strong baselines를 consistent하게 outperform했습니다. 가장 강력한 baseline 대비, semantic alignment 는 DINO-Score 에서 + 13.5% , CLIP-Score 에서 + 10.1% 상승했습니다. Structural fidelity 는 SSIM 에서 + 9.7% , PSNR 에서 + 17.8% 향상되었고, perceptual error 는 LPIPS 에서 35% 감소했습니다. 특히, temporal modeling 에서는 FVD 에서 43% 감소, flow MSE 에서 51% 감소를 달성하며 크게 향상된 성능을 보였습니다.
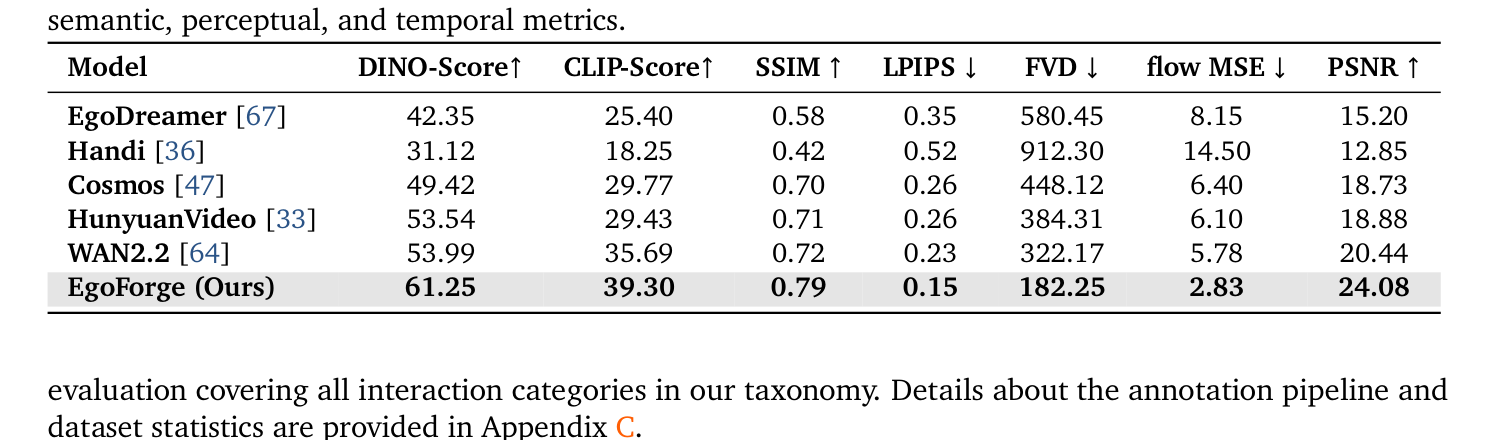
은 이러한 정량적 비교 결과를 자세히 보여줍니다. User study ([Table 4])에서도 EgoForge는 Quality ( 4.58↑ ), Fidelity ( 4.71↑ ), Smooth Motion ( 4.25↑ ), Smooth Environment ( 4.48↑ ), Alignment ( 4.75↑ ) 등 모든 측면에서 가장 높은 평가를 받았습니다. Ablation study ([Table 5] 및 [Table 6])는 VideoDiffusionNFT 와 Geometry Weak Supervision 을 포함한 각 component가 성능 향상에 필수적임을 입증했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 egocentric goal-directed world simulator인 EgoForge 를 도입했습니다. EgoForge 는 단일 egocentric observation, high-level instruction, 그리고 선택적인 auxiliary exocentric view라는 minimal static input으로부터 coherent하고 goal-directed first-person video rollouts를 생성합니다. Geometry-aware grounding과 novel trajectory-level reward-guided refinement 메커니즘인 VideoDiffusionNFT 를 통합하여 spatial consistency, intent alignment, 그리고 temporal coherence를 동시에 최적화합니다. 광범위한 실험과 real-world smart-glasses deployment를 통해, EgoForge 는 강력한 baselines를 consistently outperform하며, 향상된 instruction alignment, realistic egocentric motion, 그리고 stable scene evolution을 입증했습니다. 이 연구는 immersive world models, interactive simulation, 그리고 human-centered XR systems 분야의 미래 연구를 촉진하는 데 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Deep Tabular Research via Continual Experience-Driven Execution
- 현재글 : [논문리뷰] EgoForge: Goal-Directed Egocentric World Simulator
- 다음글 [논문리뷰] FlowScene: Style-Consistent Indoor Scene Generation with Multimodal Graph Rectified Flow
댓글