[논문리뷰] RoboAlign: Learning Test-Time Reasoning for Language-Action Alignment in Vision-Language-Action Models
링크: 논문 PDF로 바로 열기
The content is here. I need to parse it to extract the required information.
Part 1: Summary
- Authors : Dongyoung Kim, Sumin Park, Woomin Song, Seungku Kim, Taeyoung Kim, Huiwon Jang, Jinwoo Shin, Jaehyung Kim, Younggyo Seo
- Keywords : I will identify 5-8 relevant keywords from the abstract and introduction. Potential candidates:
Vision-Language-Action Models (VLAs),Multimodal-Large-Language Models (MLLMs),Reinforcement Learning (RL),Supervised Fine-tuning (SFT),Embodied Reasoning,Low-level Actions,Robotics,FAST tokenization. - Key Terms & Definitions :
VLA (Vision-Language-Action Models)MLLM (Multimodal-Large-Language Models)FAST tokenizationGRPO (Group Relative Policy Optimization)Embodied Reasoning
- Motivation & Problem Statement :
- MLLMs are crucial for VLAs but struggle with embodied reasoning tasks (spatial, temporal reasoning).
- Existing approaches using VQA-type supervision for embodied reasoning lead to unstable VLA performance, often marginal or negative gains.
- There is a "modality gap" between language supervision (optimizing embodied reasoning) and actual low-level action generation.
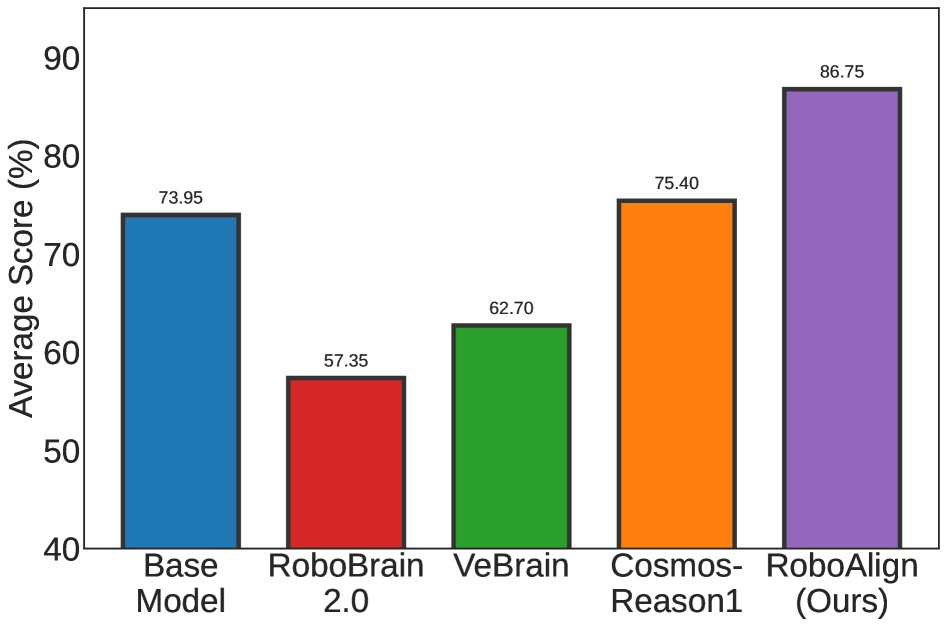
- Figure 1 shows that MLLMs specialized for embodied reasoning often degrade VLA performance.
- Method & Key Results :
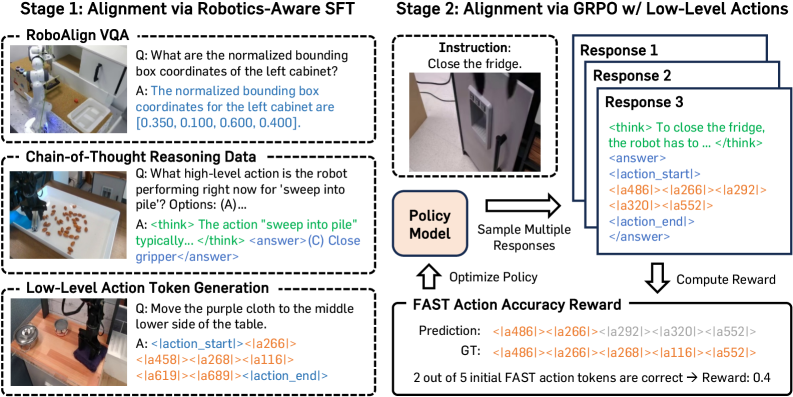
- RoboAlign framework: A two-stage pipeline.
- Stage 1 (SFT) : MLLM is fine-tuned to generate
FAST tokensvia zero-shot reasoning. Uses a mixture of datasets: open-source SFT datasets, custom RoboAlign VQA, specialized reasoning datasets, and robotic datasets withFAST tokens. Thereasoning dataset with zero-shot CoTis critical here to transfer reasoning ability toFAST tokengeneration (Table 1). - Stage 2 (RL) : Refines reasoning using
GRPOto improveFAST tokenprediction accuracy. Reward function considersformat rewardandaccuracy reward(Equation 2).
- Stage 1 (SFT) : MLLM is fine-tuned to generate
- Key Results :
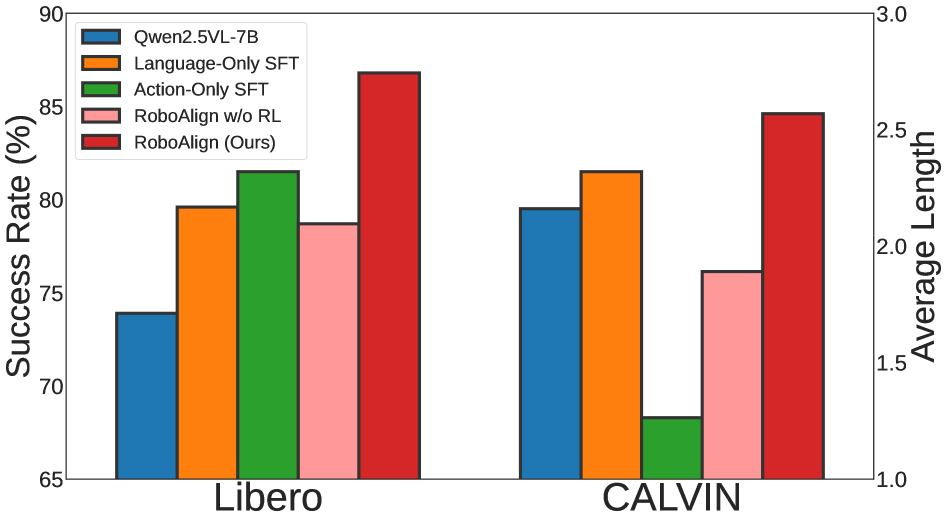
- Achieves performance improvements over SFT baselines: 17.5% on
LIBERO, 18.9% onCALVIN, and 106.6% in real-world environments with less than 1% additional data for RL (Abstract). - Specifically,
RoboAlignsignificantly improvesLongandGoalcategories inLIBERO(Table 2),task completions of length 4 and 5inCALVIN(Table 3), and real-world tasks (Table 4). - Outperforms other alignment approaches (language-based RL, visual-based RL) in
LIBERO(Table 6). - Outperforms SFT-based alignment (
ECoT) which degrades performance (Table 7). - Improves MLLM internal representations, increasing
KNN accuracyfrom 39.06% to 69.79% (Table 8). - Achieves
state-of-the-artperformance on embodied reasoning tasks in MLLM benchmarks (e.g.,Robot-R1 Bench,RoboSpatial,Where2Place,BLINK) while preserving general image understanding (Table 9).
- Achieves performance improvements over SFT baselines: 17.5% on
- RoboAlign framework: A two-stage pipeline.
- Conclusion & Impact :
RoboAligneffectively aligns MLLMs with low-level action policies using RL for improved embodied reasoning.- Delivers substantial gains in both VLA performance (short and long horizon tasks) and MLLM embodied reasoning capabilities.
- Contrasts with language-only fine-tuning which yields limited or degraded performance on complex scenarios.
- Impact: A generalizable approach for VLA training, but highlights the importance of safe action trajectories during alignment to prevent biased or unsafe actions in VLAs.
Part 2: Important Figures (JSON)
I need to identify up to 3 most important figures/tables and extract their image_url and provide caption_kr.
- Figure 1 : Performance on LIBERO - shows the problem.
- Figure 2 : Overview of RoboAlign framework - main architecture.
- Figure 3 : Examples of observations - shows different environments.
- Table 2 : LIBERO success rates - key quantitative results.
- Table 3 : CALVIN success rates - key quantitative results.
- Figure 4 : Summary of VLA performance - visual summary of main results.
I think Figure 2 (architecture) is essential. Then, either Figure 4 or a combination of Tables 2 and 3 for results. Figure 4 summarizes the results visually, which is good. Table 2 and 3 provide the detailed numbers. I'll pick Figure 2, Figure 4, and perhaps Table 2 or 3 for detailed numbers or Figure 1 for motivation if I need a third.
Let's pick:
- Figure 2 : Overview of RoboAlign framework. (
2603.21341v1/x2.png) - Figure 4 : Summary of VLA performance. (
2603.21341v1/x5.png) - Figure 1 : Performance on LIBERO (shows the problem being solved). (
2603.21341v1/x1.png)
I need to get the exact URLs for these images.
- Figure 1:
2603.21341v1/x1.png->https://arxiv.org/html/2603.21341v1/x1.png - Figure 2:
2603.21341v1/x2.png->https://arxiv.org/html/2603.21341v1/x2.png - Figure 4:
2603.21341v1/x5.png->https://arxiv.org/html/2603.21341v1/x5.png
Now I will construct the summary and the JSON output. 저자: Dongyoung Kim, Sumin Park, Woomin Song, Seungku Kim, Taeyoung Kim, Huiwon Jang, Jinwoo Shin, Jaehyung Kim, Younggyo Seo
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLA (Vision-Language-Action Models) : 시각 정보, 언어 이해, 그리고 로봇의 저수준(low-level) 동작 제어를 통합하여 실제 환경에서 로봇 정책을 학습하는 모델입니다.
- MLLM (Multimodal-Large-Language Models) : 다양한 양식(modality)의 데이터를 이해하고 처리하는 대규모 언어 모델로, 시각 정보와 언어적 지식을 통합하여 복잡한 추론을 수행합니다.
- FAST tokenization : 로봇의 저수준 동작(end-effector의 Cartesian position, orientation, gripper state 등)을 이산적인 토큰 시퀀스로 변환하는 기법으로, MLLM이 직접 동작을 예측할 수 있도록 합니다. 이 토큰화는 DCT (Discrete Cosine Transform) 및 BPE (Byte-Pair Encoding)를 사용하여 이루어집니다.
- GRPO (Group Relative Policy Optimization) : 명시적인 추론(explicit reasoning)을 장려하기 위해 설계된 강화 학습(Reinforcement Learning) 알고리즘으로, 정책을 형식 정확도(format correctness)와 답변 정확도(answer accuracy)에 대해 공동으로 최적화합니다.
- Embodied Reasoning : 로봇이 물리적 환경과 상호작용하며 필요한 공간적(spatial) 및 시간적(temporal) 추론 능력을 의미합니다. 이는 로봇 조작 작업에서 필수적입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 VLA는 로봇 공학 분야에서 두드러진 성과를 보이며, MLLM의 시각 인지, 언어 이해 및 상식 지식을 활용하여 실제 시나리오에서 일반화 가능한 로봇 정책 학습의 기반을 제공합니다. 그러나 VLA의 성능과 일반화는 근본적인 MLLM에 의해 제한되는 경우가 많으며, MLLM은 동작 생성에 필요한 핵심 Embodied Reasoning (예: spatial reasoning, temporal reasoning) 작업에서 어려움을 겪습니다.
기존 연구들은 vision-question-answering (VQA) 유형의 감독(supervision)을 통해 MLLM의 Embodied Reasoning 능력을 향상시키려 했지만, 이는 VLA 성능에 불확실한 결과를 초래하여 종종 미미하거나 심지어 부정적인 개선을 가져오는 것으로 보고되었습니다. 저자들은 이러한 불일치가 언어와 저수준 동작 간의 modality gap 때문이라고 지적합니다. 즉, 언어 감독을 통해 Embodied Reasoning을 최적화하는 것이 실제 동작 생성의 개선을 보장하지 않습니다. 실제로, Embodied Reasoning에 특화된 MLLM을 기반으로 구축된 VLA는 성능 향상이 미미하거나 오히려 저하되는 경향을 보였습니다 [Figure 1, cite: 1]. 특히, 가장 높은 추론 점수를 달성한 RoboBrain 2.0조차 가장 낮은 VLA 성능을 보였습니다 [Figure 1, cite: 1]. 이 연구는 이러한 modality gap을 해소하고 VLA 성능을 안정적으로 향상시킬 수 있는 MLLM 훈련 프레임워크의 필요성에서 출발합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 VLA 성능을 안정적으로 향상시키기 위한 MLLM 훈련 프레임워크인 RoboAlign 을 제안합니다. RoboAlign의 핵심 아이디어는 zero-shot natural language reasoning을 통해 low-level action tokens를 샘플링하고, action accuracy를 개선하기 위해 Reinforcement Learning (RL)을 사용하여 이 추론을 정제하는 것입니다. 이를 통해 RoboAlign은 MLLM에서 언어와 low-level actions 간의 modality gap을 연결하고 MLLM에서 VLA로의 지식 전이(knowledge transfer)를 촉진합니다.
RoboAlign은 두 단계의 훈련 파이프라인으로 구성됩니다 [Figure 2, cite: 1].
(i) Stage 1: Integrating Low-level Action with MLLM using SFT : Supervised Fine-tuning (SFT)를 적용하여 MLLM이 zero-shot reasoning을 통해 FAST tokens를 예측하는 초기 능력을 갖추도록 합니다. 이 단계에서는 RoboAlign VQA, reasoning dataset with zero-shot CoT, FAST token generation dataset 등 다양한 데이터셋을 혼합하여 사용합니다. 특히, zero-shot CoT를 포함한 추론 데이터셋은 FAST token 생성 과정으로 추론 능력을 효과적으로 전이시킵니다 [Table 1, cite: 1].
(ii) Stage 2: Aligning Embodied Reasoning with Low-level Action via RL : SFT를 통해 초기 능력을 갖춘 모델에 RL을 적용하여 Embodied Reasoning을 더욱 강화하고 FAST token 예측 정확도를 향상시킵니다. 이 단계에서는 GRPO를 사용하여 action-accuracy reward를 최대화함으로써 추론 과정을 정제합니다. reward는 형식 reward ($r_f$)와 정확도 reward ($r_a$)의 산술 평균으로 정의되며, $r_a$는 생성된 action token sequence와 목표 sequence 간의 prefix similarity를 측정하여 계산됩니다.
실험 결과, RoboAlign은 주요 로봇 공학 벤치마크에서 SFT baselines 대비 상당한 성능 향상을 달성했습니다 [Figure 4, cite: 1]. RL-based alignment 단계에서 SFT 데이터의 1% 미만 의 추가 데이터를 사용했음에도 불구하고, LIBERO에서 17.5% , CALVIN에서 18.9% , 실제 환경에서 106.6% 의 성능 향상을 기록했습니다. 특히 RoboAlign은 LIBERO 벤치마크의 Long 및 Goal 카테고리에서 다른 훈련 방법론 대비 현저한 개선을 보였습니다 [Table 2, cite: 1]. CALVIN 벤치마크에서는 task completions of length-5에서 다른 모든 방법이 성능 하락을 보이는 반면, RoboAlign은 22.2% 로 가장 높은 달성률을 기록했습니다 [Table 3, cite: 1]. 또한 RoboAlign은 실제 로봇 환경에서도 일관된 성능 향상을 입증했습니다 [Table 4, cite: 1]. representation analysis를 통해, RoboAlign (SFT+RL)이 baselines 대비 훨씬 더 판별적인 representation을 생성하며, KNN accuracy를 39.06% 에서 69.79% 로 향상시키는 것을 확인했습니다 [Table 8, cite: 1]. 이는 RL alignment 단계가 모델의 미세한 상태 정보를 인코딩하는 능력을 크게 향상시킨다는 것을 시사합니다.
4. Conclusion & Impact (결론 및 시사점)
저자들은 low-level action policies와 MLLM의 representation을 직접적으로 정렬함으로써 VLA에 최적화된 MLLM 훈련 프레임워크인 RoboAlign을 제안했습니다. 이 방법론은 Embodied Reasoning을 통해 low-level action prediction accuracy를 향상시키기 위해 Reinforcement Learning을 활용합니다. RoboAlign은 다양한 로봇 환경과 MLLM 벤치마크에 걸쳐 평가되었으며, 단기 및 장기 horizon tasks 모두에서 MLLM 작업 내의 Embodied Reasoning 성능과 VLA 도메인에서 실질적인 이득을 지속적으로 제공함을 입증했습니다.
대조적으로, 언어만 사용하는 embodied reasoning fine-tuning은 복잡한 시나리오에서 제한적이거나 심지어 성능을 저하시키는 결과를 가져왔습니다. 이러한 결과는 RoboAlign이 VLA 훈련 발전을 위한 효과적이고 일반화 가능한 접근 방식임을 확립합니다. 이 연구는 MLLM이 특정 동작 데이터와 정렬되는 훈련 프레임워크를 제안하지만, 모델이 안전하지 않은 동작 궤적(action trajectories)과 정렬될 경우, 해당 MLLM을 사용하여 훈련된 VLA는 안전하지 않은 동작을 생성하도록 편향될 수 있다는 점을 지적합니다. 따라서 배포 후 MLLM이 어떤 데이터로 훈련되었는지 정확히 판단하기 어렵기 때문에 훈련 단계에서 이러한 문제를 선제적으로 고려하고 예방하는 것이 중요합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] π_RL: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
- [논문리뷰] π-StepNFT: Wider Space Needs Finer Steps in Online RL for Flow-based VLAs
- [논문리뷰] X-Coder: Advancing Competitive Programming with Fully Synthetic Tasks, Solutions, and Tests
- [논문리뷰] Monet: Reasoning in Latent Visual Space Beyond Images and Language
- [논문리뷰] Thinking-while-Generating: Interleaving Textual Reasoning throughout Visual Generation
Review 의 다른글
- 이전글 [논문리뷰] Repurposing Geometric Foundation Models for Multi-view Diffusion
- 현재글 : [논문리뷰] RoboAlign: Learning Test-Time Reasoning for Language-Action Alignment in Vision-Language-Action Models
- 다음글 [논문리뷰] SEM: Sparse Embedding Modulation for Post-Hoc Debiasing of Vision-Language Models
댓글