[논문리뷰] SEM: Sparse Embedding Modulation for Post-Hoc Debiasing of Vision-Language Models
링크: 논문 PDF로 바로 열기
The paper "SEM: Sparse Embedding Modulation for Post-Hoc Debiasing of Vision-Language Models" by Quentin Guimard, Federico Bartsch, Simone Caldarella, Rahaf Aljundi, Elisa Ricci, and Massimiliano Mancini proposes a new method for debiasing Vision-Language Models (VLMs) like CLIP.
I've read the paper and will now proceed with the summary following the given constraints.
Part 1: 요약 본문
메타데이터
저자: Quentin Guimard, Federico Bartsch, Simone Caldarella, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Vision-Language Models (VLMs) : 이미지와 텍스트 간의 관계를 학습하여 두 modalities를 연결하는 모델. CLIP과 같은 모델이 대표적이며, cross-modal retrieval 및 classification과 같은 downstream task에 활용된다.
- Sparse Autoencoder (SAE) : 고차원의 sparse latent vector로부터 모델의 dense embedding을 재구성하도록 훈련된 neural network. 이는 dense하고 entangled된 embedding을 sparse한 특징 집합으로 분해하여 개별 feature의 식별 및 targeted modulation을 가능하게 한다.
- Post-Hoc Debiasing : VLM을 재학습시키거나 fine-tuning하는 대신, 이미 학습된 모델의 embedding space를 조작하여 bias를 완화하는 방법론. 이 연구에서는 text embedding에 대한 post-hoc intervention에 초점을 맞춘다.
- Disentanglement Score (D) : 개념 간의 얽힘(entanglement) 정도를 정량화하는 지표. 이 연구에서는 profession probe가 bias를 capture하는 능력을 측정하여 얽힘을 평가하며, 1에 가까울수록 완벽한 disentanglement를 의미한다.
- Worst-Group Accuracy (WG Accuracy) : 특정 bias subgroup (예: 성별, 인종)에서 모델의 성능을 측정하는 fairness metric. 기존 debiasing 방법들이 종종 이 지표에서 개선을 보이지 못하는 한계가 있었다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
CLIP과 같은 Vision-Language Models (VLMs)는 multimodal AI의 핵심 구성 요소이지만, 대규모의 uncurated training data로 인해 심각한 social 및 spurious bias가 내재되어 있다. 이러한 bias는 모델이 'doctor'를 'male'과, 'nurse'를 'female'과 연관시키거나, 특정 인종을 'criminal' 또는 'thief'와 연결하는 등의 문제로 이어진다. 또한, 모델이 특정 context에 과도하게 의존하여 존재하지 않는 객체를 "hallucinate"하는 경우도 발생한다.
기존의 post-hoc debiasing 방법들은 주로 dense CLIP embedding space에서 직접 작동하는데, 이 공간에서는 bias 정보와 task-relevant 정보가 고도로 entangled 되어 있다. 이러한 entanglement는 bias를 제거하면서도 semantic fidelity를 저하시키지 않는 능력을 제한한다. 특히, 기존 zero-shot 방법들은 단일 bias subspace를 식별하고 orthogonal projection을 통해 제거하지만, 이는 복잡한 bias를 선형적으로 모델링하려는 과도한 단순화이며, bias와 content를 disentangle하는 데 실패한다. 결과적으로 이러한 방법들은 worst-group accuracy 개선에 어려움을 겪고 일관성 없는 fairness gain을 보인다.

은 이러한 dense CLIP-space debiasing의 한계를 보여준다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
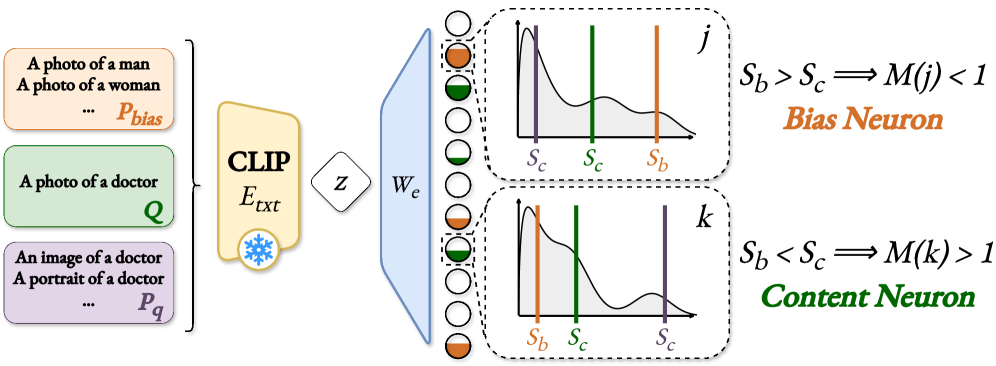
저자들은 Vision-Language Models의 post-hoc debiasing을 위한 Sparse Embedding Modulation (SEM) 이라는 새로운 zero-shot 프레임워크를 제안한다. SEM은 CLIP text embeddings를 Sparse Autoencoder (SAE) latent space로 투영하여 disentangled feature로 분해한 후 작동한다 [cite: 1, Figure 1]. 이 sparse latent space는 기존 dense embedding보다 훨씬 더 disentangled되어 있어, 개념들을 개별 feature로 분리한다 [cite: 1, Figure 2]. 이는 기존의 단일 subspace projection을 넘어, feature 수준에서 정확하고 non-linear한 개입을 가능하게 한다.
SEM 프레임워크는 두 가지 주요 단계로 구성된다 [cite: 1, Figure 3]. 첫째, Scoring 단계에서는 SAE latent space의 neuron들이 content relevance 와 bias sensitivity 에 따라 점수를 매겨진다 [cite: 1, Figure 3]. Content relevance는 query의 latent representation과 diverse neutral prompt set의 활성화를 비교하여 Sconcept(j)로 측정되며, LLM으로 생성된 paraphrases를 활용하여 더욱 robust한 추정치를 얻을 수 있다. Bias sensitivity는 bias prompt set (𝒫bias)을 사용하여 각 bias class (c)에 대한 bias signature (mc)를 정의하고, 일반적인 활성화 (Sgenc)와 특정 bias class에 대한 활성화 (Sspecc)를 모두 고려하여 Sbias(j)를 계산한다.
둘째, Steering 단계에서는 이 점수들을 결합하여 각 neuron의 최종 modulation coefficient (M) 를 생성한다 [cite: 1, Figure 3]. M은 content-relevant neuron을 증폭시키고 bias-specific neuron을 감쇠시키도록 설계된다. SEM은 사용 가능한 정보 수준에 따라 세 가지 변형으로 제공된다:
- SEM_i_ (Bias-Agnostic) : Sconcept(j)만을 사용하여 low-relevance feature를 감쇠시킨다.
- SEM_b_ (Bias-Aware) : Sconcept(j)와 Sbias(j)를 모두 사용하여 content-boosting 및 bias-attenuation을 수행한다.
- SEM_bi_ (Full) : 두 가지 접근 방식을 결합한다.
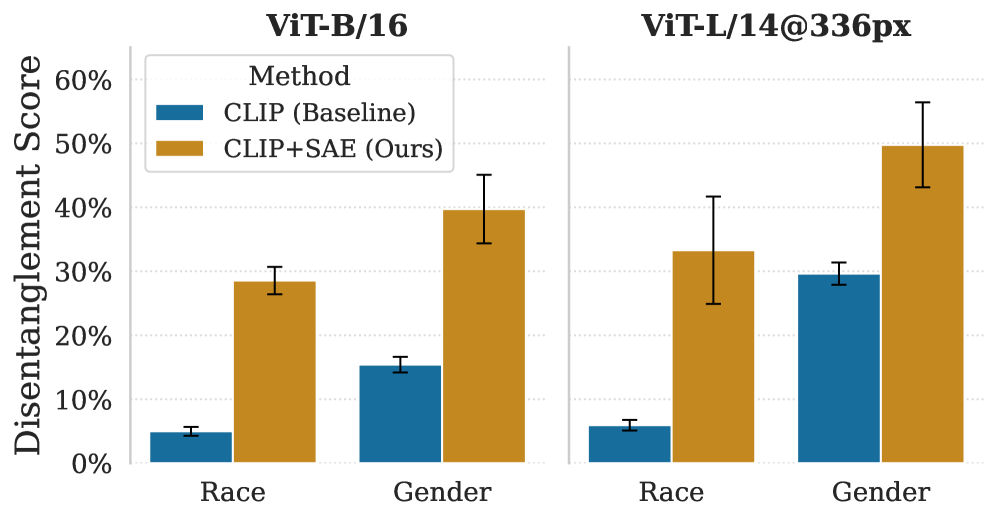
제안된 방법론은 네 가지 벤치마크 데이터셋 (FairFace, UTKFace, CelebA, Waterbirds)과 두 가지 CLIP backbone (ViT-B/16, ViT-L/14@336px)에서 평가되었다. 실험 결과, SEM은 retrieval 및 zero-shot classification에서 상당한 fairness gain을 달성한다. 특히, worst-group accuracy 를 크게 개선하여 기존 방법론들이 부족했던 subgroup level에서의 fairness-performance trade-off 문제를 해결한다. 예를 들어, [Table 2]에서 SEM_i_는 FairFace Race (ViT-B/16)에서 Base CLIP 대비 KL Divergence를 0.237에서 0.170으로 감소시켰고, SEM_b_는 UTKFace Gender (ViT-B/16)에서 KL Divergence를 0.134에서 0.124로 감소시켰다. 정성적 분석에서도
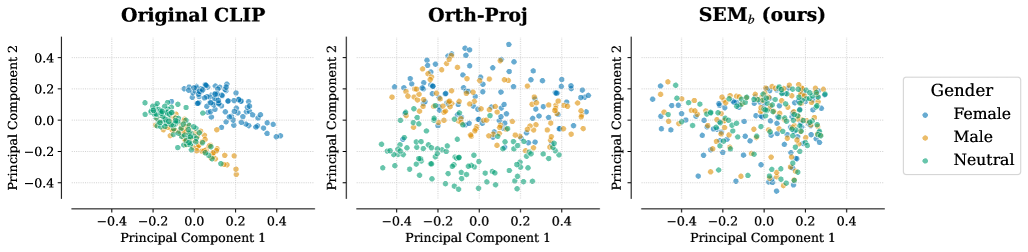
는 Orth-Proj가 neutral cluster를 제대로 병합하지 못하는 반면, SEM_b_는 'male', 'female', 'neutral' 세 클러스터를 응집력 있는 분포로 성공적으로 병합하여 underlying profession이 더 잘 보존됨을 보여준다. [Table 1]의 정량적 분석에서는 Orth-Proj가 Content Preservation에서 0.415 로 심각한 성능 저하를 보이는 반면, SEM_b_는 0.878 의 높은 Content Preservation을 유지하면서 Bias Neutralization에서 0.974 를 달성했다. 이는 Orth-Proj의 0.916 보다 높은 수치이다.
또한, SEM은 다른 debiasing 방법론들과 상호보완적임을 입증했다. BendVLM과 SEM을 결합한 BendSEM_bi_ 는 기존 BendVLM 단독 성능 대비 Retrieval Precision을 9.5% 향상시키는 결과를 보였다. ResNet backbone에 대한 확장 실험에서도 SEM은 일관되게 강력한 fairness mitigation 성능을 보이며, Waterbirds (ResNet-50)에서 SEM_b_는 Worst-Group Accuracy를 0.394에서 0.577로 증가시켰다.
## 4. Conclusion & Impact (결론 및 시사점)
본 연구는 Sparse Autoencoder (SAE)의 sparse latent representation을 활용하여 Vision-Language Models (VLMs)의 post-hoc debiasing을 위한 Sparse Embedding Modulation (SEM) 프레임워크를 성공적으로 제안했다. SEM은 CLIP text embedding을 disentangled feature로 분해하고, bias-relevant neuron을 정밀하게 modulate함으로써 semantic fidelity를 유지하면서도 효과적으로 bias를 완화한다. 이는 기존의 dense embedding space에서 작동하는 debiasing 방법들이 겪던 bias-content entanglement 문제를 해결한다.
이 연구는 해당 분야에 중요한 영향을 미친다. 첫째, sparse latent representation이 VLM의 post-hoc debiasing을 위한 효과적인 기반을 제공한다는 것을 입증했다. 둘째, SEM의 세 가지 변형 (SEM_i_, SEM_b_, SEM_bi_)은 다양한 정보 가용성 시나리오에 대한 유연한 솔루션을 제공하며, 다른 debiasing 방법들과 결합하여 성능을 더욱 향상시킬 수 있는 modularity를 보여준다. 셋째, 기존 zero-shot 방법의 주요 한계점이었던 worst-group accuracy를 크게 개선함으로써, 실제 애플리케이션에서 모델의 reliability와 fairness를 향상시키는 데 기여한다. 이를 통해, 사회적 편향과 spurious correlation으로 인한 VLM의 실패를 줄이고, 더욱 공정하고 신뢰할 수 있는 multimodal AI 시스템 구축에 중요한 진전을 가져올 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Think, Act, Build: An Agentic Framework with Vision Language Models for Zero-Shot 3D Visual Grounding
- [논문리뷰] Large Multimodal Models as General In-Context Classifiers
- [논문리뷰] Half-Truths Break Similarity-Based Retrieval
- [논문리뷰] Compositional Generalization Requires Linear, Orthogonal Representations in Vision Embedding Models
- [논문리뷰] ProCLIP: Progressive Vision-Language Alignment via LLM-based Embedder
Review 의 다른글
- 이전글 [논문리뷰] RoboAlign: Learning Test-Time Reasoning for Language-Action Alignment in Vision-Language-Action Models
- 현재글 : [논문리뷰] SEM: Sparse Embedding Modulation for Post-Hoc Debiasing of Vision-Language Models
- 다음글 [논문리뷰] Scaling DoRA: High-Rank Adaptation via Factored Norms and Fused Kernels
댓글