[논문리뷰] Scaling DoRA: High-Rank Adaptation via Factored Norms and Fused Kernels
링크: 논문 PDF로 바로 열기
The paper details "Scaling DoRA: High-Rank Adaptation via Factored Norms and Fused Kernels." It addresses the memory and speed inefficiencies of DoRA (Weight-Decomposed Low-Rank Adaptation) at high ranks, specifically the row-wise norm computation and the composition step.
I need to extract the following:
- Authors : Alexandra Zelenin, Alexandra Zhuravlyova
- Keywords : I will derive these from the abstract and introduction, focusing on technical terms.
DoRA,Low-Rank Adaptation,Parameter-Efficient Fine-Tuning,Fused Kernels,Memory Optimization,Performance Scaling,Triton. - Key Terms & Definitions :
DoRA,Factored Norm,Fused Triton Kernels,bf16,VRAM. - Motivation : High-rank DoRA is costly due to the dense
BAproduct materialization for norm computation, causing high VRAM usage and speed degradation. - Methodology :
- Factored Norm : Decomposes the squared norm into base, cross, and Gram terms, computed with
O(d_out*r + r^2)intermediates, avoiding denseBAproduct. - Fused Triton Kernels : Collapse the four-kernel DoRA composition into a single pass, reducing memory traffic by ~4x and using a numerically stable form.
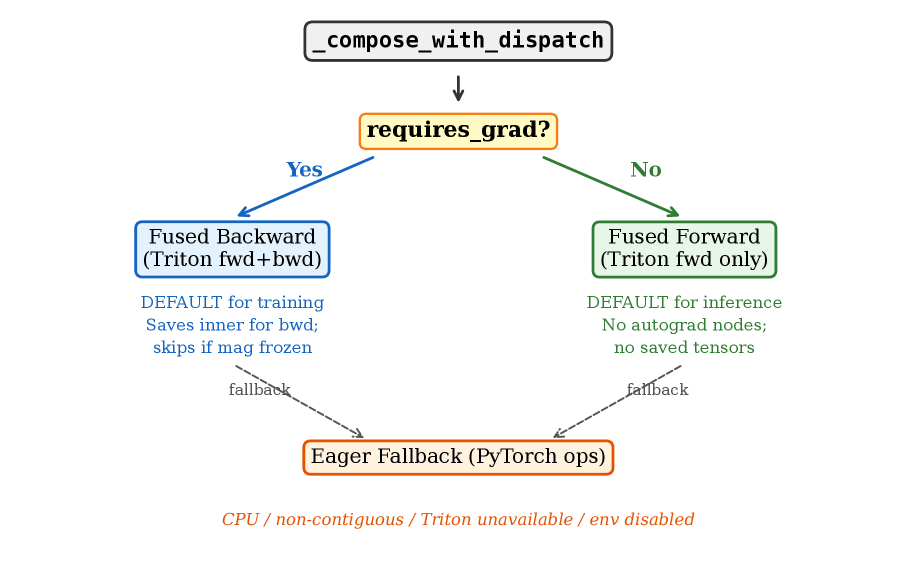
- Runtime Dispatch : A three-tier system to select optimal paths (fused backward for training, fused forward for inference, eager fallback).
- Factored Norm : Decomposes the squared norm into base, cross, and Gram terms, computed with
- Key Results :
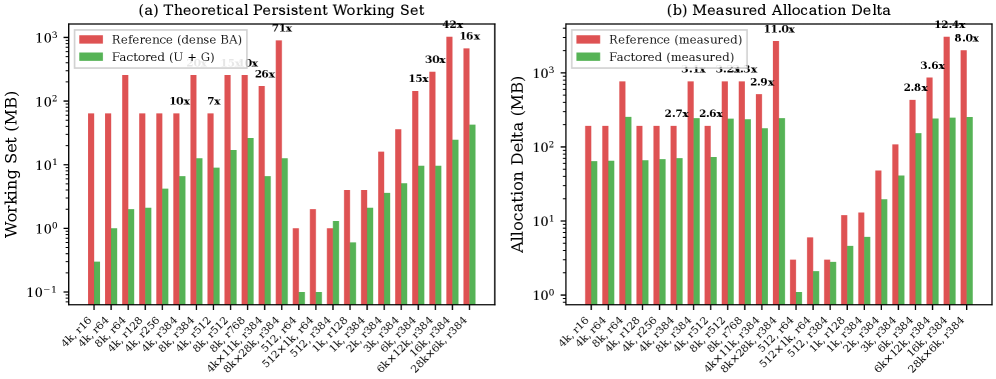
- Factored norm reduces rank-dependent persistent memory by 15x (theoretical) at
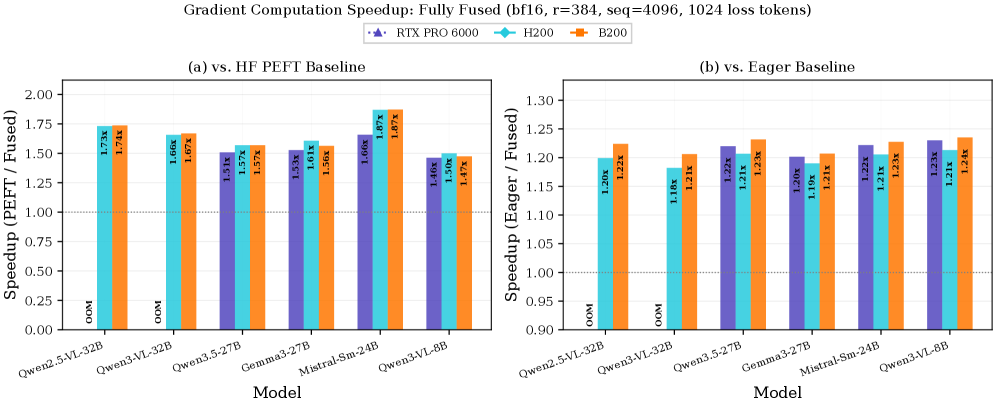
d=8192, r=512, fp32. - Fused implementation is 1.5-2.0x faster for inference, and 1.5-1.9x faster for gradient computation compared to HF PEFT's DoRA.
- Up to 7GB lower peak VRAM.
- Compose kernel speedup: 1.5-2.7x (geometric mean).
- Final-logit cosine similarity > 0.9999 .
- Training curves match within 7.1e-4 mean per-step loss delta.
- Factored norm reduces rank-dependent persistent memory by 15x (theoretical) at
- Conclusion & Impact : The proposed systems contributions significantly improve the efficiency of high-rank DoRA, making it more feasible for large models and resource-constrained environments without compromising numerical fidelity or convergence.
Figure Selection for Part 2 :
- Figure 2: Three-tier dispatch : Shows the overall system architecture for runtime dispatch. This is important for understanding how the different components are integrated.
2603.22276v1/x2.png - Figure 3: Gradient-computation speedup : Presents key quantitative results, showing the performance gain over baselines.
2603.22276v1/x3.png - Figure 9: Norm memory reduction : Illustrates the memory efficiency benefits of the factored norm.
2603.22276v1/x9.png
Now I will structure the response according to the specified format. 저자: Alexandra Zelenin, Alexandra Zhuravlyova
1. Key Terms & Definitions (핵심 용어 및 정의)
- DoRA (Weight-Decomposed Low-Rank Adaptation) : LoRA를 확장하여 weight magnitude와 direction을 분리하는 Parameter-Efficient Fine-Tuning (PEFT) 기법입니다.
- Factored Norm : DoRA의 핵심 병목인 row-wise norm 계산을 base, cross, Gram terms로 대수적으로 분해하여
O(d_out*r + r^2)intermediates를 통해 dense productBA의 materialization 없이 계산하는 방법론입니다. - Fused Triton Kernels : DoRA의 composition (g-1)⊙base + g⊙s⊙lora 연산을 여러 CUDA kernel launch 대신 단일 GPU pass로 통합하여 memory traffic을 최적화하는 사용자 정의 커널입니다.
- bf16 (bfloat16) : 모델 학습 및 추론에 사용되는 16비트 부동 소수점 형식으로, fp32 대비 메모리 사용량을 줄이고 연산 속도를 높일 수 있지만, 정밀도 손실의 가능성이 있습니다.
- VRAM (Video Random Access Memory) : GPU에 탑재된 전용 메모리로, 대규모 모델 학습 시 모델 파라미터와 중간 활성화 값을 저장하는 데 필수적이며, 그 용량이 성능에 큰 영향을 미칩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 Weight-Decomposed Low-Rank Adaptation (DoRA) 구현은 특히 high-rank 설정에서 심각한 메모리 및 성능 병목 현상을 겪습니다. 주요 문제는 DoRA의 forward pass에서 요구되는 ‖W + sBA‖_row와 같은 row-wise norm 계산이 대부분의 프레임워크에서 dense [d_out, d_in] product인 BA를 materialize함으로써 이루어진다는 점입니다. 예를 들어, d_in=8192, r=384인 단일 모듈의 norm 계산은 bf16 에서 약 512MB 의 transient working memory를 필요로 하며, 이는 수백 개의 adapted module과 gradient checkpointing이 포함될 경우 일반적인 single-GPU 환경에서 high-rank DoRA를 비실용적이거나 불가능하게 만듭니다. 기존 연구(Baseline)는 torch.eye를 사용하여 d_in x d_in identity matrix를 생성하고 BA를 materialize하는데, 이는 O(d_in^2)의 메모리 비용을 발생시킵니다. 이러한 누적 메모리 압력은 속도 저하와 Out-of-Memory (OOM) 오류의 주요 원인이 됩니다. 저자들은 이러한 기존 방식의 한계를 극복하고 DoRA의 스케일링을 가능하게 하는 시스템 최적화의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 DoRA의 메모리 효율성과 연산 속도를 향상시키기 위해 두 가지 주요 시스템 최적화를 제안합니다. 첫째, factored norm 계산 방법론은 ‖W + sBA‖_row^2를 base, cross, Gram의 세 가지 항으로 대수적으로 분해합니다. 각 항은 O(d_out*r + r^2)의 중간값만으로 평가될 수 있어, 기존 방식에서 큰 오버헤드를 유발했던 dense BA product의 materialization을 제거합니다. 특히, d=8192, r=512, fp32 환경에서 이론적인 persistent memory 감소는 15배 에 달합니다. 둘째, fused Triton kernels 는 기존 PyTorch에서 네 번의 CUDA kernel launch가 필요했던 DoRA composition (g-1)⊙base + g⊙s⊙lora를 단일 GPU pass로 통합합니다. 이는 memory traffic을 약 4배 감소시키고, g≈1인 near-unity rescaling regime에서 치명적인 cancellation을 피하는 numerically stable form을 사용합니다. 이 과정에서 fp32 중간 연산을 통해 정밀도 이점을 확보합니다 [cite: 1, Figure 1].
실험 결과는 제안된 방법론의 효과를 명확히 보여줍니다. bf16 환경에서 6개 의 8-32B Vision-Language Models (VLMs)과 3개 의 NVIDIA GPU (RTX 6000 PRO, H200, B200)에 걸쳐, fused implementation은 HF PEFT의 DoRA 구현 대비 추론에서 1.5-2.0배 더 빠르고, gradient computation에서는 1.5-1.9배 더 빠릅니다 [cite: 1, Figure 3, Figure 4]. 또한, 최대 7GB 낮은 peak VRAM을 달성했습니다 [cite: 1, Table 8]. Compose kernel microbenchmark에서는 1.5-2.7배 의 속도 향상(geometric mean)을 보였으며 [cite: 1, Figure 6], 이는 reduced memory traffic 덕분임을 bandwidth utilization이 50%를 초과하는 결과로 입증합니다 [cite: 1, Figure 7]. Norm memory reduction은 8192x28672 MoE shape에서 11배 의 측정된 감소를 보여주었습니다 [cite: 1, Figure 9]. 최종 logit의 cosine similarity는 모든 모델/GPU 쌍에서 0.9999 를 초과했으며, multi-seed training curves는 2000 steps 동안 7.1e-4 의 평균 per-step loss delta 내에서 일치하여 numerical fidelity와 convergence equivalence를 확인했습니다 [cite: 1, Table 10].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 DoRA의 시스템 구현 개선을 통해 high-rank 적용 시 발생하는 메모리 및 성능 문제를 효과적으로 해결했습니다. Factored norm 계산 방식은 DoRA의 working memory를 O(d_out*d_in)에서 O(d_out*r + r^2)로 줄여, 특히 대규모 d_in에서 dense BA product materialization으로 인한 오버헤드를 제거합니다. Fused Triton kernels 는 DoRA composition의 여러 GPU 연산을 단일 패스로 통합하여 memory traffic을 크게 감소시키고, numerical stability를 보장합니다.
이 연구는 학계 및 산업계에 중요한 시사점을 제공합니다. 첫째, DoRA와 같은 Parameter-Efficient Fine-Tuning (PEFT) 방법론의 high-rank 스케일링을 가능하게 하여, Large Language Models (LLMs) 및 Vision-Language Models (VLMs)의 fine-tuning 시 full fine-tuning에 근접하는 성능을 보다 효율적인 자원(특히 GPU VRAM)으로 달성할 수 있게 합니다. 둘째, training과 inference가 GPU 메모리를 공유하는 co-located deployment 환경에서 메모리 효율성을 극대화하여 실제 운용 시의 유용성을 높입니다. 셋째, 제안된 최적화는 numerical fidelity를 유지하면서 성능을 향상시키므로, 기존 모델의 재학습 없이도 DoRA의 효율적인 적용이 가능함을 보여줍니다. 이는 대규모 모델의 연구 및 개발, 그리고 실제 서비스 도입에 있어 중요한 기여를 할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] KVpop -- Key-Value Cache Compression with Predictive Online Pruning
- [논문리뷰] Program-as-Weights: A Programming Paradigm for Fuzzy Functions
- [논문리뷰] Flash-GMM: A Memory-Efficient Kernel for Scalable Soft Clustering
- [논문리뷰] Video2LoRA: Parametric Video Internalization for Vision-Language Models
- [논문리뷰] Meta-Cognitive Memory Policy Optimization for Long-Horizon LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] SEM: Sparse Embedding Modulation for Post-Hoc Debiasing of Vision-Language Models
- 현재글 : [논문리뷰] Scaling DoRA: High-Rank Adaptation via Factored Norms and Fused Kernels
- 다음글 [논문리뷰] SpatialBoost: Enhancing Visual Representation through Language-Guided Reasoning
댓글