[논문리뷰] SpatialBoost: Enhancing Visual Representation through Language-Guided Reasoning
링크: 논문 PDF로 바로 열기
The paper "SpatialBoost: Enhancing Visual Representation through Language-Guided Reasoning" proposes a framework to enhance the spatial awareness of pre-trained vision encoders.
Authors: Byungwoo Jeon, Dongyoung Kim, Huiwon Jang, Insoo Kim, Jinwoo Shin
Keywords: Vision Encoder, Spatial Reasoning, Language-Guided Learning, Multi-turn VQA, Dual-channel Attention, 3D Perception, Multi-modal LLM
1. Key Terms & Definitions (핵심 용어 및 정의)
- Vision Encoder : 이미지에서 의미 있는 특징을 추출하는 딥러닝 모델. 주로 2D 이미지 데이터로 학습되어 3D 공간 정보를 파악하는 데 한계가 있다.
- Large Language Model (LLM) : 대규모 텍스트 데이터로 학습되어 자연어 이해 및 생성 능력을 갖춘 모델. SpatialBoost에서는 시각적 공간 지식을 언어로 표현하고 이를 Vision Encoder에 주입하는 데 활용된다.
- Chain-of-Thought (CoT) Reasoning : 복잡한 추론 과정을 여러 단계의 중간 추론으로 분해하여 문제를 해결하는 방식. SpatialBoost에서는 Pixel-level, Object-level, Scene-level의 계층적 공간 이해를 구축하는 데 사용된다.
- Dual-channel Attention : 기존 Vision Encoder의 파라미터를 보존하면서 추가적인 학습 가능한 파라미터를 도입하여 공간 지식을 주입하는 메커니즘. 기존 지식의 'catastrophic forgetting'을 방지한다.
- Multi-turn Visual Spatial Reasoning Dataset : Pixel-level, Object-level, Scene-level의 계층적 QA 쌍으로 구성되어 Vision Encoder가 3D 공간 관계를 효과적으로 학습하도록 설계된 데이터셋이다
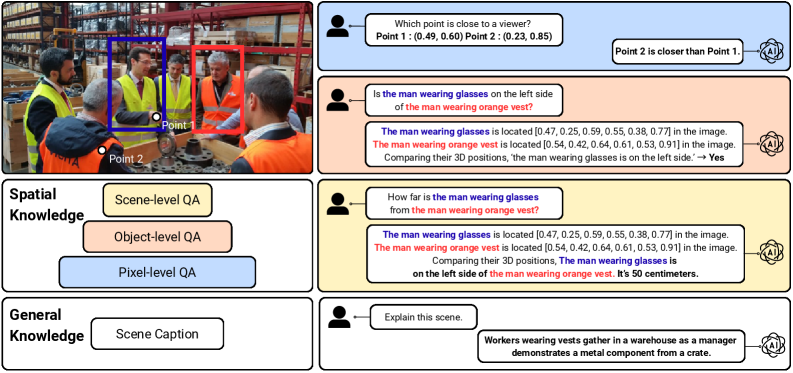
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 대규모 사전 학습된 이미지 표현 모델, 즉 Vision Encoder들은 다양한 비전 태스크에서 뛰어난 성능을 보였음에도 불구하고, 주로 2D 이미지 데이터로 학습되어 실제 세계의 객체와 배경 간의 3D 공간 관계를 제대로 포착하지 못하는 근본적인 한계가 있었다. 이는 모노큘러 깊이 예측, 시맨틱 분할, 3D 장면 이해, 로봇 제어 등 3D 공간 인식이 필수적인 많은 하위 태스크에서 Vision Encoder의 효과를 제한한다. 기존 연구들은 멀티-뷰 이미지 데이터를 활용하여 3D 정보를 학습하려 했으나, 이는 신중하게 큐레이션된 데이터나 시뮬레이션 환경에 대한 의존성으로 인해 확장성에 제약이 있었다. 이러한 문제점들을 해결하기 위해, 적은 데이터로도 3D 공간 정보를 효과적으로 학습할 수 있는 새로운 프레임워크의 필요성이 대두되었다. 저자들은 이러한 한계를 극복하고 Vision Encoder의 3D 공간 인식을 강화하는 것을 목표로 한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 언어-기반 추론을 활용하여 Vision Encoder의 공간 이해를 향상시키는 훈련 프레임워크인 SpatialBoost 를 제안한다
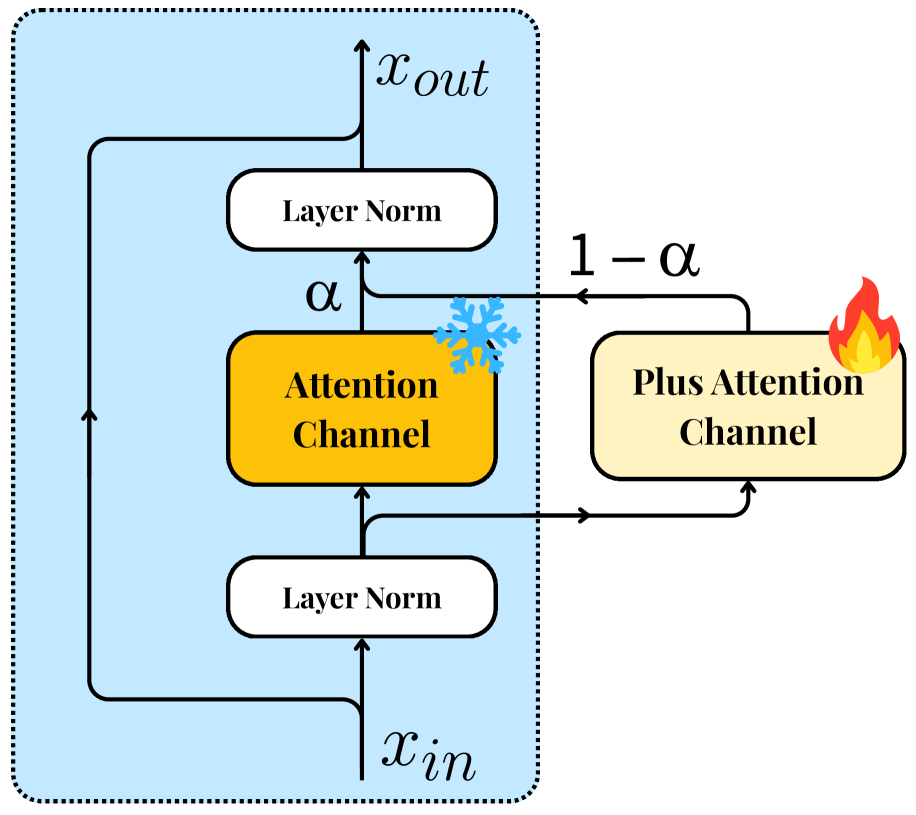
SpatialBoost는 3단계 훈련 파이프라인을 통해 구현된다. 첫째, Feature alignment 단계에서는 Vision Encoder의 시각적 특징을 LLM의 텍스트 임베딩 공간에 매핑하는 Projector를 훈련한다. 둘째, Visual instruction tuning 단계에서는 LLaVA와 Multi-view VQA 데이터를 활용하여 LLM과 Projector를 파인튜닝하여 멀티-뷰 시각 질문을 처리할 수 있도록 정렬한다. 셋째, Vision encoder fine-tuning with dual-channel attention 단계에서는 Vision Encoder에 Multi-turn Visual Spatial Reasoning Dataset을 주입하여 공간 이해 능력을 강화한다 [Figure 2, cite: 1]. 이 과정에서 기존 Vision Encoder의 사전 학습된 지식 손실(catastrophic forgetting)을 방지하기 위해 Dual-channel Attention 레이어를 도입하며, 이는 원본 Attention 블록과 추가 Attention 블록의 출력을 학습 가능한 혼합 계수(α)로 병합한다 [Figure 3, cite: 1]. 훈련 시에는 추가 Attention 블록과 혼합 계수만 업데이트된다.
실험 결과, SpatialBoost는 다양한 벤치마크에서 기존 SOTA Vision Encoder의 성능을 일관되게 향상시켰다. Monocular Depth Estimation 태스크에서 DINOv3는 NYUd 벤치마크에서 RMSE 스코어를 0.31에서 0.25 로 개선했으며. Semantic Segmentation 태스크에서 DINOv3는 ADE20K 벤치마크에서 mIoU를 55.9%에서 59.7% 로 향상시켜 SOTA 성능을 달성했다. 또한, 3D Scene Understanding 태스크 중 SQA3D에서 DINOv3는 51.4%에서 54.9% 로 BLEU-1 스코어가 증가했다. Vision-based Robot Learning 태스크에서는 DINOv3 + SpatialBoost가 CortexBench의 평균 성능을 72.8에서 80.8 로 크게 개선했다. Image Classification (ImageNet linear probing) 태스크에서도 DINOv3는 88.4%에서 90.2% 로 Top-1 Accuracy가 증가하여, SpatialBoost가 공간 이해뿐만 아니라 일반적인 비전 능력까지도 향상시킬 수 있음을 입증했다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 언어-기반 추론을 통해 Vision Encoder의 공간 이해를 강화하는 프레임워크인 SpatialBoost 를 성공적으로 제안했다. SpatialBoost는 LLM과 Dual-channel Attention을 활용하여 언어적 공간 지식을 이미지 표현에 효과적으로 주입하고, Multi-turn Visual Spatial Reasoning Dataset을 생성하여 Vision Encoder의 3D 공간 인식 능력을 향상시킨다. 광범위한 실험을 통해 SpatialBoost가 Monocular Depth Estimation, Semantic Segmentation, 3D Scene Understanding, Vision-based Robot Learning, Image Classification 및 Image Retrieval 등 다양한 하위 태스크에서 Vision Encoder의 성능을 일관되게 향상시키는 것을 입증했다. 이러한 결과는 Vision Encoder가 2D 이미지뿐만 아니라 3D 공간 정보를 더 깊이 이해할 수 있도록 하는 새로운 방향을 제시하며, 향후 Vision Encoder 설계 및 향상 연구에 중요한 기반을 제공할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Scaling DoRA: High-Rank Adaptation via Factored Norms and Fused Kernels
- 현재글 : [논문리뷰] SpatialBoost: Enhancing Visual Representation through Language-Guided Reasoning
- 다음글 [논문리뷰] Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
댓글