[논문리뷰] ShotVerse: Advancing Cinematic Camera Control for Text-Driven Multi-Shot Video Creation
링크: 논문 PDF로 바로 열기
저자: Songlin Yang, Zhe Wang, Xuyi Yang, et al.
키워: Cinematic Camera Control, Multi-Shot Video Generation, Text-Driven Video, Trajectory Planning, Vision-Language Models, Diffusion Transformers, ShotVerse-Bench
1. Key Terms & Definitions (핵심 용어 및 정의)
- ShotVerse : 제안된 "Plan-then-Control" 프레임워크로, VLM-기반 Planner와 Diffusion Transformer-기반 Controller를 활용하여 Cinematic Multi-Shot Video Creation을 수행합니다.
- ShotVerse-Bench : 저자들이 큐레이션한 고품질 시네마틱 데이터셋으로, 계층적 Caption과 Unified Multi-Shot Trajectory Annotation을 포함하며 ShotVerse 훈련 및 평가에 사용됩니다.
- Planner : ShotVerse 프레임워크 내에서 VLM(Vision-Language Model) 기반 Agent로, 하이레벨 텍스트 설명을 Explicit하고 Globally Aligned된 Cinematic Camera Trajectory로 변환하는 역할을 합니다.
- Controller : ShotVerse 프레임워크 내에서 Diffusion Transformer(DiT) 기반 Agent로, Planner가 생성한 Explicit Trajectory를 Camera Adapter와 4D Rotary Positional Embedding 전략을 사용하여 고품질 Multi-Shot Video 콘텐츠로 렌더링합니다.
- 4D Rotary Positional Embedding (4D RoPE) : ShotVerse에서 제안하는 Positional Embedding 전략으로, Multi-Shot Video의 계층적 Temporal Structure를 모델에 명시적으로 알려 Shot Boundary를 존중하고 Intra-Shot Consistency를 강화합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Text-driven Video Generation 모델들은 영화 제작의 민주화를 이끌었지만, Cinematic Multi-Shot Scenario에서의 Camera Control은 여전히 중요한 병목(Bottleneck)으로 남아 있습니다. Implicit Textual Prompt는 "pan left", "zoom in"과 같은 정밀한 카메라 지시를 따르기에 정확도가 부족하며, Multi-Shot Setting에서 카메라들이 Unified Global Coordinate System을 공유하여 Cinematic Pattern에 부합하는지 보장하기 어렵습니다. Explicit Trajectory를 통한 가이드가 효과적일 수 있지만, Cinematic Multi-Shot Trajectory를 수동으로 Plotting하는 것은 막대한 수작업 오버헤드를 유발하고, 현재 모델들은 복잡한 Cinematic Trajectory를 Out-of-Distribution 조건으로 취급하여 생성 실패로 이어지는 경향이 있습니다 [Figure 3].
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 문제를 해결하기 위해 데이터 중심 패러다임 전환과 함께 ShotVerse 라는 "Plan-then-Control" 프레임워크를 제안합니다. 이 프레임워크는 VLM-기반 Planner 와 Diffusion Transformer(DiT)-기반 Controller 라는 두 가지 협력 Agent로 생성 과정을 분리합니다
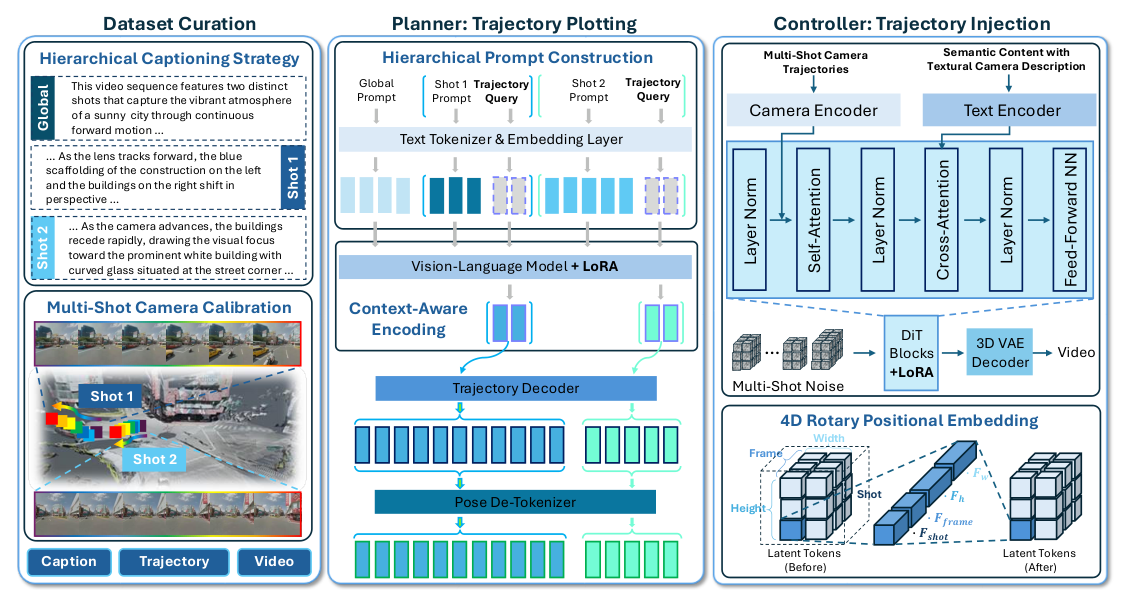 Figure 2: Method Overview of the ShotVerse framework, detailing Dataset Curation, Trajectory Plotting (Planner), and Trajectory Injection (Controller).
Figure 2: Method Overview of the ShotVerse framework, detailing Dataset Curation, Trajectory Plotting (Planner), and Trajectory Injection (Controller).
. Planner 는 계층적 텍스트 프롬프트를 입력받아 LoRA 를 통해 파인튜닝된 VLM을 사용하여 Explicit하고 Globally Unified된 Cinematic Trajectory를 생성하며, P(Trajectory | Caption)을 모델링합니다. Controller 는 HoloCine Backbone 위에 경량 Camera Adapter 와 Shot Boundary를 명시적으로 모델링하는 4D Rotary Positional Embedding 전략을 적용하여 P(Video | Caption, Trajectory)에 따라 고품질 Multi-Shot Video를 렌더링합니다. 이 모든 과정은 새로 큐레이션된 ShotVerse-Bench 데이터셋과 Novel Calibration Pipeline을 통해 지원됩니다.
실험 결과는 ShotVerse의 우수한 성능을 입증합니다. Track A (Text-to-Trajectory) 평가에서, Planner 는 ShotVerse-Bench 에서 F1-Score 0.422 와 CLaTr-CLIP 35.016 를 달성하여, 가장 강력한 Autoregressive Baseline인 GenDoP ( F1-Score 0.343 , CLaTr-CLIP 33.875 )를 능가합니다
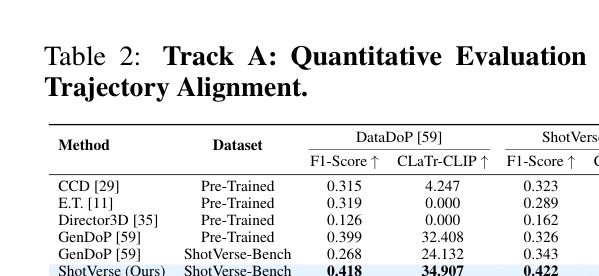 Table 2: Quantitative Evaluation of Text-Trajectory Alignment (Track A)
Table 2: Quantitative Evaluation of Text-Trajectory Alignment (Track A)
. Track B (Trajectory-to-Video) 평가에서, Controller 는 Transition Error 0.0163 , Rotation Error 0.73 로 가장 낮은 에러율을 보였으며, CAS(Coordinate Alignment Score) 는 0.500 으로 가장 높아 Cross-Shot Consistency가 우수함을 보여줍니다
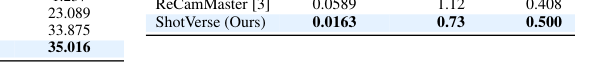 Table 3: Quantitative Evaluation of Camera Control (Track B)
Table 3: Quantitative Evaluation of Camera Control (Track B)
. Track C (Text-to-Video) 엔드투엔드 평가에서는 가장 낮은 FVD 281.71 와 가장 높은 Aesthetic Quality 5.465 를 기록하여, Open-Source 및 Commercial Baseline을 모두 뛰어넘었습니다. 특히 4D RoPE 는 Shot Transition Accuracy 를 0.933 로 끌어올리며 Shot Hierarchy를 효과적으로 처리함을 보였습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Cinematic Multi-Shot Video Generation 분야에서 데이터 중심적 패러다임 전환을 선도하며, High-Level Narrative Intent와 Low-Level Geometric Precision 사이의 간극을 효과적으로 메웠습니다. ShotVerse 는 "Plan-then-Control" 프레임워크와 ShotVerse-Bench 데이터셋, 그리고 새로운 Camera Calibration Pipeline을 통해 Multi-Shot Storytelling에 필요한 복잡한 공간 논리를 성공적으로 분리하고 해결했습니다. ShotVerse 는 State-of-the-Art 기술적 정확도를 달성할 뿐만 아니라, Cinematic Pacing 및 Visual Salience에 대한 깊이 있는 암묵적 이해를 보여주어, AI 기반 영화 제작 및 미래의 Professional Cinematographic Orchestration 분야에 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
- [논문리뷰] Selective Synergistic Learning for Video Object-Centric Learning
Review 의 다른글
- 이전글 [논문리뷰] One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
- 현재글 : [논문리뷰] ShotVerse: Advancing Cinematic Camera Control for Text-Driven Multi-Shot Video Creation
- 다음글 [논문리뷰] Spatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training
댓글