[논문리뷰] One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
링크: 논문 PDF로 바로 열기
저자: Moayed Haji-Ali, Willi Menapace, et al.
키워: Diffusion Transformers (DiTs), Latent Interfaces, Adaptive Computation, Multi-Budget Inference, Rectified Flow, Classifier-Free Guidance (CFG), Cheap Classifier-Free Guidance (CCFG)
1. Key Terms & Definitions (핵심 용어 및 정의)
- Elastic Latent Interface Transformer (ELIT) : 기존 Diffusion Transformers (DiTs) 에 통합되어 입력 이미지 크기와 컴퓨팅 비용을 분리하고, 가변 길이의 Latent Token 시퀀스를 통해 유연한 컴퓨팅 할당을 가능하게 하는 메커니즘.
- Diffusion Transformers (DiTs) : 고품질 이미지 및 비디오 생성을 위한 아키텍처로, 입력 해상도에 고정된 컴퓨팅 비용을 가지며 공간 토큰에 컴퓨팅을 균일하게 할당하는 경향이 있음.
- Rectified Flow (RF) : 본 연구에서 생성 모델을 훈련하기 위해 사용된, 노이즈 분포를 데이터 분포에 연결하는 결정론적 속도장을 학습하는 Flow Matching의 한 변형.
- Classifier-Free Guidance (CFG) : 확산 모델 샘플링에서 품질을 향상시키는 데 사용되는 핵심 기술로, 조건부 모델과 비조건부 모델을 함께 사용하여 예측 속도를 재정의함.
- Cheap Classifier-Free Guidance (CCFG) : ELIT 의 가변 Inference Budget 기능을 활용하여 비조건부 모델에 더 적은 컴퓨팅을 할당함으로써, CFG 의 품질 향상과 AutoGuidance (AG) 의 비용 효율성을 결합한 새로운 Guidance 메커니즘.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존 Diffusion Transformers (DiTs) 는 높은 생성 품질을 달성하지만, 컴퓨팅 비용이 입력 이미지 해상도에 고정되어 Latency-Quality Trade-off가 경직되어 있습니다. 또한, DiTs 는 컴퓨팅 자원을 입력 공간 토큰에 균일하게 할당하여 중요하지 않은 영역에 자원을 낭비하는 경향이 있습니다. 저자들은 실험을 통해 DiTs 가 zero-padded 영역에서 컴퓨팅을 효과적으로 활용하지 못하고 컴퓨팅이 낭비됨을 [Figure 2]를 통해 보여줍니다. 이러한 비효율성은 시각 정보가 불균일한 실제 이미지에서도 발생하여, 난이도에 따라 컴퓨팅을 동적으로 재분배하고 유연한 컴퓨팅 Budget을 제공할 수 있는 새로운 아키텍처의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 DiT 아키텍처의 한계를 극복하기 위해 Elastic Latent Interface Transformer (ELIT) 를 제안합니다
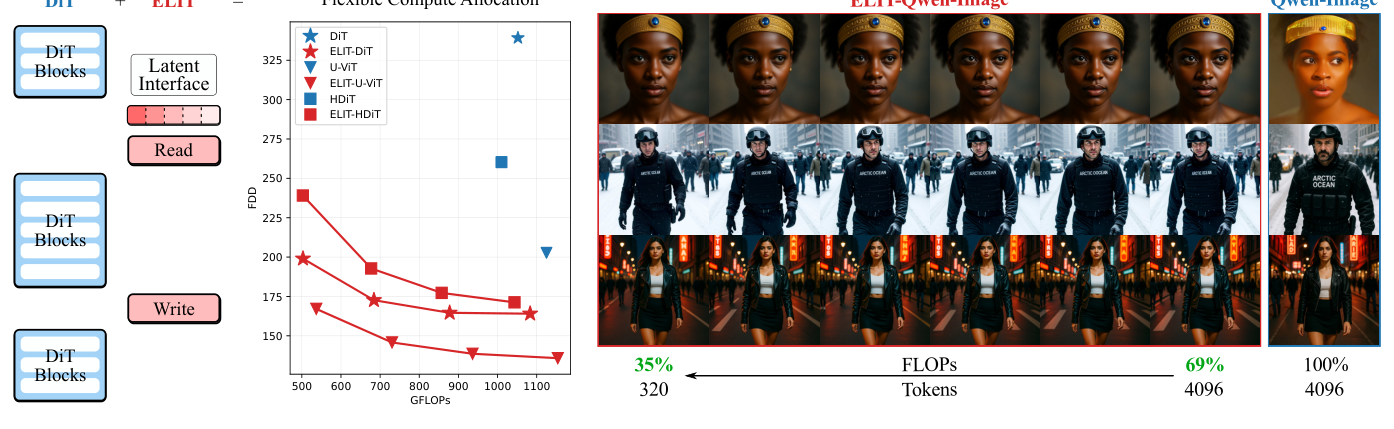 Figure 1: Flexible compute allocation with ELIT
Figure 1: Flexible compute allocation with ELIT
,
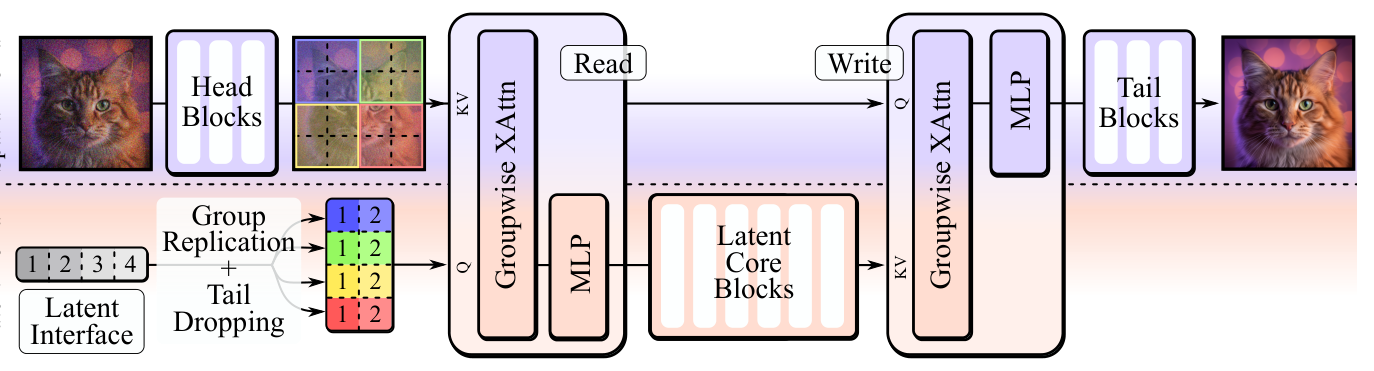 Figure 3: Architecture of ELIT
Figure 3: Architecture of ELIT
. ELIT 는 DiT 스택에 가변 길이의 Latent Token 시퀀스인 Latent Interface 와 두 개의 경량 Read 및 Write Cross-Attention Layer를 추가하는 드롭인(drop-in) 메커니즘입니다. Read Layer는 공간 토큰에서 Latent Interface로 정보를 가져오고, Write Layer는 업데이트된 Latent 상태를 다시 공간 토큰으로 브로드캐스트합니다. 훈련 시 Tail Latents 의 무작위 Drop을 통해 ELIT 는 중요도 순서로 정렬된 표현을 학습하여, Inference 시 Latent Token 수를 동적으로 조절하여 컴퓨팅 제약에 맞춰 품질-FLOPs Trade-off를 최적화할 수 있습니다. 주요 실험 결과로, ELIT MultiBudget (ELIT-MB) 는 ImageNet-1K 512px에서 DiT , U-ViT , HDiT 대비 모든 Metric에서 상당한 성능 향상을 보였습니다. 특히, DiT 대비 FID에서 40% , U-ViT 대비 14% , HDiT 대비 27% 감소를 달성했습니다
 Table 1: Comparative performance on ImageNet-1K at 256px and 512px resolutions
Table 1: Comparative performance on ImageNet-1K at 256px and 512px resolutions
. ELIT-DiT 는 또한 기존 DiT 보다 3.3배 에서 4.0배 빠른 수렴 속도를 보였습니다 [Figure 4]. 제안된 Cheap Classifier-Free Guidance (CCFG) 메커니즘은 전체 생성 비용을 약 33% 절감하면서도 품질을 향상시키며, DiT 대비 19% 더 나은 FID를 달성했습니다 [Figure 5].
4. Conclusion & Impact (결론 및 시사점)
이 연구는 Elastic Latent Interface Transformer (ELIT) 를 도입하여 Diffusion Transformers (DiTs) 의 컴퓨팅 할당을 개선하고 유연한 컴퓨팅 Budget을 가능하게 합니다. ELIT 는 경량 Read 및 Write Layer를 통해 동적으로 컴퓨팅을 재분배하고, Inference 시 Latent Token 수를 조절하여 탁월한 품질-컴퓨팅 Trade-off를 제공합니다. 이러한 접근 방식은 DiT , U-ViT , HDiT , MM-DiT 등 다양한 아키텍처에서 일관된 성능 향상을 보여주며, 특히 대규모 모델과 고해상도 이미지 생성에서 더욱 두드러집니다. ELIT 는 단일 모델로 다양한 Latency-Quality 요구사항을 충족할 수 있게 하여, 학계 및 산업계에서 Diffusion Model의 실제 적용 가능성을 크게 확장할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
- [논문리뷰] Selective Synergistic Learning for Video Object-Centric Learning
Review 의 다른글
- 이전글 [논문리뷰] OmniStream: Mastering Perception, Reconstruction and Action in Continuous Streams
- 현재글 : [논문리뷰] One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
- 다음글 [논문리뷰] ShotVerse: Advancing Cinematic Camera Control for Text-Driven Multi-Shot Video Creation
댓글