[논문리뷰] OmniStream: Mastering Perception, Reconstruction and Action in Continuous Streams
링크: 논문 PDF로 바로 열기
저자: Yibin Yan, Jilan Xu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- OmniStream : 이미지, 비디오, 3D 데이터를 포함한 다양한 시각 입력 스트림에서 인지, 재구성 및 행동을 수행하는 통합 streaming visual backbone 모델입니다.
- Causal Spatiotemporal Attention : 시간적 인과성(temporal causality)을 엄격하게 적용하여 과거 및 현재 프레임에만 의존하며, 지속적인 KV-cache 를 통해 효율적인 프레임별 온라인 추론을 가능하게 하는 메커니즘입니다.
- 3D Rotary Positional Embeddings (3D-ROPE) : 2D ROPE를 확장하여 시공간적 상대 인코딩을 제공하며, 모델이 긴 스트림에 걸쳐 '어디서-언제'에 대한 추론을 가능하게 합니다.
- Unified Multi-task Framework : 정적 및 시간적 표현 학습, 스트리밍 geometric reconstruction , vision-language alignment 세 가지 보완적인 목표를 결합하여 OmniStream 을 사전 학습시키는 방법론입니다.
- KV-cache : 이전 프레임의 Key(K) 및 Value(V) 벡터를 저장하여 현재 프레임의 Attention 계산 시 재사용함으로써, 과거 전체 스트림에 대한 재계산을 피하고 online processing 의 효율성을 높이는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
현대 visual agent는 로봇, AR 장치 등 실시간 스트리밍 환경에서 작동하기 위해 일반적이고, 인과적이며, 물리적으로 구조화된 표현을 요구합니다. 그러나 기존 vision foundation model은 image semantic perception , offline temporal modeling , spatial geometry 등 특정 task에 특화되어 파편화되어 있으며, 이는 단일하고 다재다능한 visual backbone의 부재로 이어집니다. 이러한 모델들은 대부분 좁은 목적(예: semantic invariances, temporal motion, spatial geometry)에 맞춰 학습되어, online, causal regime에서 static semantics , temporal dynamics , 3D structure 전반에 걸쳐 transfer하기 어렵습니다. 기존의 "unify" 노력은 주로 output 수준에서 이루어져 새로운 task에 대한 재학습, 재토큰화 또는 아키텍처 조정이 필요한 경우가 많았습니다. 본 연구는 이러한 한계를 극복하고, 단일 visual backbone이 다양한 downstream task를 지원하며 실시간 스트리밍 환경에서 효율적으로 작동할 수 있는 representation-centric 한 접근 방식을 제안합니다
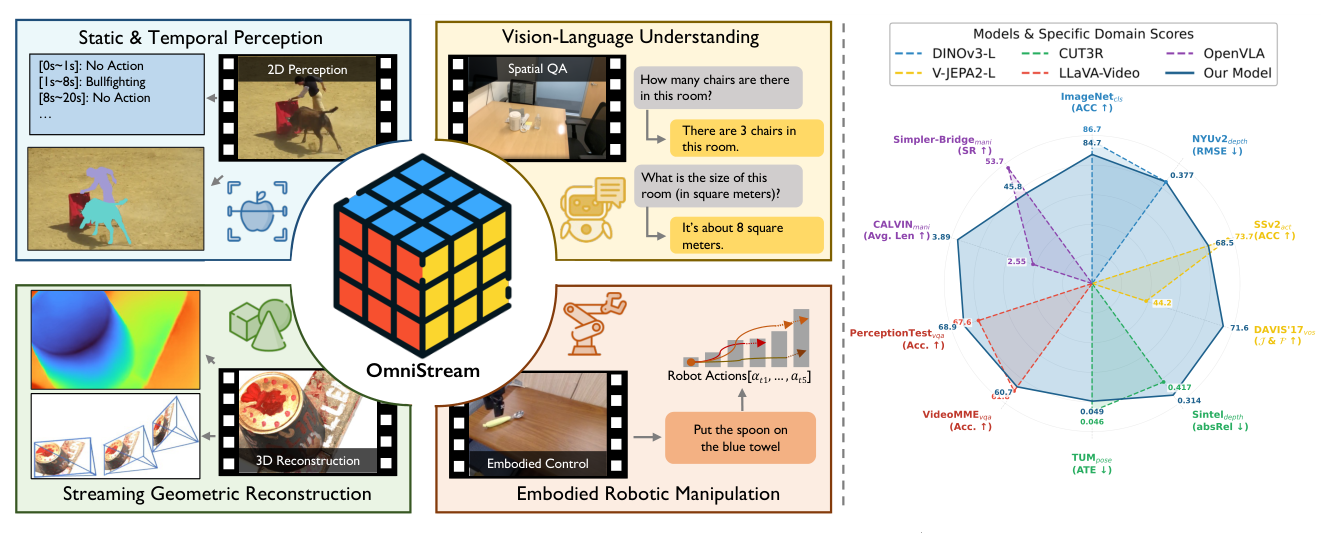 Figure 1: OmniStream supports a wide spectrum of tasks, including 2D/3D perception, vision-language understanding, and embodied robotic manipulation. Right: the frozen features of our single backbone achieve highly competitive or superior performance compared to leading domain-specific experts.
Figure 1: OmniStream supports a wide spectrum of tasks, including 2D/3D perception, vision-language understanding, and embodied robotic manipulation. Right: the frozen features of our single backbone achieve highly competitive or superior performance compared to leading domain-specific experts.
.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 강력한 사전 학습된 이미지 모델을 온라인, 시간적으로 인과적인 모델로 전환하는 OmniStream 을 제안합니다. 핵심 설계는 causal spatiotemporal attention 과 3D-ROPE 이며, 특히 persistent KV-cache 를 통해 효율적인 프레임별 추론을 지원합니다. OmniStream 은 29개 데이터셋 ( ~200M 프레임 )에 걸쳐 정적 및 시간적 표현 학습, 스트리밍 geometric reconstruction , vision-language alignment 를 결합한 synergistic multi-task framework 를 사용하여 사전 학습됩니다. 이 framework는 DINOv3-style student-teacher distillation , dual DPT 및 MLP camera head 를 통한 깊이 및 자세 예측, Qwen3-0.6B language decoder 를 통한 vision-language alignment 를 포함합니다.
평가 결과, OmniStream 은 strictly frozen backbone 상태에서도 경쟁 모델 대비 뛰어난 성능을 보입니다
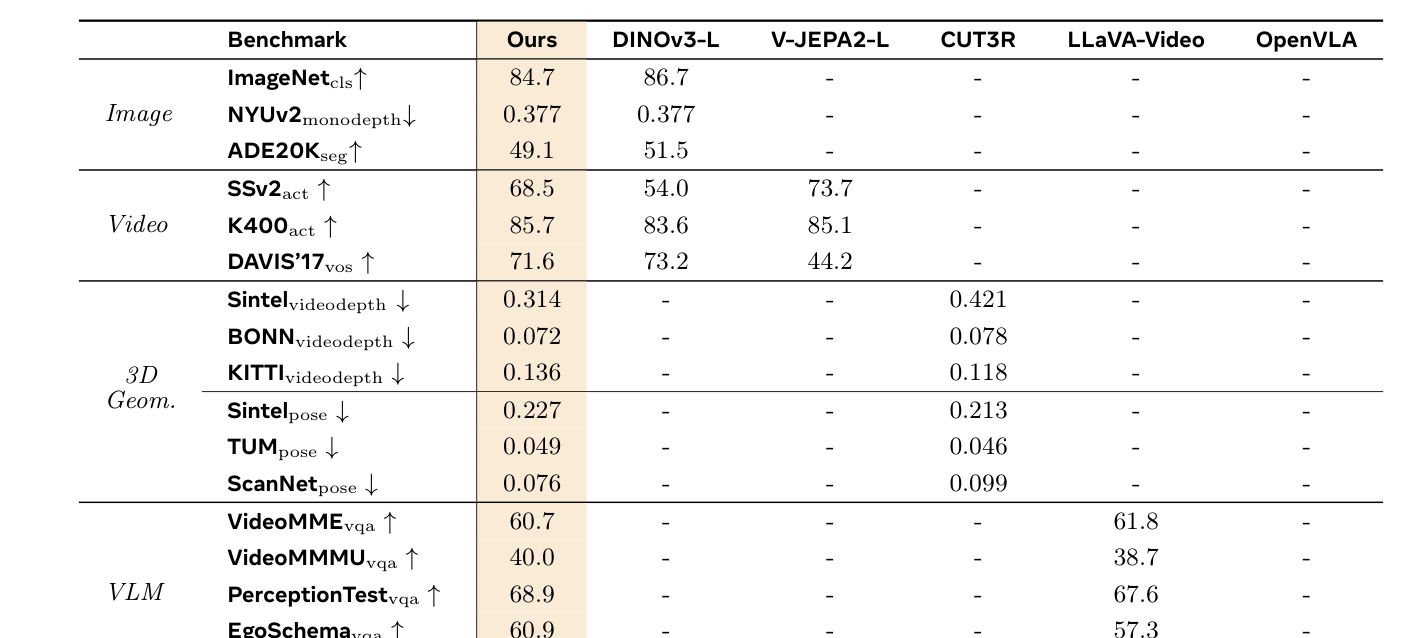 Table 2: Holistic evaluation. We compare OmniStream across 5 domains. Subscripts denote the specific task (i.e., cls: classification, monodepth: monocular depth estimation, seg: semantic segmentation, act: video action recognition, vos: video object segmentation, videodepth: video depth estimation, pose: camera pose estimation, vqa: visual question answering, mani: robotic manipulation). The evaluated metrics are ACC@1 for cls and act, RMSE for monodepth, mIOU for seg, J&F for vos, absRel for videodepth, ATE for pose, Accuracy (Acc.) for vqa, Average Length (Avg. Len) for CALVIN, and Success Rate (SR %) for Simpler-Bridge. Here, "-" indicates that a specialized baseline is not natively applicable to or lacks the capability for the given task.
Table 2: Holistic evaluation. We compare OmniStream across 5 domains. Subscripts denote the specific task (i.e., cls: classification, monodepth: monocular depth estimation, seg: semantic segmentation, act: video action recognition, vos: video object segmentation, videodepth: video depth estimation, pose: camera pose estimation, vqa: visual question answering, mani: robotic manipulation). The evaluated metrics are ACC@1 for cls and act, RMSE for monodepth, mIOU for seg, J&F for vos, absRel for videodepth, ATE for pose, Accuracy (Acc.) for vqa, Average Length (Avg. Len) for CALVIN, and Success Rate (SR %) for Simpler-Bridge. Here, "-" indicates that a specialized baseline is not natively applicable to or lacks the capability for the given task.
.
- Image & Video Probing : SSv2 데이터셋에서 DINOv3 의 54.0% 대비 68.5% 의 ACC@1 을, DAVIS'17 VOS 에서 V-JEPA 2 의 44.2% 대비 71.6% 의 J&F mean 을 달성하며 강력한 temporal understanding 능력을 입증했습니다.
- Streaming Geometric Reconstruction : Sintel, BONN, KITTI 등 벤치마크에서 online video depth estimation 및 camera pose estimation 에서 경쟁 또는 우월한 결과를 보였습니다. 3D-ROPE 덕분에 학습 시 T=16 프레임 으로 고정된 Temporal window에도 불구하고, 최대 110 프레임 까지 zero-shot length extrapolation 능력을 보여주었습니다.
- VLM & VLA Probing : VSI-Bench VQA 에서 LLaVA-Video 의 35.6% 대비 70.6% 의 Acc 를 기록했으며, 로봇 조작 벤치마크 CALVIN 에서 OpenVLA 의 2.55 대비 3.89 의 Avg. Len 을 달성하며 복잡한 spatial video question answering 및 로봇 조작 능력을 가능하게 했습니다.
- Inference Efficiency : persistent KV-cache 를 활용하여 T=64 에서 bi-directional recomputation 방식보다 15배 빠른 0.067초 의 Latency를 기록했으며, T=512 까지 linear memory growth 를 유지하여 OOM (Out-of-Memory) 을 방지합니다
 Table 9: Inference Efficiency with Varying Context Lengths. We report the per-frame latency (s) and peak VRAM (GB) for the T-th frame. Bi-di recomputes the entire sequence, while OmniStream uses a persistent KV-cache.
Table 9: Inference Efficiency with Varying Context Lengths. We report the per-frame latency (s) and peak VRAM (GB) for the T-th frame. Bi-di recomputes the entire sequence, while OmniStream uses a persistent KV-cache.
.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 causal spatiotemporal attention 과 3D-ROPE 를 통합한 OmniStream 을 제안하여, 단일하고 통합된 streaming visual backbone 이 가능함을 입증했습니다. OmniStream 은 다양한 데이터셋에 대한 multi-task training 을 통해 image/video probing , streaming geometric reconstruction , VLM 및 VLA 와 같은 광범위한 task에서 strictly frozen backbone 상태로 경쟁력 있는 성능을 달성합니다. 이는 semantic , spatial , temporal reasoning 전반에 걸쳐 일반화되는 단일 vision backbone의 실현 가능성을 보여주며, benchmark-specific dominance 보다는 versatile vision backbone 의 구축이 general-purpose visual understanding 을 위한 더 의미 있는 진전임을 시사합니다. OmniStream 은 인터랙티브하고 embodied agent 를 위한 시각 인지 분야에 견고한 토대를 마련할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
- [논문리뷰] Selective Synergistic Learning for Video Object-Centric Learning
Review 의 다른글
- 이전글 [논문리뷰] Mobile-GS: Real-time Gaussian Splatting for Mobile Devices
- 현재글 : [논문리뷰] OmniStream: Mastering Perception, Reconstruction and Action in Continuous Streams
- 다음글 [논문리뷰] One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
댓글