[논문리뷰] Skill-3D: Evolving Scene-Aware Skills for Agentic 3D Spatial Reasoning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haoyuan Li, Zhengdong Hu, Jun Wang, Hehe Fan, Yi Yang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic 3D Spatial Reasoning: MLLM 에이전트가 외부 툴(Tool)을 활용하여 실내 3D 환경의 기하학적, 공간적 정보를 파악하고 추론하는 패러다임.
- Scene Memory: 다양한 3D 장면에서 수집된 에이전트의 툴 사용 궤적(Trajectory), 성공 사례, 실패 원인 등을 기록하여 축적하는 저장소.
- Skill Library: Scene Memory로부터 성공적인 궤적을 증류(Distill)하여 생성한 재사용 가능한 장면 인지적 기술(Skill)들의 집합.
- Effective Tool Usage (ETU): 에이전트가 호출한 툴 중 실제 유효한 증거를 제공하고 추론 과정에 반영된 비율을 측정하는 성능 지표.
- Group Relative Policy Optimization (GRPO): 에이전트의 정책을 최적화하기 위해, 다수의 샘플링된 궤적 간의 상대적 보상을 기반으로 학습하는 RL 기법.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 MLLM 기반 에이전트들이 3D 공간 추론 작업에서 장면의 특성을 무시하고 획일적인 툴 사용 전략을 취함으로써 성능이 저하되는 문제를 해결하고자 한다. [Figure 1] 기존의 접근 방식은 다양한 3D 실내 환경에서 요구되는 제각각의 기하학적 증거와 무관하게 특정 툴(예: Object Detection)만을 선호하는 편향성을 보인다. 이러한 장면 무관적(Scene-agnostic) 전략은 결과적으로 툴 사용의 잠재력을 충분히 활용하지 못하게 하며, 이는 복잡한 3D 공간 추론 작업에서 에이전트 성능의 정체로 이어진다. 따라서 장면에 따라 적절한 툴을 선택하고 활용할 수 있는 가변적인 기술 기반의 추론 프레임워크가 필수적이다. [Figure 1]
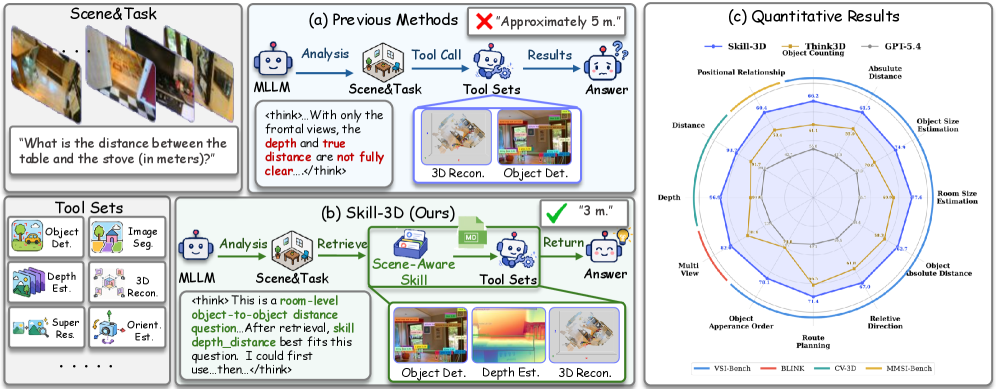
Figure 1 — Skill-3D 개요 및 동기
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Skill-3D라는 프레임워크를 제안하여 에이전트에게 재사용 가능한 장면 인지적 기술을 학습시키고 진화시킨다. [Figure 2] 이 프레임워크는 Scene Memory에 기록된 에이전트의 수행 기록을 바탕으로 성공적인 툴 사용 패턴을 Skill Library로 증류하고, 실패한 케이스는 교훈(Lessons)으로 학습하는 루프를 통해 지속적으로 기술을 발전시킨다. 학습 단계에서는 Agentic Supervised Fine-Tuning (SFT)을 통해 기술 선택 및 툴 활용의 기초를 다지고, GRPO를 이용한 skill-guided agentic post-training을 수행하여 에이전트가 복합 보상(정답률, 툴 효율성, 구조적 준수)을 극대화하도록 최적화한다. [Figure 2]
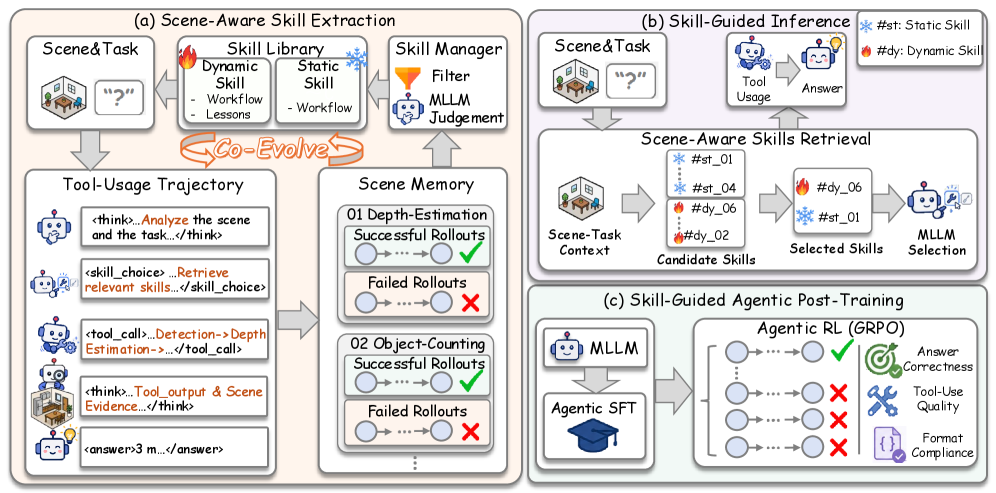
Figure 2 — Skill-3D 프레임워크 아키텍처
실험 결과, Skill-3D는 다양한 벤치마크에서 기존 에이전트 모델 대비 압도적인 성능 향상을 보였다. 특히 VSI-Bench에서 효과적인 툴 사용(ETU) 비율이 기존 39%에서 78%로 대폭 개선되었다. [Figure 3] 성능 측면에서 Gemini-3-Flash 모델은 MMSI-Bench에서 67%, Qwen3-VL-8B 모델은 VSI-Bench에서 43%의 상당한 성능 향상을 기록하였다. [Table 1], [Table 2] 이는 Skill-3D가 단순히 툴 사용 빈도를 늘리는 것이 아니라, 장면의 컨텍스트에 맞춰 가장 관련성이 높은 툴을 정확히 선택하도록 유도함을 의미한다. [Figure 4]

Figure 3 — 효과적인 툴 사용(ETU) 성능 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 3D 공간 추론의 복잡성을 해결하기 위해 장면 인지적 기술의 상호 진화(Co-evolution)를 활용하는 Skill-3D 프레임워크를 성공적으로 구축하였다. 이 연구는 에이전트가 고정된 툴 사용 방식에서 벗어나, 데이터로부터 스스로 학습하고 개선하는 기술 라이브러리를 통해 적응형 추론을 수행할 수 있음을 보여주었다. 본 프레임워크는 MLLM 기반 에이전트의 3D 공간 이해 능력을 실질적으로 향상시켰으며, 향후 복잡한 물리적 환경에서 정밀한 지능형 에이전트를 개발하는 데 중요한 기반을 제공할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Tool-Augmented Spatiotemporal Reasoning for Streamlining Video Question Answering Task
- [논문리뷰] Explain Before You Answer: A Survey on Compositional Visual Reasoning
- [논문리뷰] ToolSense: A Diagnostic Framework for Auditing Parametric Tool Knowledge in LLMs
- [논문리뷰] Bayesian-Agent: Posterior-Guided Skill Evolution for LLM Agent Harnesses
- [논문리뷰] OpenSkill: Open-World Self-Evolution for LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] SigmaScale: LLM Compression with SVD-based Low-Rank Decomposition and Learned Scaling Matrices
- 현재글 : [논문리뷰] Skill-3D: Evolving Scene-Aware Skills for Agentic 3D Spatial Reasoning
- 다음글 [논문리뷰] Skill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
댓글