[논문리뷰] Reinforcement Learning from Rich Feedback with Distributional DAgger
링크: 논문 PDF로 바로 열기
저자: Rishabh Agrawal, Jacob Fein-Ashley, Paria Rashidinejad, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning from Verifiable Rewards): 최종 결과의 정답 여부만을 확인하는 1비트의 희소한 보상 신호를 사용하여 모델을 학습시키는 기존의 강화학습 패러다임입니다.
- On-policy Self-Distillation: 현재 모델의 출력을 피드백으로 조건화하여 이를 teacher로 삼고, student 모델이 이 teacher의 분포를 모방하도록 학습하는 기법입니다.
- DistIL: 본 논문에서 제안하는 알고리즘으로, DAgger 프레임워크를 기반으로 하며 Forward cross-entropy 목적 함수를 통해 monotonic policy improvement와 future-aware credit assignment를 보장합니다.
- Future-aware Credit Assignment: 특정 시점의 토큰 선택이 미래의 상태 분포에 미치는 영향을 고려하여 신용 할당(credit assignment)을 수행하는 메커니즘입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 기존의 RLVR 패러다임이 가진 극심한 희소 보상 문제와 그에 따른 부적절한 신용 할당 문제를 해결하고자 합니다. 기존의 on-policy self-distillation 방법들은 f-divergence 기반의 손실 함수를 사용하는데, 이러한 목적 함수는 teacher가 student보다 우월하더라도 monotonic policy improvement를 보장하지 못하며 오히려 성능을 저하시킬 수 있습니다. 또한, 기존 방법들은 토큰 수준의 local gradient 근사만을 사용하여, 초기 토큰 선택이 이후의 추론 과정에 미치는 장기적인 영향을 무시함으로써 최적화가 정체되거나 suboptimal 정책으로 수렴하는 근본적인 한계를 가지고 있습니다. [Figure 1]에서 확인할 수 있듯이, 기존 방법인 SDPO는 학습 과정에서 불안정한 성능 지표를 보이며, 이는 명확한 방법론적 개선의 필요성을 시사합니다.
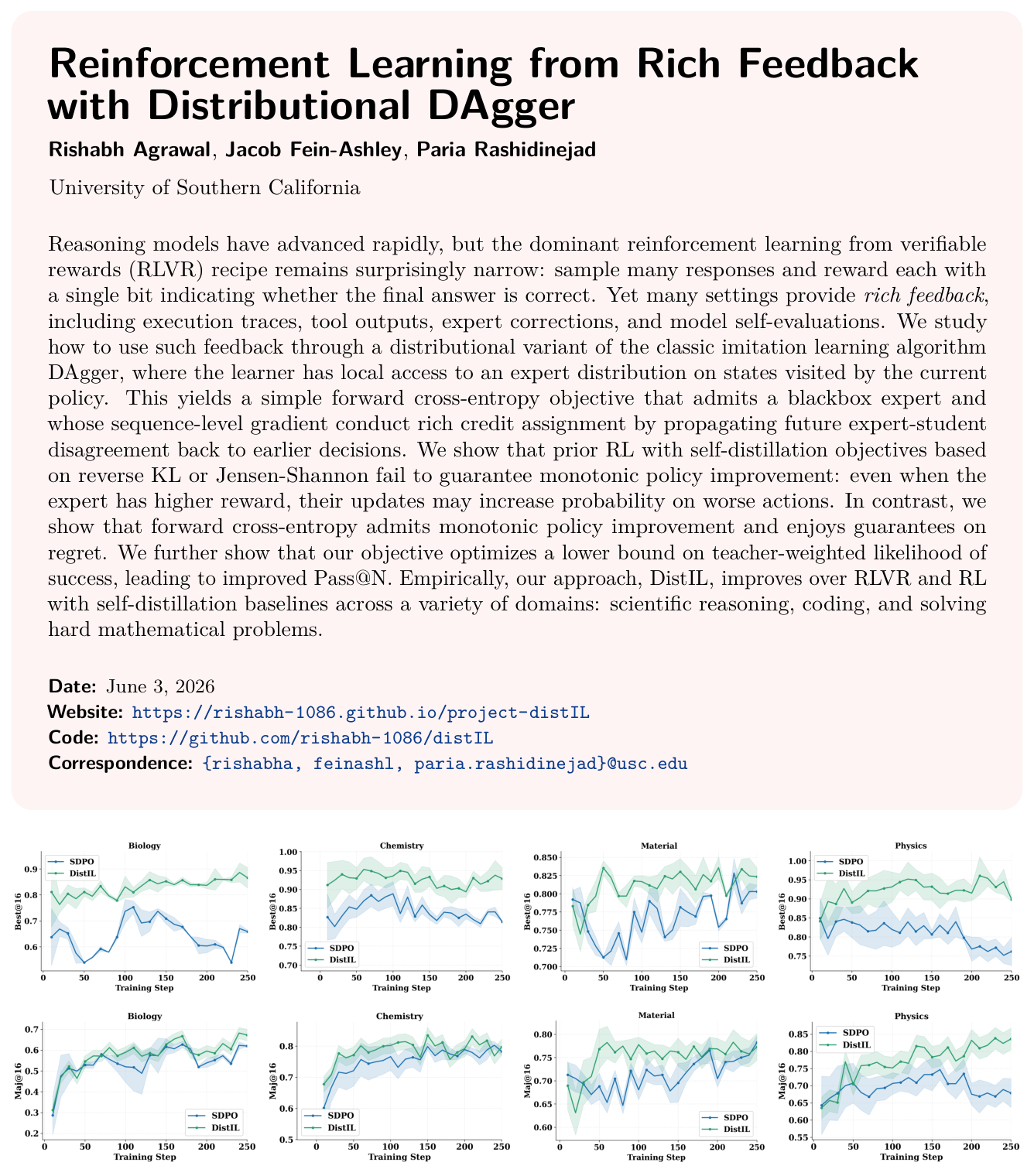
Figure 1 — SDPO와 DistIL의 학습 안정성 및 성능 비교 그래프
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 DAgger 기반의 분포적 모방 학습 알고리즘인 DistIL을 제안하여, teacher가 직접 제공하는 분포를 student가 직접 모방하도록 설계함으로써 보상 정렬(reward alignment)과 monotonic improvement를 달성합니다. DistIL은 Forward cross-entropy 손실 함수를 사용하여 teacher의 확률에 가중치를 둔 로컬 모방과, 미래의 teacher-student 불일치를 현재의 의사결정에 반영하는 future-aware credit assignment를 동시에 수행합니다. 실험 결과, DistIL은 과학적 추론(SciKnowEval), 코딩(LCBv6), 그리고 수학적 문제 해결을 포함한 다양한 도메인에서 SDPO, OPSD, GRPO 등의 베이스라인을 압도하는 성능을 보였습니다. 특히 과학적 추론 도메인에서 Qwen3-8B 모델을 사용했을 때, DistIL은 5시간 학습 기준 평균 성능에서 76.1을 기록하여 SDPO(73.0) 및 GRPO(71.1) 대비 유의미한 성능 향상을 입증하였습니다. [Table 1]은 이러한 실험적 우위를 수치적으로 명확히 보여줍니다.
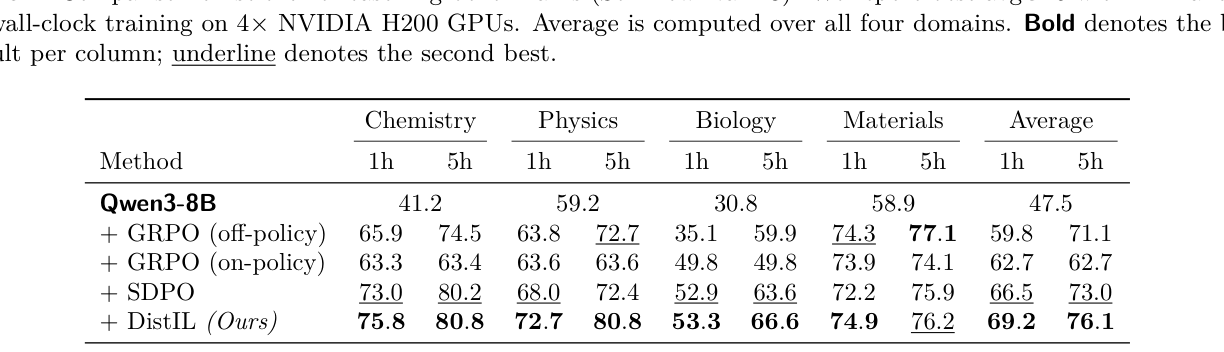
Table 1 — 다양한 과학적 추론 벤치마크에서의 DistIL과 베이스라인 알고리즘들의 1시간/5시간 성능 비교 데이터
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 rich feedback을 활용한 강화학습이 단순한 보상 극대화를 넘어, 분포적 모방 학습(distributional imitation learning)을 통해 보다 안정적이고 이론적으로 보장된 성능 향상을 이룰 수 있음을 입증했습니다. 특히 제안된 DistIL 알고리즘은 monotonic policy improvement와 sublinear regret을 보장하며, 복잡한 추론 과정에서 토큰 수준의 로컬 최적화가 갖는 한계를 극복했습니다. 이 연구는 LLM의 추론 성능을 향상시키는 과정에서 피드백의 질을 극대화하고 신용 할당 문제를 해결하는 표준적인 방법론을 제시함으로써 향후 AI 모델의 추론 능력 향상 및 정렬 연구에 중요한 기술적 이정표가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Reinforcement Learning via Self-Distillation
- [논문리뷰] CEPO: RLVR Self-Distillation using Contrastive Evidence Policy Optimization
- [논문리뷰] Self-Distilled RLVR
- [논문리뷰] FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
- [논문리뷰] Hindsight Credit Assignment for Long-Horizon LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] Physics in 2-Steps: Locking Motion Priors Before Visual Refinement Erases Them
- 현재글 : [논문리뷰] Reinforcement Learning from Rich Feedback with Distributional DAgger
- 다음글 [논문리뷰] Robots Need More than VLA and World Models
댓글